
System design isn't a Cut & Paste job.
Templates and checklists are helpful tools, but they only work if you dive deep to understand the problem. Here’s how:

Thank you to our sponsors who keep this newsletter free:
Multiplayer auto-documents your system, from the high-level logical architecture down to the individual components, APIs, dependencies, and environments. Perfect for teams looking to streamline system design and documentation management without the manual overhead.
Scalability is a frequent hurdle, and there's a 99.99% chance it came up in your System Design interview.
I always start by asking about the Read/Write Ratio. Most of the time, this simple question will tell you which pieces you need to focus on.
The Example
A product catalog on an e-commerce website is a classic example of a problem with a high read ratio and a low write ratio.
It has a High Read Ratio because:
Users frequently browse the product catalog to view product details, search for items, read reviews, and check prices.
This involves many read operations as many users repeatedly fetch the product data from the database.
It has a Low Write Ratio because:
The actual updates to the product catalog (like adding new products, updating prices, or changing stock levels) happen relatively infrequently compared to the number of reads.
These updates typically occur due to periodic inventory updates, price changes, or new product additions to the catalog, which are far less frequent than users browsing the site.
This imbalance between reads and writes makes it ideal to scale the read-heavy parts from the write-heavy parts, allowing the system to handle large traffic efficiently without over-provisioning resources for the less frequent writes.
Let's go step by step.
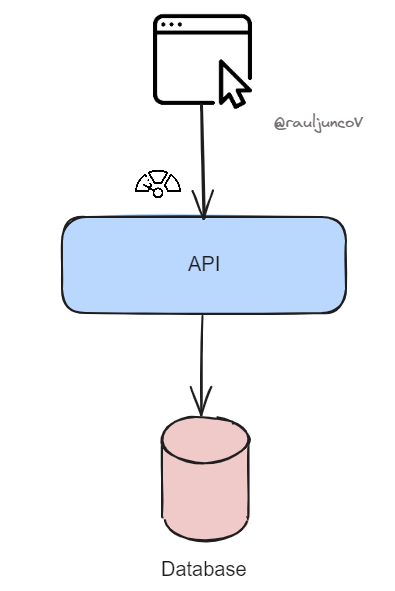
Step 0: Initial Setup
In the initial design, you have a simple service and a single database that handles all operations:
Service: A single service (API) handles all incoming requests, both read (fetching data) and write (updating data) operations.
Database: A single database serves as the backend, storing all the data and handling both reads and writes directly.
This is how we start.
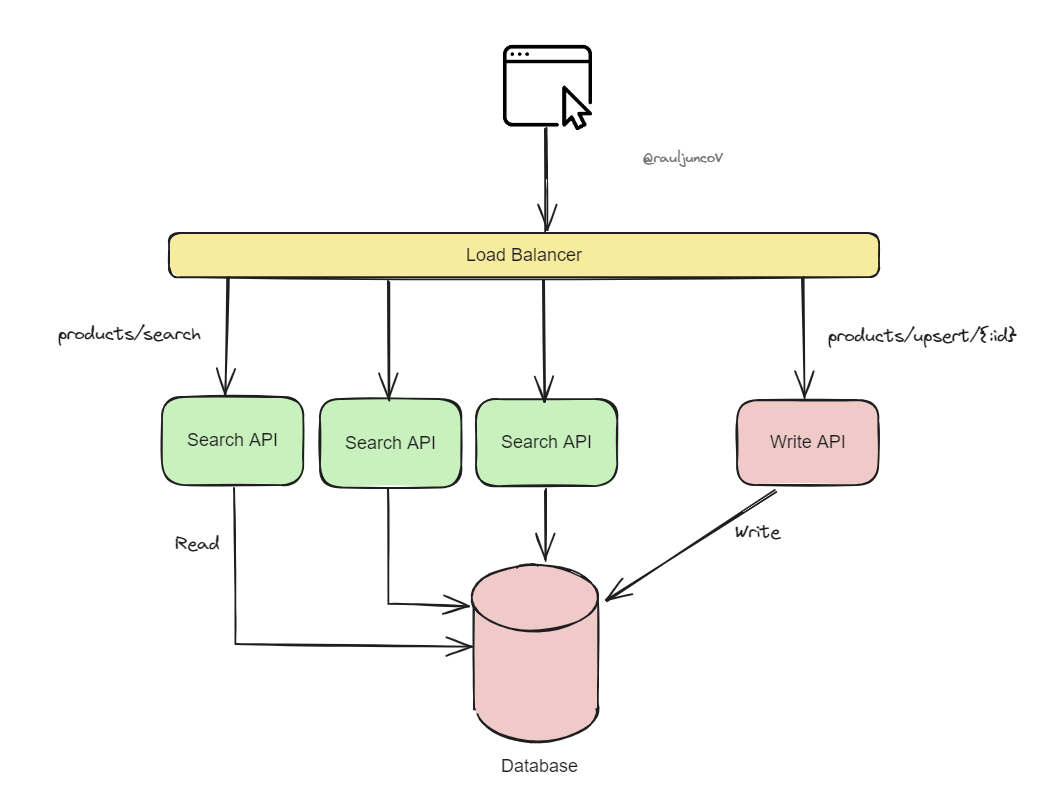
Step 1: Separate services so they can scale differently.
The purpose is to decouple services and allow you to scale parts of your system independently according to their load.
You need to split the application into distinct services based on their function.
"Read Services" for handling data retrieval (e.g., product searches or user queries).
"Write Service" for managing data updates (e.g., adding new products or updating inventory).
The main benefits: This enables you to add more instances of the read service to handle heavy read traffic without unnecessarily scaling the write service, optimizing resource use and costs. It can also contribute to your system's resilience.
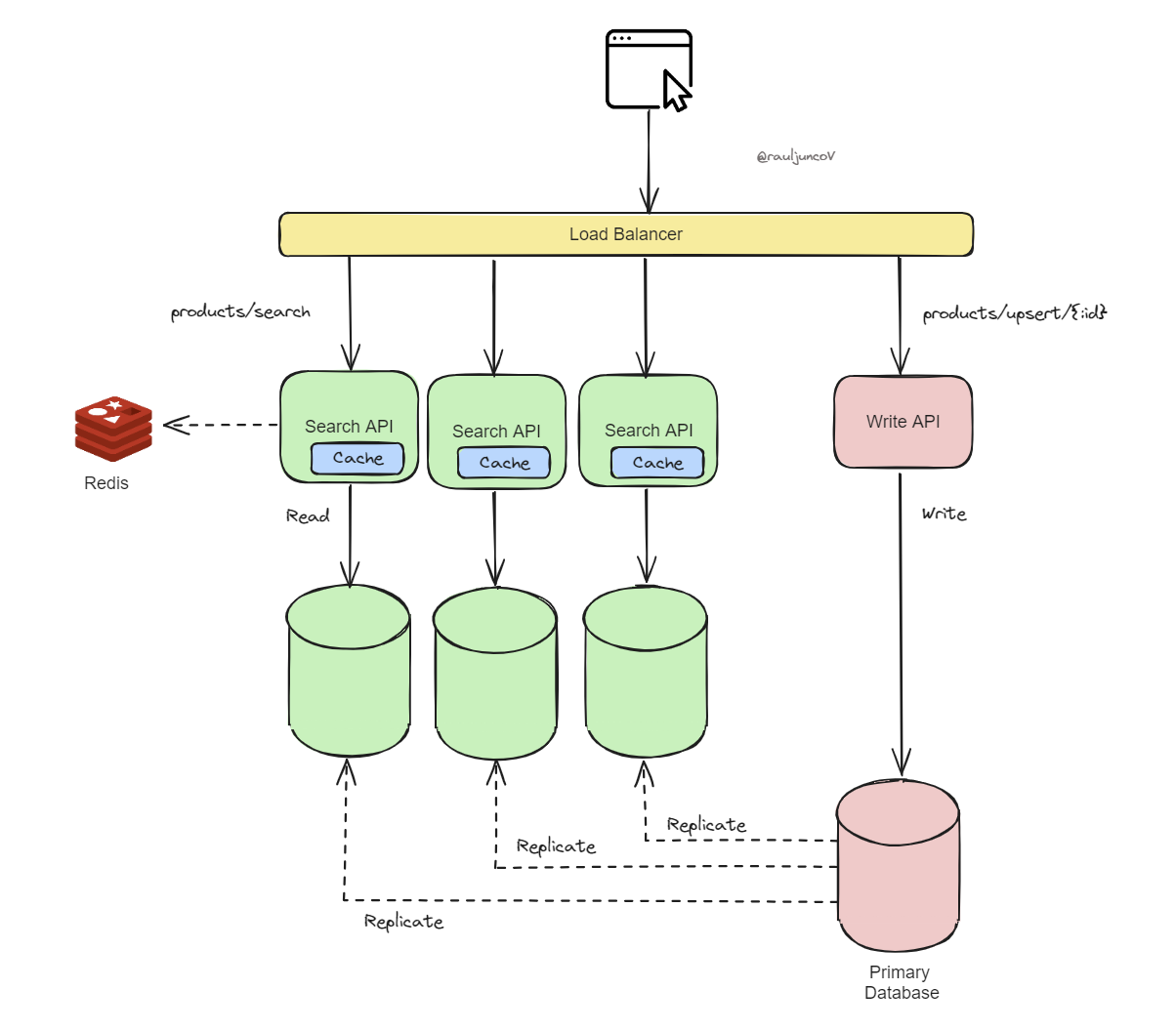
Step 2: Add a cache layer.
With a cache layer, you reduce the load on your database. Serving frequently accessed data directly from memory results in faster response times and lower latency (e.g., popular product details, best-selling products).
You can use the In-Application cache solution; it is simple and has fast access time, but it duplicates the information on each service.
You can also use a Distributed cache solution like Redis or Memcached. It centralizes cache, reducing data duplication, but requires Additional infrastructure to manage and deal with the network.
Caching can drastically reduce the number of read requests hitting your database, improving overall performance and user experience.

Step 3: Improve performance at the storage level, separating reading from writing.
The last step is at the storage layer; the idea is to separate read and write operations to handle them more efficiently.
You can achieve this using a replication setup, in which a primary database handles all write operations, and one or more replicas handle read operations.
This setup can be scaled horizontally by adding more read replicas to manage increasing read loads.
Isolating reads from writes reduces contention on the primary database, improves read throughput, and enhances system stability under heavy read traffic.

In real scenarios, you don't need to cover all the steps. You can do it incrementally as your load grows.
Scaling doesn't have to be a one-shot overhaul.
It’s more practical to address challenges as they arise, incrementally adding complexity only when necessary.
Systems design is 90% about understanding the problem at hand, not copying solutions.
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Articles I enjoyed this week
Design Principles Every Developer Should Know by Ashish Pratap Singh
Cringey, But True: How Uber Tests Payments In Production by Alvaro Duran
Thank you for reading System Design Classroom. If you like this post, Share it with your friends!
Great breakdown! The step-by-step approach here—decoupling services, adding a caching layer, and implementing read replicas—clearly shows how each layer improves efficiency without overloading resources.
Great article. I loved the incremental steps.