
Happy Teams Build Better Products
6 lessons every engineer eventually learns the hard way.

If you’ve ever worked in a startup, you know how fast things can fall apart behind the scenes.
A customer reports an issue.
Support files a vague ticket.
Engineering tries to reproduce it.
Frontend blames backend.
Backend blames frontend.
Slack threads explode.
Everyone’s busy, but somehow, nobody actually knows what’s going on.
I used to live inside this loop for years.
And here’s what hit me:
The problem wasn’t the customer. It wasn’t the product.
The real issues was the team system itself.
If a team doesn’t have clarity, context, or energy…then nothing works.
It doesn’t matter how strong your architecture is; tired people ship tired products.
This realization forced me to rethink how teams actually build and debug software.
And it led me to six lessons I wish I’d learned sooner.
1. Context is everything
The root cause of most engineering pain is simple:
No one knows what actually happened.
Support writes:
“Checkout is slow.”
Engineering responds:
“Works for me.”
And both are right, because neither has the full story.
Once I started forcing myself (and my teams) to capture the full context once and make it travel with the issue, everything changed.
A good bug report includes:
real repro steps
real environment
a timestamp
screenshots or (ideally) a replay
the trace or request ID
This alone removed hours of back-and-forth from every incident.
And the surprising thing?
It also reduced tension between teams.
Clarity is the best stress relief.
2. Replays beat meetings
Eventually, I realized how many meetings existed only because someone in the chain was missing context.
“Let’s jump on a call.”
Translation: “I don’t know what happened, please walk me through it slowly.”
A replay solved that in 10 seconds.
No storytelling.
No guessing.
No back-and-forth.
Just: “Watch this. Let’s fix it.”
This single shift cut a ridiculous number of meetings.
And when you remove unnecessary meetings, you protect the thing teams need most: ENERGY.
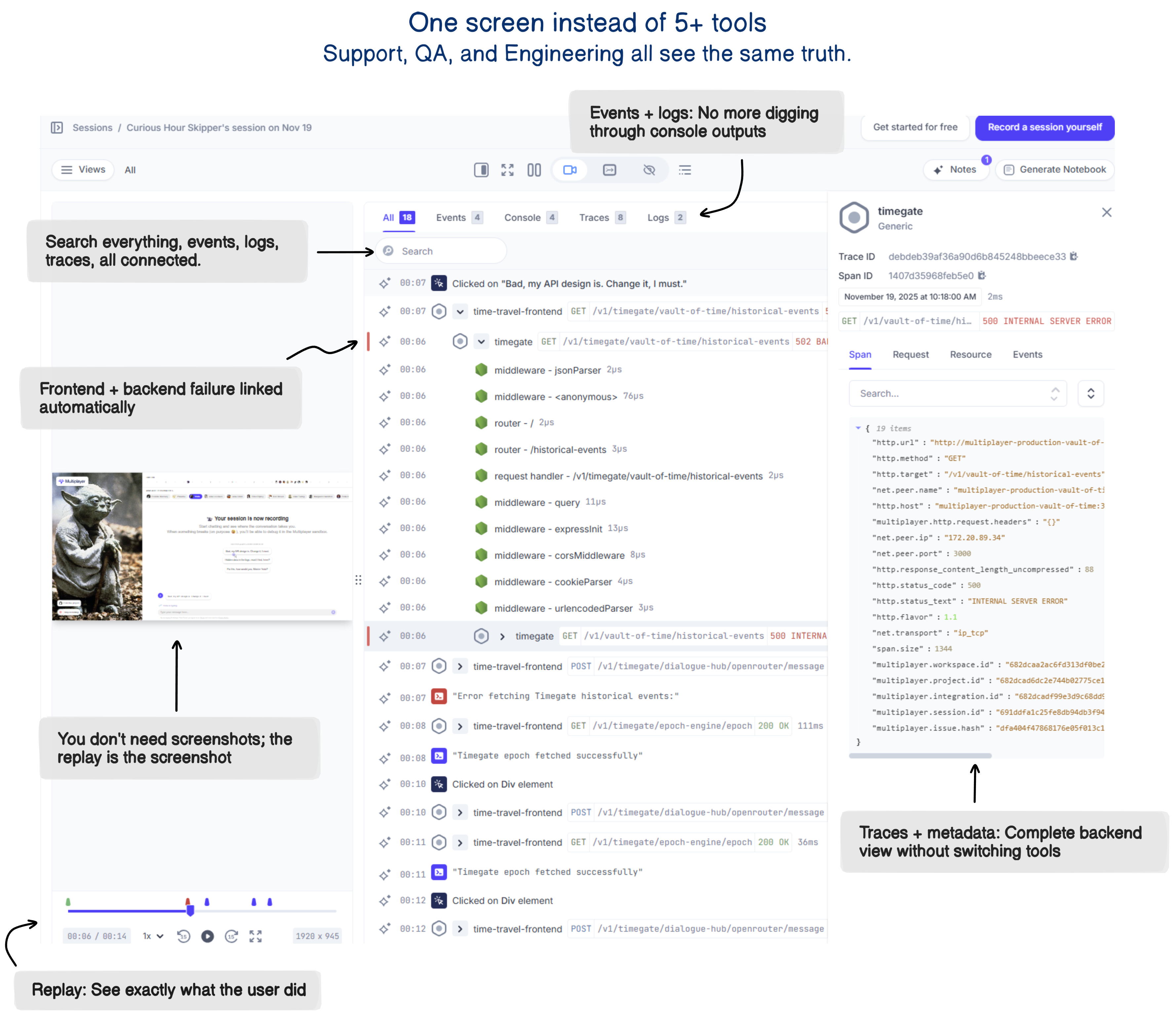
3. Too many tools destroy focus
Another lesson: even if you have the right data, it’s hard to use when it lives in four different places.
That was my life for years:
Replay in one tab.
Logs in another.
Traces in a third.
Metrics somewhere else.
By the time I pieced everything together, my brain was fried.
The real problem was that the debugging context lived across too many places.
The fix was simple:
put all the technical signals in one place so everyone sees the same thing.
Not fewer tools.
Just fewer places to hunt for the truth.
One path from “user clicked something” → “database wrote something.”
When the team stops switching tools, they start solving problems.
4. Automate the boring parts (the steps after debugging)
Once we know what broke, there’s a second phase: reproduce the bug reliably, run API calls, build integration tests, document edge cases, verify fixes. That’s where the manual cost really piles up.
That’s when a Notebook becomes handy, you can automate that second phase:
Convert a session recording into a reproducible test or script.
Sequence API calls or backend interactions exactly as they occurred, with real data, payloads, headers, and timing.
Annotate, document, and version the flow so teammates, devs, QA, PMs, can see exactly what happened and how it was tested.
Something like this:
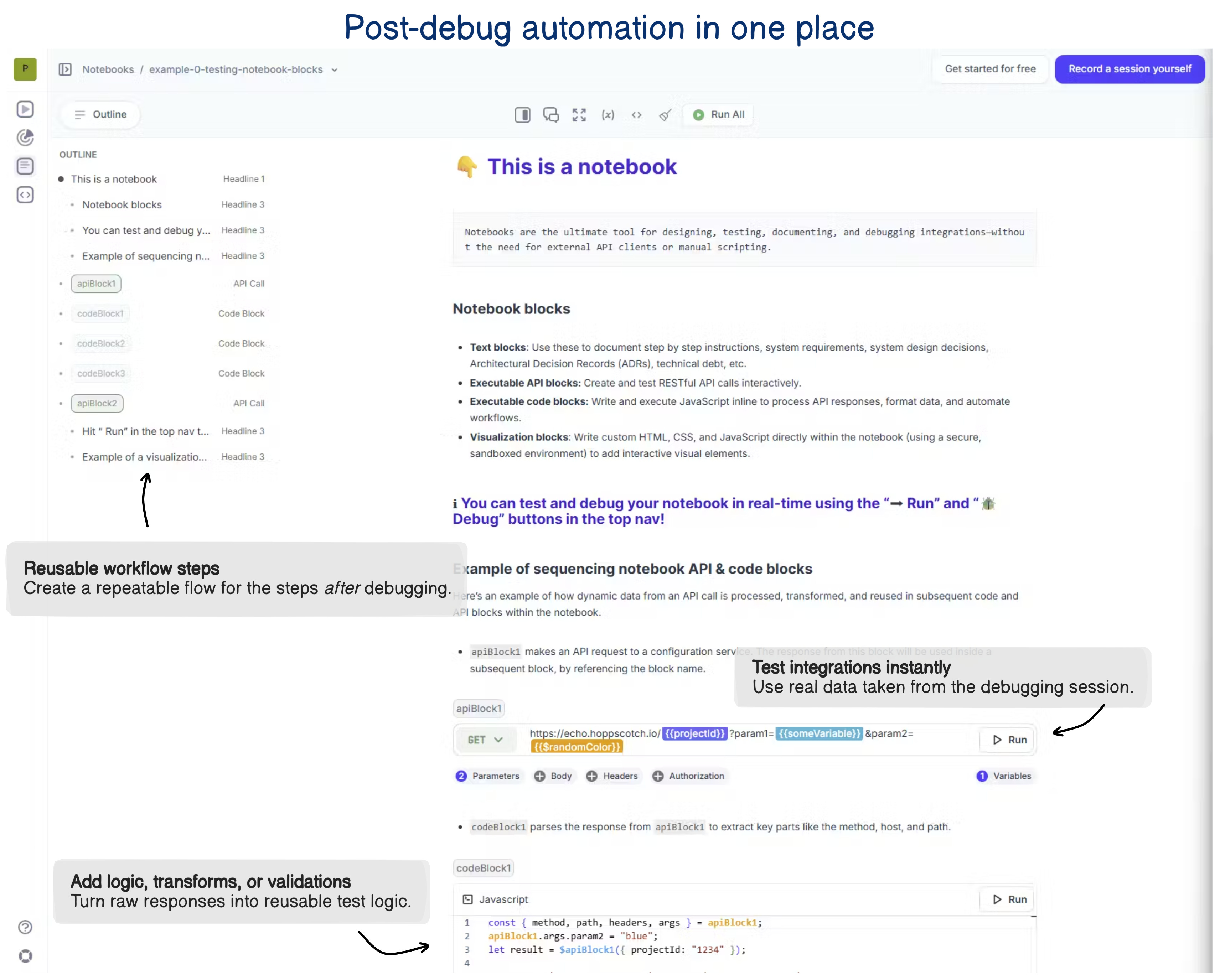
So debugging stays where it belongs, in the replay.
But all the follow-up steps, test scripts, documentation, and regression checks become automatic, repeatable, and shareable.
Simple result: way less repetition, way more time saved.
5. Energy is a system constraint
Startups obsess over uptime, latency, and error budgets.
But the thing that brings teams down isn’t CPU or RAM, it’s human bandwidth.
I saw it repeatedly: burned-out engineers write worse code, fix bugs slower, communicate poorly, and lose patience with customers.
None of that shows up on a dashboard, but you feel it everywhere in the system.
You can’t build great products with exhausted people.
Once I started treating team energy as an actual engineering constraint (not a “soft” idea), everything changed. Delivery became more predictable. PR quality went up. On-call incidents felt less chaotic. And the product itself noticeably improved.
One practical change made an outsized impact:
We implemented flow blocks.
Every engineer had protected windows where they could actually think:
2-hour focused work blocks
no Slack
no meetings
no pings
no “quick questions”
Protecting even one real flow block a day dramatically boosted output without increasing hours worked.
It gave people breathing room, restored cognitive bandwidth, and reduced the constant context switching that quietly drains teams.
Happy teams don’t happen by accident, you have to design your workflow to protect their energy.
And when you do, the quality of the product rises with it.
6. Problems get solved faster together
The last lesson was the most human: silos kill speed.

I watched this pattern over and over again, support sees one piece, frontend sees another, backend sees something completely different, and QA is working off a reproduction that doesn’t match what actually happened.
Everyone is smart.
Everyone is trying.
But everyone is solving a different version of the problem.
When teams don’t share context, they don’t share reality.
The turning point came when we made sure everyone, support, QA, frontend, backend, worked from the same source of truth.
Not notes.
Not Slack threads.
Not assumptions.
A single replay.
A single timeline.
A single root cause.
Once that happened, alignment was instant.
Speculation disappeared.
People stopped “defending their part of the system” and started solving the actual issue.
Shared context creates shared ownership.
And shared ownership is the fastest path to a real fix.
It sounds simple, but it’s the closest thing I’ve found to a productivity multiplier.
One tool that enables all of this: Multiplayer

Multiplayer gives your team a single place where the full story of an issue is captured automatically.
It records user actions, frontend state, network calls, backend traces, logs, and request/response data, all stitched into one connected timeline:
No tool-hopping.
No reconstructing.
No missing context.
It supports quick on-demand captures, continuous recording for hard bugs, and an upcoming conditional mode for issues users never report.
It also gives your AI tools the context they need to generate accurate fixes, tests, and explanations, not guesses.
The result is simple:
less friction, less context switching, and fewer interruptions.
More clarity, more focus, and more calm.
My Takeaways
The longer I build software, the more obvious it becomes:
you can’t brute-force your way to great products.
You can push harder, add more meetings, and throw more people at a problem, but if the team doesn’t have clarity, focus, or energy, everything eventually slows down.
Most of the failures I’ve seen weren’t caused by a lack of talent.
They came from teams trying to build in an environment that worked against them:
too many tools, scattered context, constant interruptions, and workflows that drained more energy than the actual engineering work.
And that’s why the tools we choose matter.
Not because tools “fix culture,” but because they quietly shape the day-to-day reality of the team:
whether debugging takes minutes or hours
whether context stays intact or gets lost in handoffs
whether people get real flow time or live inside Slack
whether collaboration feels natural or forced
A good tool reduces friction.
A good workflow protects energy.
And when the environment supports the team instead of fighting them, everything gets easier; product quality, delivery speed, even customer outcomes.
Happy teams build better products.
And better products make happier customers.
You don’t get that by pushing harder.
You get it by designing the system, including your tools, to help the team do their best work.
Until next time,
— Raul
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a paid subscriber.
Developer experience makes a team more productive directly making the employees happy. If employees are happy, they ship faster and better products.