
What if this happens twice?
The Painful Truth About Retries, Replays, And The Myth Of Perfect Delivery.

No one wants to create duplicate messages. But somehow they crop up anyway.
Messages can be retried by the producer, redelivered by the broker, or replayed manually. Each component, from the network to the consumer, has a chance to accidentally deliver the same event twice.
And unless you're prepared for that, the consequences aren't just annoying; they're dangerous.
A wallet might be credited twice. An order might be fulfilled twice. A customer might get charged more than once.
Deduplication isn't just a nice-to-have. It's survival logic.
Real-World Failure
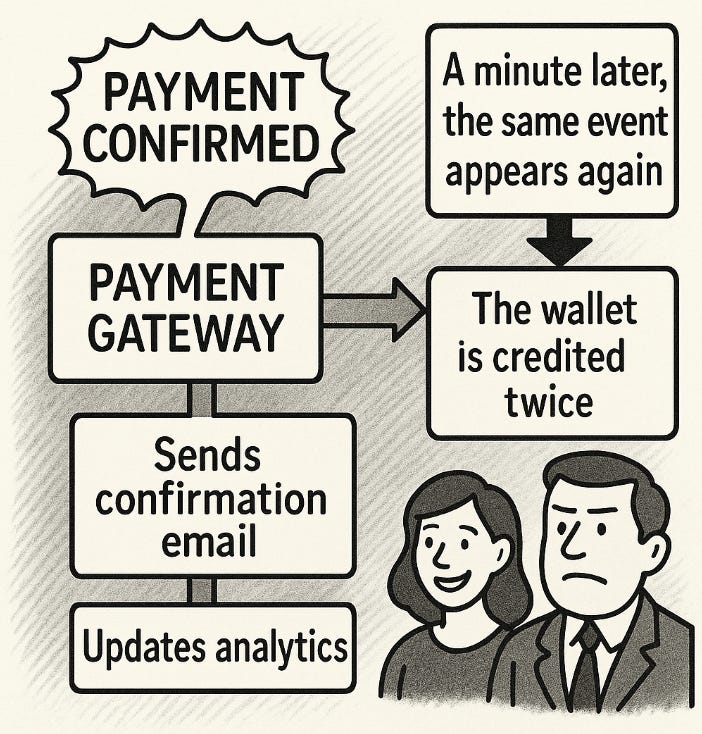
A payment gateway receives an event: "Payment Confirmed."
It credits the user's wallet, sends a confirmation email, and updates analytics. A minute later, the same event appears again.
The wallet is credited twice.
The customer is happy. The company takes the loss.
This happens more often than expected, and not just in payments.
What’s at Stake?
Distributed systems favor availability over consistency. That trade introduces:
Retries.
Replays.
Duplicate API calls.
Consumer crashes and reprocessing.
Ignore duplication, and you risk:
Overcharging customers.
Spamming users with repeated messages.
Skewed analytics.
Corrupted data.
Your system must expect duplicates. One retry can break everything.
Now that we've seen why duplication matters, let's look at how it happens in real systems.
How Duplication Happens

Duplication is inevitable, but it doesn't have to be fatal. There are many places where you can stop duplicates before they can do damage.
Where Can Deduplication Happen?
Duplication can be handled at the producer, consumer, or broker.
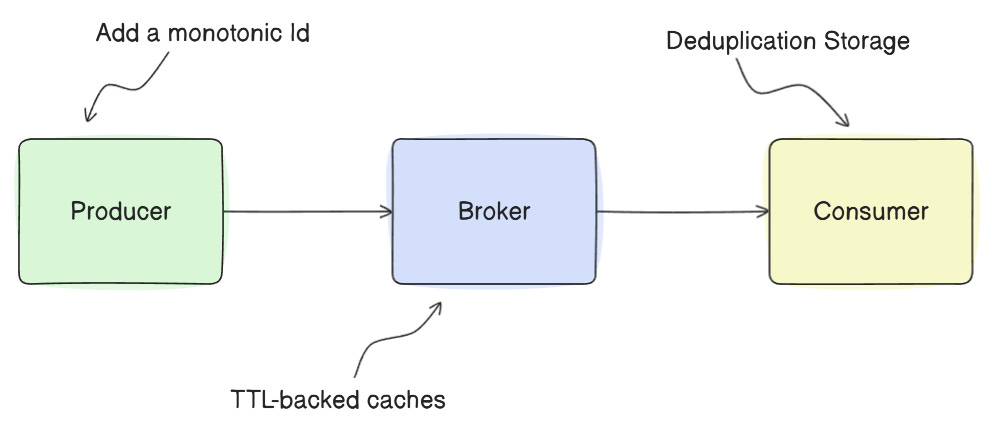
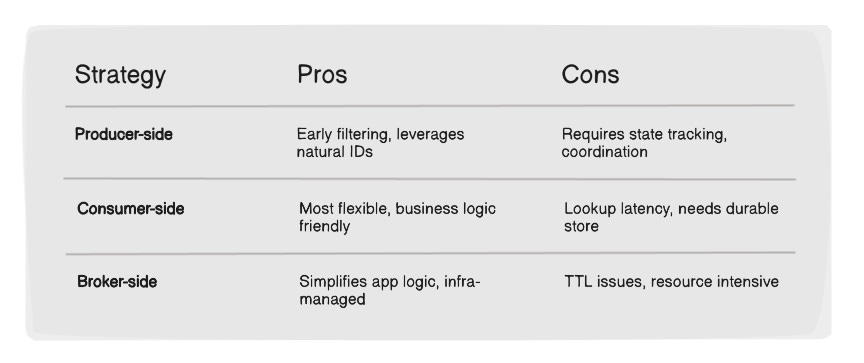
Producer-Side Deduplication
✅ Useful when the producer owns message creation and retries.
✅ Ideal in systems with natural IDs (e.g., transaction ID).
Challenges:
Requires state tracking on the producer.
Brokers and consumers must respect IDs.
Example: A trading system adds
trade_idto each trade. On retry, downstream systems use the ID to discard duplicates.
Consumer-Side Deduplication
Consumers check a deduplication storage before acting. If the ID exists, they skip it. Otherwise, they process and record it.
✅ Most flexible.
✅ Easy to adapt to business logic.
✅ Light if implemented well.
Challenges:
Lookup latency.
Requires a durable store.
Must be atomic to avoid race conditions.
Example: A fraud detection system stores
transaction_ids in Redis. If a duplicate appears, it's skipped.
Broker-Side Deduplication
Some brokers offer deduplication with TTL-backed caches.
✅ Simplifies producer and consumer logic.
✅ Offloads complexity to infrastructure.
Challenges:
TTLs can evict IDs too soon.
Memory and storage can balloon with high-cardinality traffic.
Example: RabbitMQ deduplicates messages using a fixed-size cache keyed by
message-id.
These strategies are more than theory. Let's look at how a real tool approaches this in production.
Real-World Example: How Buf Handles Duplication
Buf is a great example of a real-world system that handles duplication without overengineering.
Bufstream is 8x less expensive than Apache Kafka while remaining fully compatible with existing Kafka clients, tools, and applications.
If you're curious how modern infra teams apply these principles in production, Buf is worth checking out.
They are also sponsoring this post.
Thank you to our sponsors who keep this newsletter free!
Bufstream, Buf's event delivery infrastructure, handles deduplication using broker-level enforcement of exactly-once semantics (EOS) and producer-side idempotence, not consumer-side logic.
When producers are configured with enable.idempotence=true. Each message is assigned a unique sequence number (within the context of a producer). Bufstream brokers use this to detect duplicates. Combined with Kafka's transactional protocol, a message is delivered and processed only once, even during retries or failures.
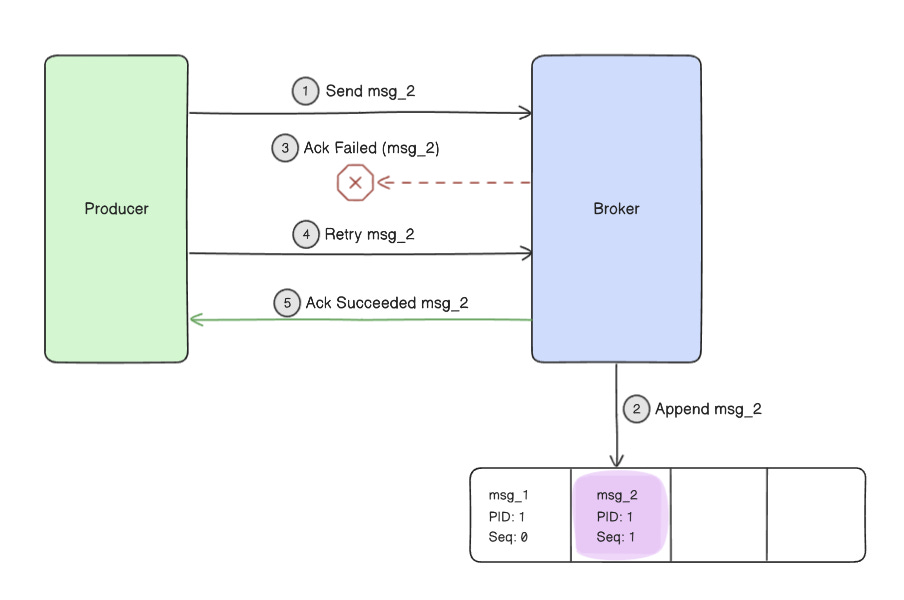
Key Strategy:
Deduplication happens upstream using producer sequence numbers and broker coordination. Consumers receive only one copy, even after retries.
This approach handles:
Broker retries
Network issues
Manual replays
✅ Benefits:
Atomic: Processing and tracking are one transaction.
Resilient: Safe on retries and reprocessing.
Fail-safe: Errors trigger rollback.
Thanks to producer-side idempotence and broker-level guarantees, this message will only be delivered and stored once, even if retries or network issues occur.
Takeaways
Duplication is normal. Design for it.
Place the deduplication logic as close to the side effect as possible.
Always include unique operation IDs.
Trust a durable state, not retries or timeouts.
Sanity check before launch: “What happens if this message arrives twice?”
If the answer is “We're screwed,” fix it before your users find out.
Duplication isn't a bug, it's the price of distribution.
Deduplication is a system design problem, not just an implementation detail.
Review your pipelines. Simulate duplicates. And assume your system will be tested, because it will.
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Articles I enjoyed this week
How Apple Pay Handles 41 Million Transactions a Day Securely by Neo Kim
Open-Closed Principle (OCP) In React: Write Extensible Components by Petar Ivanov
Also, Hungry Minds always brings good stuff. By Alexandre Zajac
Thank you for reading System Design Classroom. If you like this post, share it with your friends!
That's why designing for idempotency is crucial.
Awesome article, Raul!
Excellent explanation my friend! Idempotency is a very important consideration for developers
Also, thanks for the mention.