
Refactoring Databases Is a Different Animal
A practical pattern for evolving database schemas without breaking production

Most engineers are comfortable refactoring code.
You rename a class, split a function, or move logic into a different module. If something breaks, you fix it or roll back the commit. The blast radius is usually limited to the application you’re working on.
Refactoring a database is different.
Once data is involved, things get complicated quickly. It’s very rare to find a database only used by a single system
Mobile apps rely on it.
Admin portals query it.
Background jobs write to it.
And analytics pipelines read from it.
As a result, a simple schema change can become a production risk.
Drop the wrong column, and suddenly, multiple systems start failing at once. A harmless change in a migration script turns into a massive disaster.
Database refactoring requires a different mindset.
The safest way to evolve a schema without breaking running systems is the Expand / Contract pattern.
Building an AI demo is easy. Running AI reliably in production is a different story.
Data pipelines, governance, cost control, observability; that’s where most of the work actually is.
AWS put together a simple guide that breaks this down into 6 architectural stages, from data foundations to operating AI systems in production.
If you’re building AI systems, it’s a useful way to see where your team actually stands.

A Very Common Production Failure
Imagine a team that wants to improve a table design. They currently store the user’s name like this:

At some point, they realize this structure is limiting. Searching, sorting, and validation all become harder. Splitting the column into two fields makes much more sense:

So someone writes a migration:

The change works perfectly in development. The migration runs without errors. Tests pass.
But when the change reaches production, things start failing.
The mobile application still writes to the FullName column. The admin dashboard still reads from it. A background worker updates the field during profile imports. None of those systems deployed at the same time as the database migration.
The result is predictable: production breaks.
The schema change itself was correct. The problem was that the change was not backwards compatible.
What’s Actually at Stake
Databases usually sit at the center of the architecture.
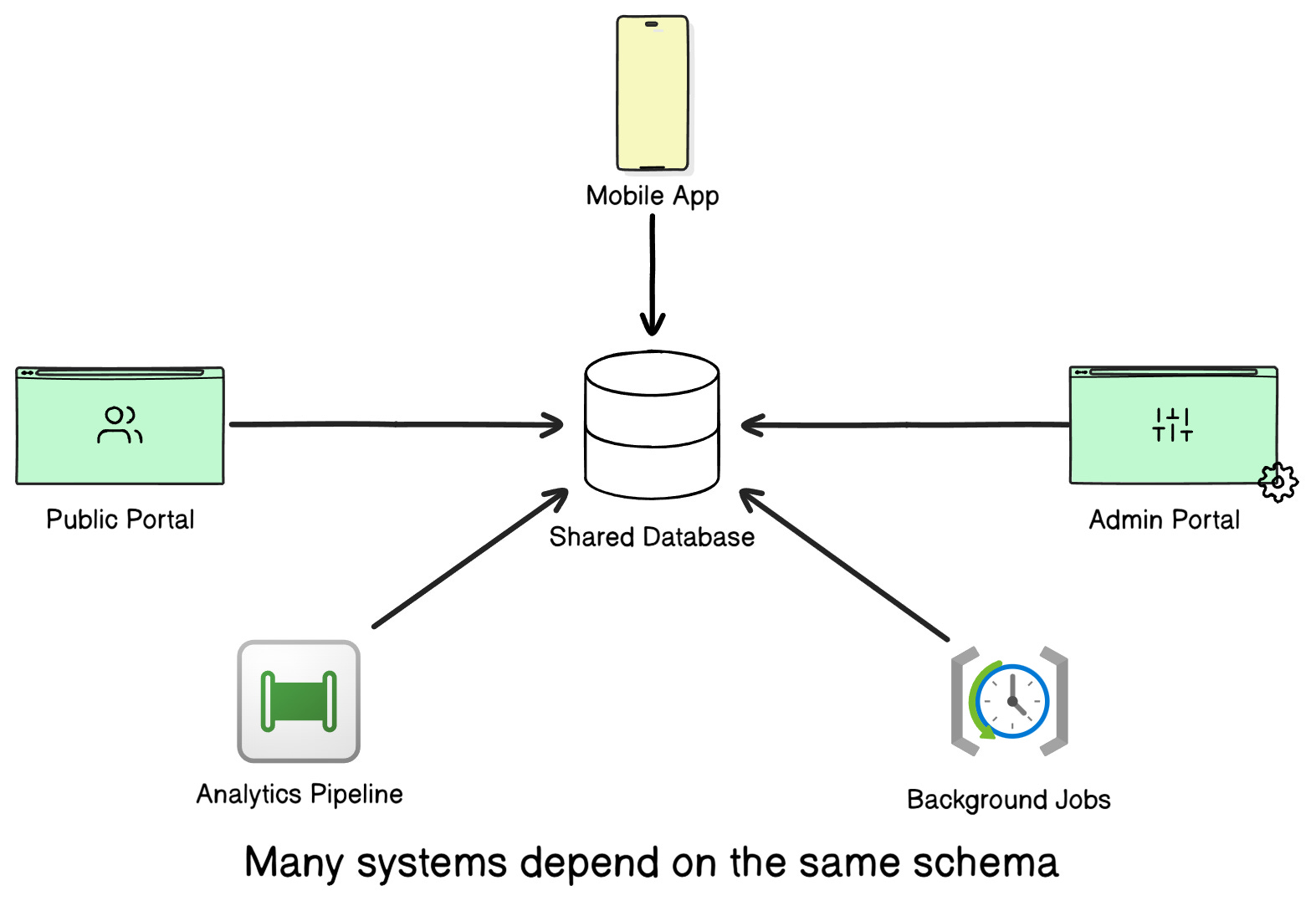
Every one of these systems depends on the same schema. That means a schema change is rarely isolated, and it becomes a cross-system change.
In theory, you could coordinate deployments across every service that depends on the database. In practice, that rarely works. Teams deploy at different speeds; some systems update frequently, while others change only occasionally.
A safer approach is to design migrations that allow old and new versions of the system to coexist temporarily.
This is exactly what the Expand / Contract pattern provides.
The Expand / Contract Pattern
The idea behind Expand / Contract is simple:
Never introduce a breaking schema change.
Instead, evolve the schema in stages so that both the old and the new structure can function at the same time.
The migration typically follows three phases:
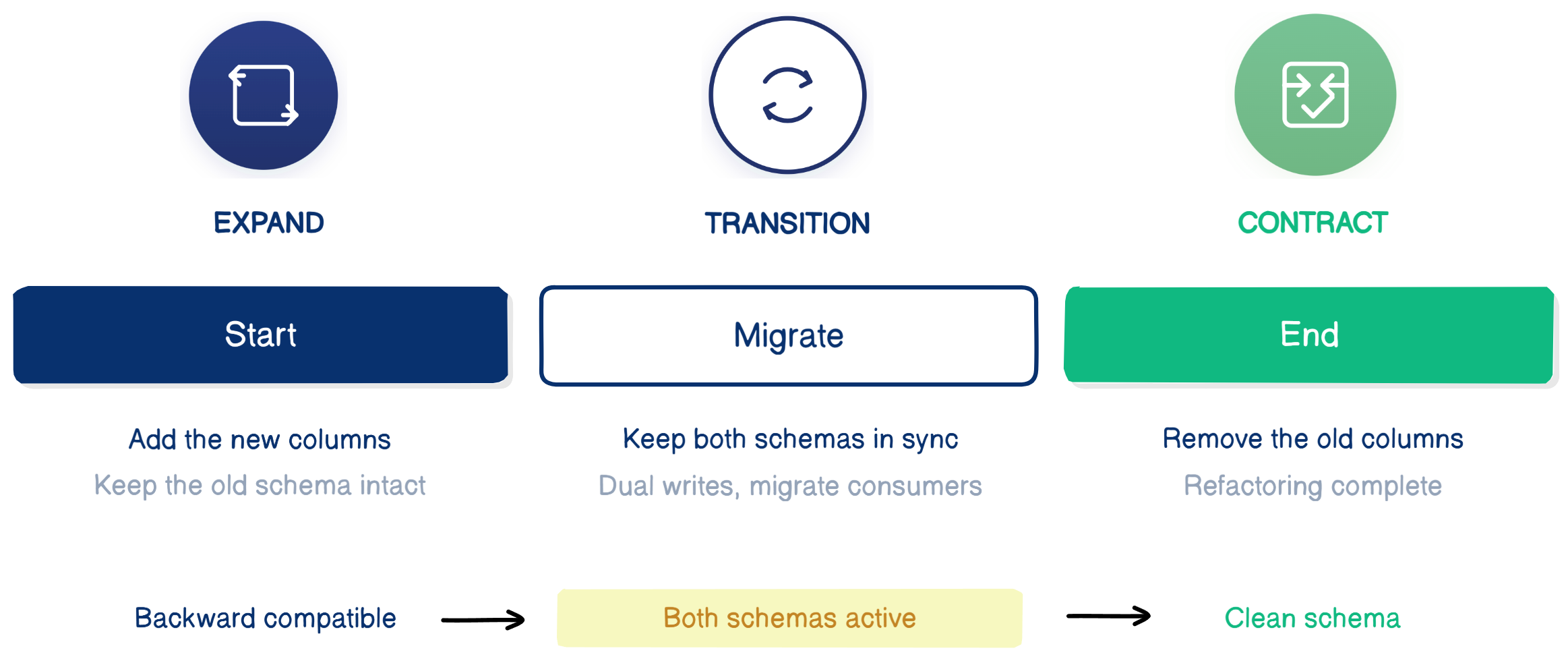
Each phase moves the system forward without breaking existing consumers.
Step 1 — Expand
The first step is to introduce the new structure while keeping the old one.
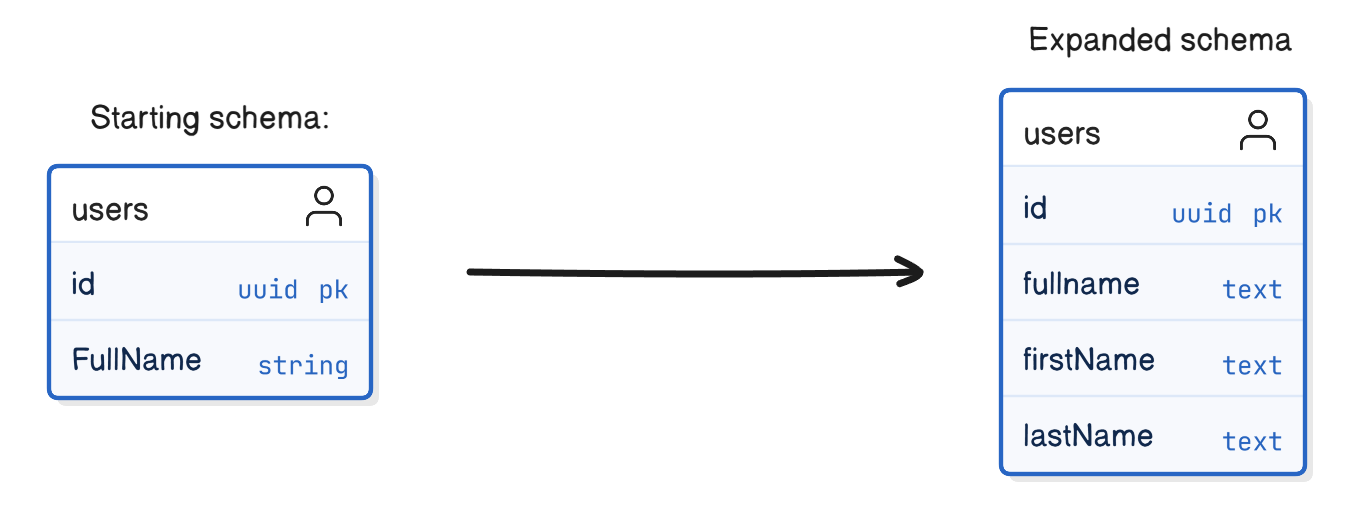
At this point, the system still works exactly as before. Existing applications continue reading and writing FullName.
Next, migrate existing data into the new structure.
Example migration logic:

Note: split_part here represents a simple string-splitting utility (either built-in depending on the database, or implemented as a helper function). In real systems, migrations often need additional logic to handle edge cases such as single-word names, extra spaces, or inconsistent formatting in the original data.
Now the table supports both formats.
Old systems keep functioning, and new systems can begin using the improved schema.
Step 2 — Transition
During the transition phase, both schemas must stay consistent.
You cannot allow data like this:

If different services read different columns, inconsistent data will appear quickly.
To prevent this, writes must keep both representations synchronized.
A simple way to do this is to use dual writes at the application layer.
Whenever a service updates user data, it writes to both the old column and the new columns.
Example:
Because both values are written inside a single database transaction, the update remains atomic, and both representations stay consistent.
Note: dual writes become much harder when they involve multiple systems (for example writing to two databases or publishing an event). In those cases, patterns like transactional outbox or change data capture (CDC) are typically used to guarantee consistency.
During this phase:
Older services continue reading
FullNameNewer services read
FirstNameandLastNameThe application keeps both representations aligned

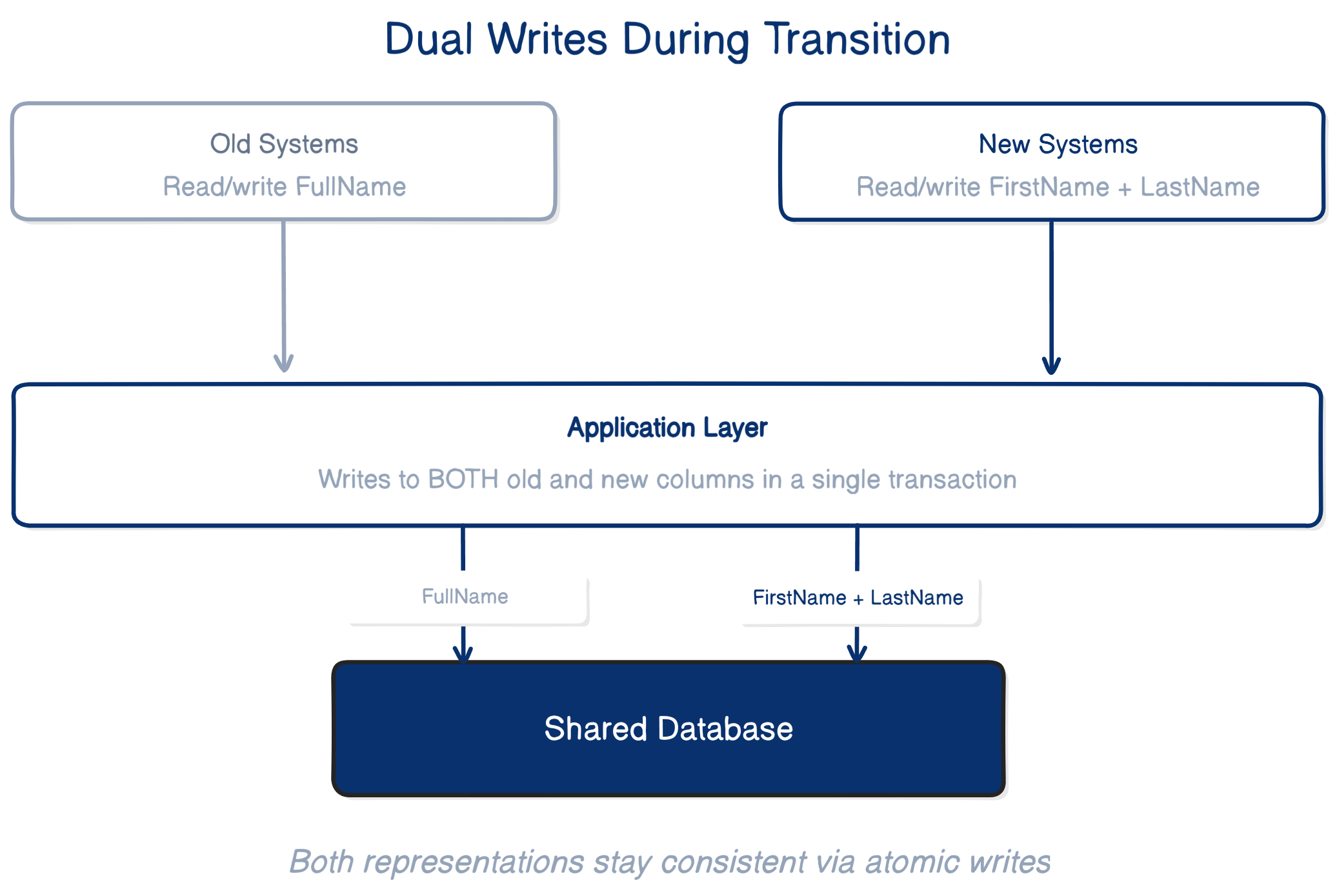
The key requirement is simple: both schemas must stay consistent until the migration finishes.
This transition period allows services to migrate at their own pace. Once every system reads from the new columns, the old column can be safely removed.
Where Should Synchronization Live?
During the transition phase, the system must keep both schema versions synchronized.
There are two common ways to enforce this: application-level dual writes or database-level mechanisms such as triggers or generated columns.
Application-level dual writes keep the logic explicit in the codebase. You can see exactly how data flows and reason about it during reviews and deployments. This approach also avoids adding extra work to the database write path.
However, dual writes rely on every writer being updated correctly. If multiple services or scripts write to the same table, it’s easy for one of them to forget the new columns during the transition.
Database-level mechanisms solve that problem by centralizing the logic. A trigger or generated column guarantees that any write to the table keeps both representations consistent, regardless of which service performs the write.
The trade-off is that triggers can add latency and make behavior less visible to application developers.
A useful rule of thumb is:
If many heterogeneous clients write to the same table, go for database-level mechanisms during the transition period.
If a single service owns the write path, application-level dual writes are usually simpler.
Both approaches follow the same principle: keep the old and new schema consistent until every consumer has migrated.
Step 3 — Contract
You can remove the old structure once all applications have migrated to the new schema.
This is known as the contract phase. The final schema becomes:

At this point, the refactoring is complete, and the compatibility layer is no longer needed.
Expand / Contract Is Not Just About Columns
Most examples focus on columns, but real schemas include more than that.
Indexes, constraints, and foreign keys often depend on the fields being migrated, so they must evolve through the same Expand / Contract lifecycle.
For example, imagine FullName has an index used for search queries. When introducing FirstName and LastName. The migration might look like this.
Expand phase

The old index on FullName remains in place while applications migrate.
Once all systems use the new columns, the old index can be removed.
Contract phase

The same principle applies to:
unique constraints
foreign keys
check constraints
partial indexes
However, creating indexes or constraints on large tables can be disruptive in itself.
Some databases support online or concurrent index creation (for example, PostgreSQL’s CREATE INDEX CONCURRENTLY), which avoids blocking writes during the operation.
You can also introduce constraints in stages. A common pattern creates the constraint first without validating existing rows, then validates the data afterward.
Example:
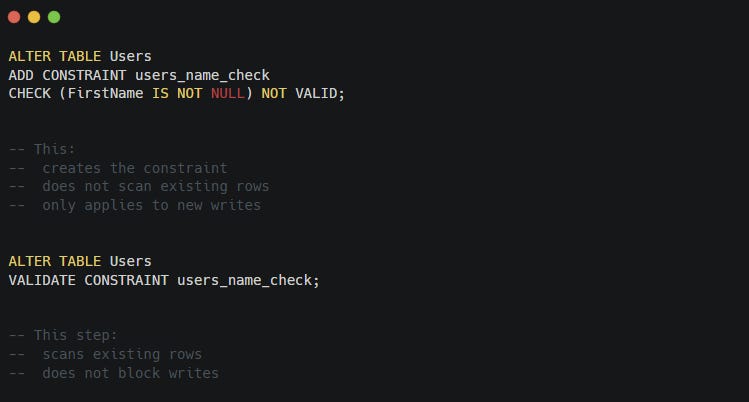
This allows the system to keep running while the database verifies existing data.
Realistic Considerations
The pattern itself is straightforward. Real systems introduce complications.
Long transition periods
Some consumers migrate slowly.
Internal tools, reporting jobs, and ETL pipelines often depend on the same tables but deploy on very different schedules. It’s not unusual for the transition phase to last weeks or even months.
Temporary schema complexity is part of the cost of safe evolution.
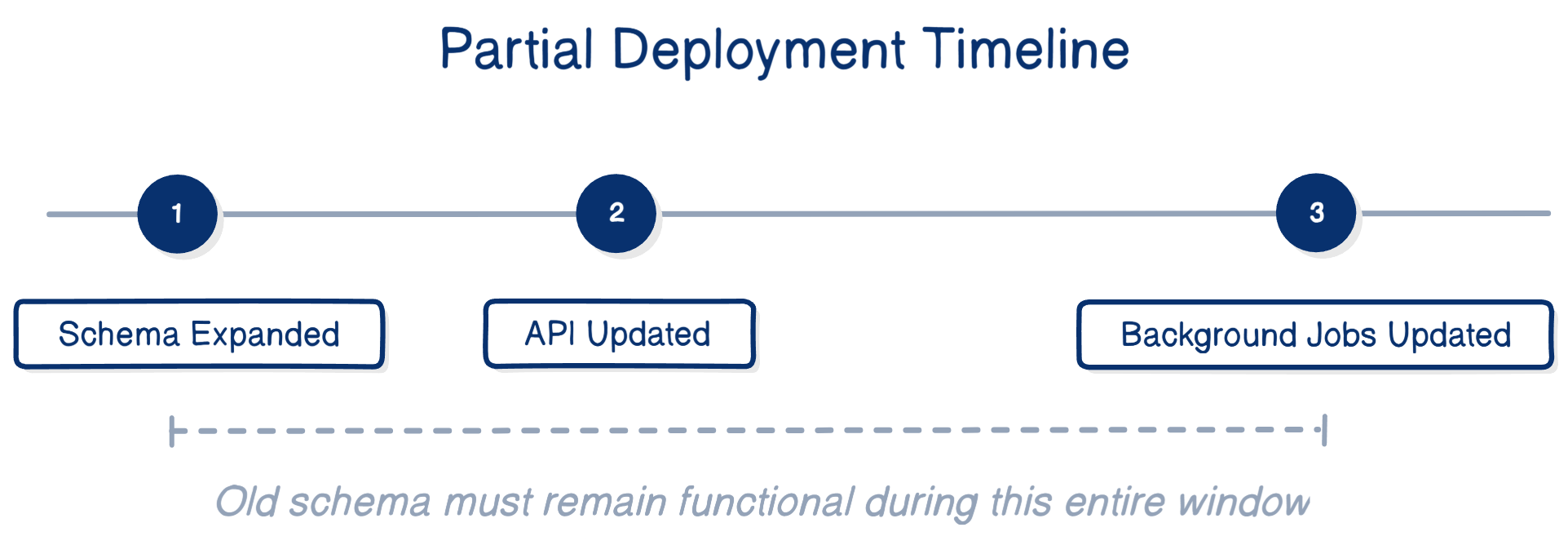
Partial deployments
It is common for migrations and application changes to deploy at different times.
For example:
Migration Checklist
Before running a schema migration, it helps to answer a few operational questions.
Do we have a backfill plan and progress tracking?
Large tables often require batch migrations. Make sure the process can run incrementally and resume if interrupted.How will we detect when the last consumer of the old schema is gone?
Base schema removal on evidence. Monitor queries, application logs, or feature flags to confirm that no services still depend on the old fields.What’s the rollback strategy if the new schema misbehaves?
Even backward-compatible migrations can introduce unexpected issues. Make sure the system can safely revert to the previous behavior while both schemas still exist.
Thinking through these questions early helps you avoid the most common failure mode of database migrations: discovering operational problems only after the change reaches production.
During this entire window, the system must function correctly with both schemas.
High-volume tables
On tables with heavy write traffic, synchronization mechanisms require extra care.
Triggers can add latency because they execute on every write. For very busy tables, many teams prefer dual writes combined with feature flags in the application layer.
Services gradually migrate their reads while the application maintains compatibility during the transition.
Backfilling Large Tables Without Locking Them
Backfilling Large Tables Without Locking Them
The examples above use a simple migration:
This works well on small tables.
On large production tables, it can cause serious problems.
A single UPDATE touching millions of rows can:
lock the table
generate massive transaction logs
block writes
slow down the database for other workloads
Instead, most teams backfill data in batches.
The idea is simple: update small chunks of rows at a time.
Example:
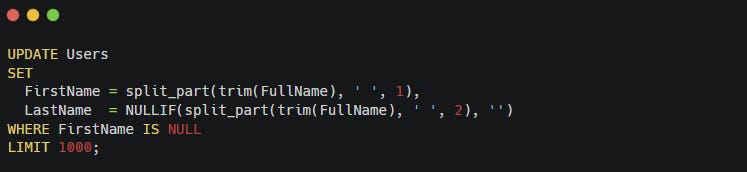
A background job repeatedly runs until it migrates all rows.
Pseudo workflow:
This approach keeps transactions small and prevents long table locks.
It also allows the migration to run safely while the system continues serving traffic.
Many production systems combine this with progress tracking, so the job can resume if it stops.
The goal is simple:
Migrate the data without impacting the rest of the system.
The Hardest Problem Is Not Technical
The Expand / Contract pattern itself is technically simple.
The hardest problem is organizational.
Shared databases mean multiple teams depend on the same schema. That means migrations require coordination, communication, and clear ownership.
Without that discipline, temporary compatibility layers remain indefinitely. Old columns stay around because nobody is sure which system still depends on them.
Over time, schemas accumulate artifacts like this:
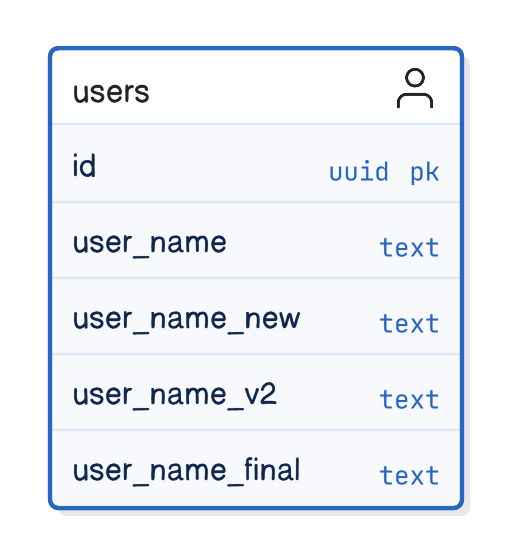
Successful teams treat schema changes like any other cross-team change:
they track migration progress
define schema ownership
schedule the contract phase explicitly
The technical pattern is straightforward.
The real challenge is making sure the organization follows through.
Takeaways
Database refactoring is harder than code refactoring because many systems depend on the same schema.
Direct schema changes often break running services.
The Expand / Contract pattern allows schemas to evolve safely by introducing changes in stages.
Dual writes keep old and new structures consistent while systems migrate.
A schema migration completes only after you remove the old structures.
The safest database migration is the one that allows old and new systems to coexist.
Compatibility buys you time.
Time keeps production running.
Until next time,
— Raul
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a paid subscriber.