
What’s an event and what should be inside?
Event-driven communication is odd compared to request-response calls.

Event-driven architecture (EDA) works differently from the usual request-response model in microservices.
Instead of one service telling another what to do, a microservice emits an Event—a signal that something happened—and other services can decide whether to respond.
This approach has many benefits, but it also raises questions, especially about what information should go into an event.
Let’s break this down with an example. Imagine we have these microservices:
Orders Microservice: Handles customer orders.
Shipping Microservice: Manages shipping items.
Notifications Microservice: Sends updates to customers.
Thank you to our sponsors who keep this newsletter free:
Multiplayer auto-documents your system, from the high-level logical architecture down to the individual components, APIs, dependencies, and environments. Perfect for teams looking to streamline system design and documentation management without the manual overhead.
When a customer places an order, the Orders Microservice emits an “order placed” event. The Shipping Microservice picks up this event and starts processing the items, while the Notifications Microservice sends an email to the customer.
But what should be inside the event?
There are two main approaches here:
1-Just an Identifier

One option is for the event to contain only a simple identifier, like an order_id.
In this case, the Shipping and Notifications services need to call the Orders service to get all the details about the order. This approach has significant drawbacks:
Domain Coupling: Each subscriber (like Shipping or Notifications) needs to know about the Orders domain to request the details. This adds coupling between services, which reduces flexibility.
Multiple Calls: When more than one service subscribes to an event, each one has to make a separate request to the Orders service. This increases the load and can create bottlenecks, especially as the number of subscribers grows.
2- Fully Detailed Events
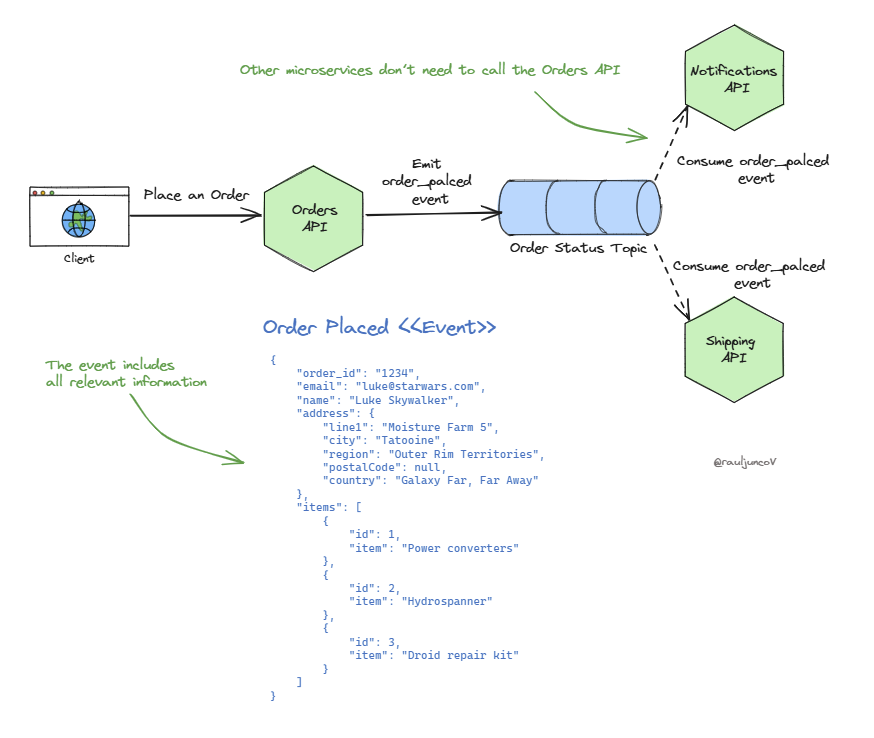
Another approach is to emit fully detailed events.
This means including all the information that any subscriber might need in the event itself. For example, if the Notifications Microservice needs the customer’s email address, why not just put that in the event?
Here’s why fully detailed events can be powerful:
Reduced Coupling: By including all relevant information, other microservices don’t need to call the Orders service. The Shipping and Notifications services can operate independently without needing extra calls.
Scalability: Detailed events reduce the number of network calls. Imagine ten different services that need order details—with a detailed event, all ten services can respond without repeatedly querying Orders.
Historical Record: Fully detailed events can also serve as an audit trail. They document exactly what happened at a specific time, which helps with debugging or analytics.
Fully Detailed Events seems to be winning, but here come the trade-offs.
Event Size Limitations: Event brokers like Kafka or RabbitMQ have limits on message sizes. If an event gets too large, it could cause issues. You need to balance what goes in the event to keep it manageable.
Schema Evolution: Including detailed information makes your event schema a contract with all consumers. Changes to the schema must be backward compatible to avoid breaking existing consumers. This needs careful planning and possibly a versioning strategy to evolve schemas smoothly.
Data Redundancy: Including detailed information might lead to data redundancy across services. Redundancy isn’t always bad (it’s the price of decoupling), but it means that the same data exists in multiple places, which raises questions about synchronization.
My Preferred Approach
In most situations, I prefer fully detailed events, especially when the event data is static and easy to share via a standard API. If I would let a request-response API return certain data, I see no problem including the same data directly in an event.
This approach reduces network overhead and ensures that services can work independently.
Extra Best Practices
Use a standardized event structure across your system to ensure consistency and ease of processing.
Consider using an event schema registry to manage and version your event schemas, which can help with schema evolution challenges.
Implement event sourcing where appropriate, which can provide a complete audit trail and enable event replay for debugging or analytics.
Design your events to be as self-contained as possible, including all necessary information for consumers to process the event without additional calls.
Wrapping up
Fully detailed events reduce domain coupling and cut down on the number of calls across microservices.
Including detailed information in events gives services more autonomy, which aligns with the principles of microservice architecture.
Trade-offs like event size, schema evolution, and data redundancy need careful attention to avoid problems.
Data should flow freely in a well-designed system.
Events should be the carriers of autonomy, not the chains of dependency.
What’s your take on this?
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Articles I enjoyed this week
The Journey of a SQL Query Through a Database by Saurabh Dashora
How to Generate Unique IDs in Distributed Systems by Ashish Pratap Singh
7 practical tips on performance optimizations in React applications by Petar Ivanov
Thank you for reading System Design Classroom. If you like this post, share it with your friends!
Great post Raul.
I also prefer having the complete payload as part of the event. One case where we just gave the identifier was when we were interfacing with a third-party external app and there were some compliance matters involved in handing over all the data directly in the event.
Also, thanks for the mention!
I've been working on an Event-Driven System for the last year and I can't say how interesting it was. As with everything in Software Engineering, it has its pros and cons. One of the biggest benefits is the amount of decoupling between different services it gives.
Awesome post Raul! 🙌