
Transaction Isolation only makes sense if you understand Read-and-Write Anomalies.
This is the foundation of ACID, and here is what you need to know.

Can you imagine a world without transactions?
Think about a money transfer operation between two accounts where only the debit happens, but the credit doesn't.
Transactions are what make our complex operations possible. This is why:
Practice makes perfect, and there’s no better way to sharpen your skills than by building the tools you use daily. CodeCrafters lets you create your own Docker, Git, Redis, and more.
Hands-on Projects + Practice = Engineering Mastery
Sign up and get 40% off if you upgrade.
Thank you to our sponsors who keep this newsletter free!
What is a transaction?
A transaction is basically a bunch of read-and-write operations that happen in a database.
In real systems, many transactions happen at the same time. The easiest way to deal with this would be to run them one by one. But this approach would slow everything down and hurt performance.
Instead, databases try to run transactions concurrently but in a way that makes it seem like they happened one after another.
For example, imagine three transactions happening at the same time. These transactions could be executed in 6 different orders (3! = 6 possibilities). Each of these possible orders is called a "history" or "schedule."
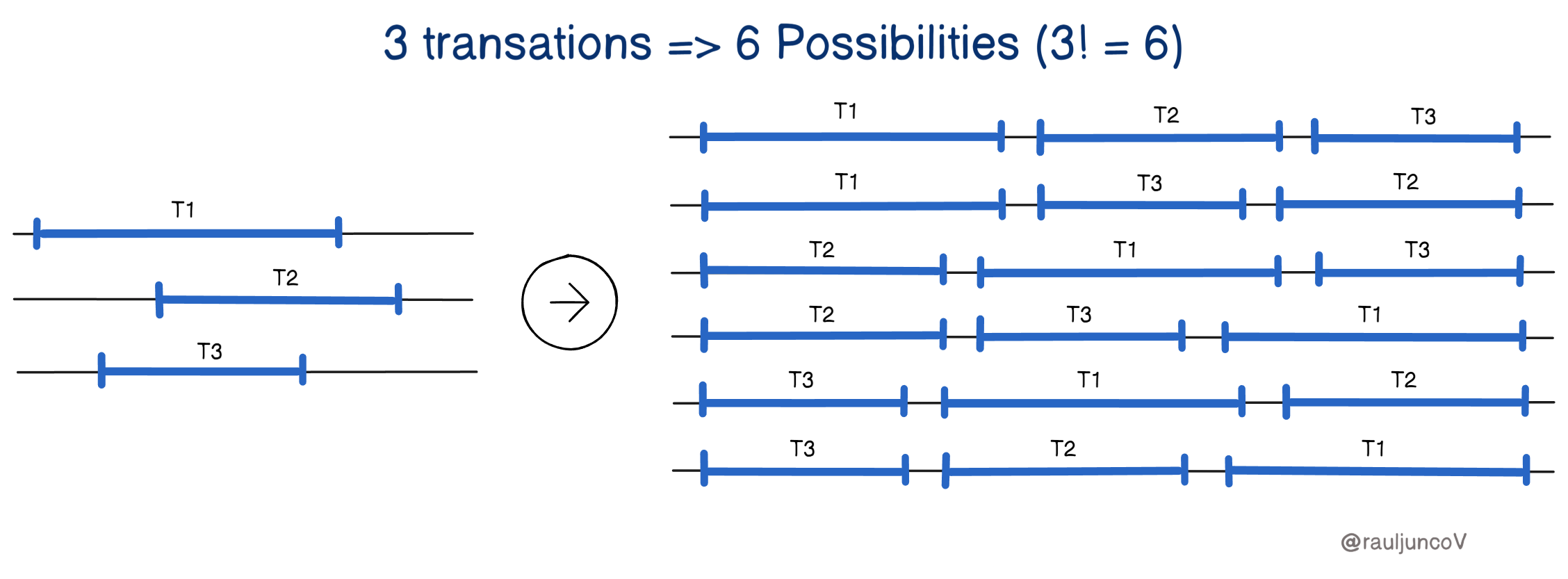
Running many transactions at the same time can cause anomalies, which, if not handled properly, can lead to incorrect or inconsistent data.
Read and Write Anomalies
When multiple transactions happen at the same time, different types of issues (known as anomalies) can occur. Let's check some:
1. Dirty Reads
Example: One transaction reads data that another transaction has changed but hasn't committed yet. If Transaction B fails and rolls back, Transaction A ends up with bad data.
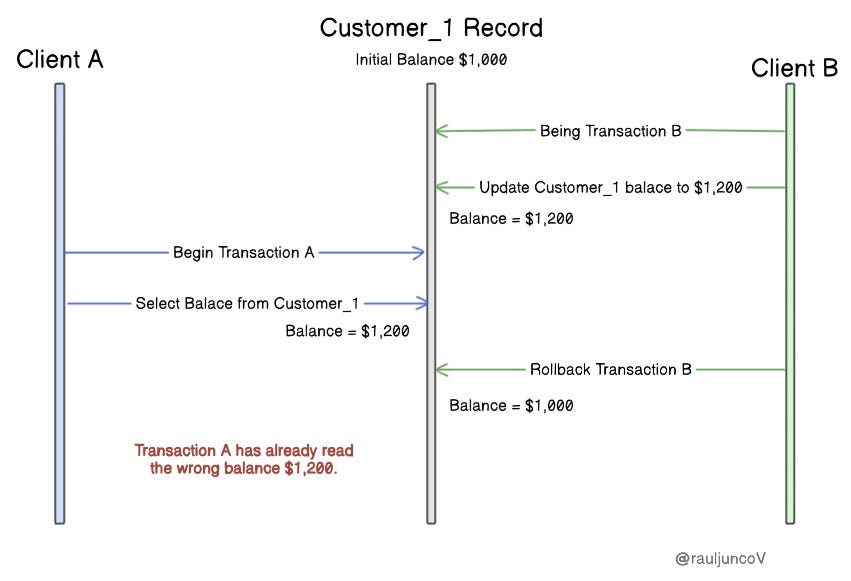
Scenario: Transaction B updates a customer balance from $1,000 to $1,200 but hasn't committed yet. Meanwhile, Transaction A reads this updated balance. If Transaction B rolls back, the balance should be $1,000, but Transaction A has already read the wrong data.
2. Non-Repeatable Reads
Example: One transaction reads the same data twice, but another transaction changes the data in between, so the values don’t match.

Scenario: Transaction A reads a product price as $50. Then Transaction B changes the price to $60 and commits. When Transaction A reads the price again, it now sees $60 instead of $50.
3. Phantom Reads
Example: A transaction reads rows that match a condition, but another transaction inserts new rows that also match that condition before the first transaction finishes.
Scenario: Transaction A reads all orders with a value greater than $1,000. While it's still running, Transaction B adds a new order of $1,500. If Transaction A runs the query again, it sees this new order, which wasn't there initially.
4. Write Skew
Example: Two transactions read the same data and make changes based on those reads, which can lead to conflicts.

Scenario: Imagine an inventory system in which two transactions check that there are 10 items in stock. Transaction A reserves 7 items, and Transaction B reserves 5 items. Both transactions commit their updates without realizing the occurrence of a Lost update, leaving the inventory in an invalid state.
These examples show why managing concurrency is important in database systems.
Transaction Isolation Levels
Transaction isolation levels decide how well the database can prevent these anomalies. There's always a balance between data consistency and system performance. Here are some common isolation levels:
1. Read Uncommitted
Behavior: Allows transactions to read uncommitted changes made by others.
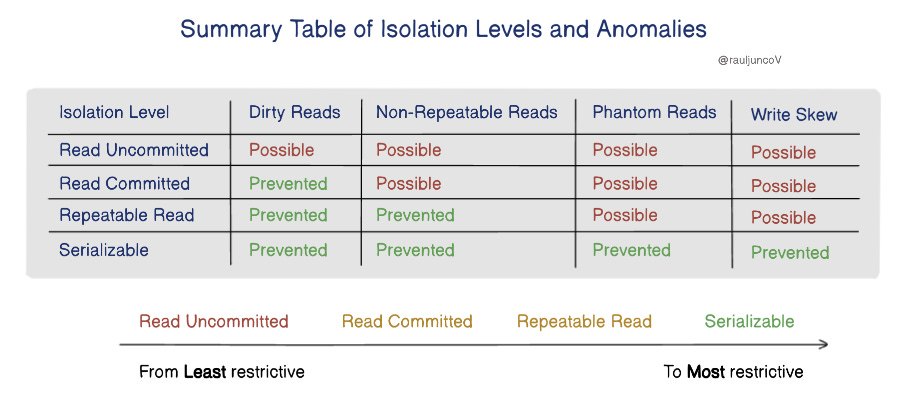
Anomalies Prevented: None.
Vulnerabilities: Allows dirty reads, non-repeatable reads, and phantom reads.
Example Use Case: Useful for scenarios where performance is critical, and inconsistencies are tolerable, like logging or analytics systems that work with approximate data.
2. Read Committed
Behavior: Only reads changes that have been committed.
Anomalies Prevented: Prevents dirty reads.
Vulnerabilities: Still allows non-repeatable reads and phantom reads.
Example Use Case: Ideal for most OLTP systems, such as e-commerce platforms, where it's critical to avoid dirty reads while maintaining good performance.
3. Repeatable Read
Behavior: Once a value is read, it will be the same for the rest of the transaction.
Anomalies Prevented: Prevents dirty reads and non-repeatable reads.
Vulnerabilities: Phantom reads can still happen.
Example Use Case: Suitable for banking or financial applications where consistency during a transaction, like verifying balances, is essential.
4. Serializable
Behavior: The highest level of isolation; makes sure transactions happen in a way that could have happened one by one.
Anomalies Prevented: Prevents all anomalies (dirty reads, non-repeatable reads, phantom reads).
Vulnerabilities: None, but it can slow down performance a lot.
Example Use Case: Necessary for systems like inventory management where overselling or data conflicts must be entirely avoided.

There are some exceptions. PostgreSQL does not support the "Read Uncommitted" isolation level, so it treats such transactions as "Read Committed."
Performance Trade-offs
You can summarize the relationship between isolation levels and performance in a fundamental trade-off:
Higher isolation levels provide stronger consistency but reduce concurrency and performance.
Lower isolation levels improve performance but increase the risk of data anomalies.
Choose your isolation level based on these factors:
Read Uncommitted when speed is critical, and some inconsistency is acceptable.
Read Committed for general-purpose applications requiring basic consistency.
Repeatable Read when calculations or business logic depend on consistent reads.
Serializable when data integrity is critical, and performance can be sacrificed.
Wrapping up
Understanding transaction isolation and anomalies is crucial for anyone working with databases. Let's recap the key points:
Transactions are the backbone of data consistency and reliability in concurrent systems.
Isolation levels offer a spectrum of trade-offs between data consistency and system performance.
Remember, there's no one-size-fits-all solution. The art of database management lies in striking the right balance between consistency and performance for your specific application needs.
Transaction isolation is the key to preventing chaos in data — without it, Anomalies would run the show.
Happy New Year!
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
References
"Database Internals" by Alex Petrov.
"Designing Data-Intensive Applications" by Martin Kleppmann.
Articles I enjoyed this week
How to Choose the Right Database in a System Design Interview by Ashish Pratap Singh
How Shopify Handled 30TB per Minute With a Modular Monolith Architecture by Neo Kim
How Netflix Uses Caching To Hold Attention? by Saurabh Dashora
Thank you for reading System Design Classroom. If you like this post, share it with your friends!
Nice Explanation Raul,
Learning more from you on LinkedIn.
I also tried to explain the same isolation concepts here - https://parottasalna.com/2025/01/04/learning-notes-33-isolation-in-acid-postgres/
Great article! Very concise and well explained. Thanks!