
I used to think testing in production was a bad joke. I was wrong.
A Practical Guide to Test in production.

I used to think testing in Production was a bad joke—something reckless engineers did out of desperation.

But as systems grew more complex, I realized that it was not just a reality but a necessity.
Staging environments can never fully replicate real-world conditions, making live testing more important for ensuring reliability, resilience, and performance at scale.
Want to master real-world software engineering techniques? CodeCrafters offers hands-on challenges that help you build production-ready systems from the ground up.
Write your own Redis, Git, or Docker to understand how the best tools work under the hood.
Develop resilience and scalability by building real-world software components.
Level up your system design skills with practical exercises inspired by industry challenges.
Sign up and get 40% off if you upgrade.
Thank you to our sponsors who keep this newsletter free!
Why Test in Production?
Staging environments help catch issues early but fall short in replicating the unpredictable nature of real-world systems.
Production environments expose the software to live traffic, real user behavior, and infrastructure constraints, making them the ultimate testing ground.
On the other hand, Production environments contain more data, and data is difficult to replicate and maintain in lower environments. This makes testing in Production even more valuable, as it allows validation against real-world conditions that staging cannot fully mimic.
No test environment can simulate the complexity of real users, fluctuating traffic, or unpredictable third-party interactions.
Modern architectures support incremental rollouts, real-time monitoring, and rapid rollbacks, making Production testing more manageable.
Only real traffic can reveal bottlenecks and performance degradation at scale, helping fine-tune system optimizations.

Six Effective Methods for Testing in Production
A/B testing
With an A/B test, you deploy two versions of the same functionality; some users see either the "A" or the "B" version.

You are then able to see which version of the functionality performs best.
Use this when deciding between two different approaches for how something.
For example, you might try two different customer registration forms to see which is more effective in driving sign-ups.
Canary release
A small part of your user base sees the new functionality release.
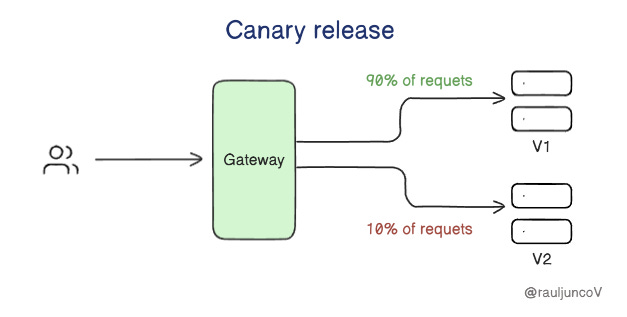
If this new functionality works well, you can increase the number of users who see it until all users can see the new version.
If the new functionality doesn't work as intended, you will only affect a few of your users.
You can either revert the change or try fixing any problem.
Parallel run
You execute two similar implementations of the same functionality with a parallel run.
Any request is routed to both versions so you can compare their results, although the user sees only one.
This is very useful when we want to better understand the change, such as how it is performing.
Smoke Tests
You run these after deploying your new version in Production, but before releasing it.
These tests are often automated and can go from very simple activities (is a service running?) to executing complex operations.
It acts as a quick validation step to catch major issues early.

Synthetic transactions
Synthetic transactions simulate real user interactions with the system without actual user involvement.
These transactions execute predefined workflows in Production to validate that critical functionalities work as expected.
This technique is particularly useful for monitoring APIs, payment gateways, and key business operations.
Unlike traditional tests, synthetic transactions continuously run in Production, providing ongoing validation rather than a one-time check.
It's often very close to the end-to-end test you might write.
Placing an Order is a great example.
Chaos engineering
Chaos engineering is the injection of faults into a Production system to ensure it can handle it.
The best-known example of this technique is probably Netflix's Chaos Monkey.
Chaos Monkey can turn off virtual machines in Production. The idea is that the system is robust enough that these shutdowns don't interrupt the end user.
Trade-offs in Production Testing
Testing in production is powerful, but it also comes with trade-offs.
You get real-world insights, but you also risk impacting live users.
Some methods let you test with minimal risk, while others push your system to its limits.
Here is a summary.

A couple of things to consider (AKA best practices):
Set some fake users in production. Keep test transactions separate from real users to prevent unintended disruptions.
If you order products, make sure they are fake (you don't want 200 sofas arriving at your head office).
Track logs, metrics, and distributed traces for real-time insights.
Always Have a Rollback Strategy
Wrapping up
The only way to know how your system behaves in the real world is to test it in the real world.
Think testing in production is a reckless move? It's actually what top engineers do to ensure reliability at scale.
Testing in production is not reckless—it is a necessity for scalable, resilient, and user-centric software.
Good engineers test in staging. Great engineers validate in production.
Where are you testing?
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Articles I enjoyed this week
1 Simple Technique to Scale Microservices Architecture by Neo Kim
4 Challenges of Distributed Systems - And Possible Solutions by
How Did SoundCloud Scale Its Architecture Using BFF, Microservices & DDD by Petar Ivanov
Thank you for reading System Design Classroom. If you like this post, share it with your friends!
The higher our tests resemble the way our customers use our system, the better. So testing in product is important, but we must make sure not to pollute the environment with wrong statistics and data.
Love this article, Raul!
Thanks a lot for this article! Testing in production is something I pushed my team to aim too all the time, I still accept dev environment (I named them dev to emphasize they should be used for development, rather than for testing) but I make it clear that if they cannot show that a feature is working in prod, the feature is not ready to be released.
One thing that I found missing regarding this, is patterns to implement those elements. Devs usually have little knowledge on how to implement feature flags, rollback strategies, a/b testing, parallel runs, etc. The part they are missing are usually on the design part: proper rollback is not just a matter of the build pipeline, the code and the data should also support it. Idem for canaries (how to run two different versions of the same services in the same environment?), parallel runs (useless if you don't have proper observability, but what those that means?), chaos engineering (do your service implement a proper health check? Do you handle timeout? Do you have a circuit breaker?), etc.
It will be very interesting to visit those patterns in your channel. I think they are a major part of good system design, and too many teams relegated those issues to the "DevOps/SRE team" rather than building them for themselves, which is quite unfortunate because of how much those things can improve the developer's quality of life.