
Performance Doesn’t Start at SELECT; It Starts at CREATE.
Stop blaming your queries. Most database slowness comes from design mistakes made on day one.

Most engineers learn query optimization too late.
They spend days adding indexes, rewriting JOINs, and tuning queries…
only to realize the real problem isn’t the query; it’s the schema.
Most of the time, slow queries are symptoms, not causes.
The disease starts with schema design.
The Problem is that you can rewrite a query a hundred times; but if the schema underneath is broken, you’re just polishing rust.
When a database is poorly designed, every new feature adds friction:
Queries grow more complex.
Indexes pile up without real gain.
Data integrity becomes optional.
Performance quietly decays until it explodes, like a dead whale.
By the time you notice, you’re dealing with migrations, downtime, and brittle code paths that no amount of indexing can save.
Most teams don’t realize this until it’s too late.
The first few releases run fine.
Then, traffic spikes, queries slow down, and the database becomes the bottleneck no one planned for.
It’s at that point you discover what good engineers already know:
Performance is baked in at the schema level.
Every decision you make during CREATE (data types, constraints, normalization, indexes) decides how well your system will scale later.
Here’s how to build it right.

Real-time isn’t a buzzword, it’s the performance edge for companies like Vercel, Canva, and Framer. Tinybird helps them transform massive streams of data into instant insights and real-time user experiences.
To share what we’ve learned over the last 5 years running Petabyte-sized clusters, we built a free course on real-time analytical data foundations designed for developers who want to master the basics and build faster, smarter data products.
1. Normalize First, Then Denormalize with Evidence
Normalization isn’t just a database theory; it’s your first defense against chaos.
When you normalize, you enforce discipline:
Every column has a single, clear purpose.
Relationships are explicit, not implied.
Updates happen in one place, not ten.
That structure pays off when your system evolves.
New features don’t break old data. Schema changes stay localized.
You can scale without rewriting your business logic.
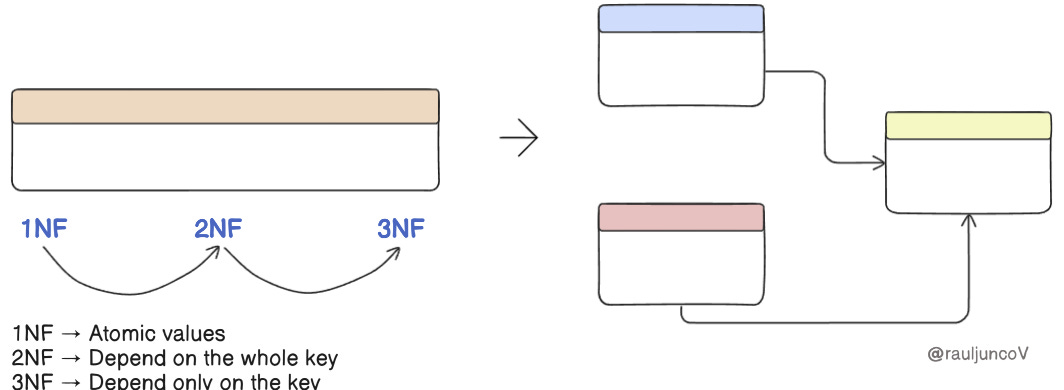
Start here. Get it right. Then measure.
If you later discover that query performance is suffering, that JOIN-heavy reports or analytical workloads are dragging, that’s when you earn the right to denormalize.
But denormalization should always be a measured trade-off, not a default decision.
Every denormalization is a bet: you’re trading consistency for speed.
Make sure it’s a bet you can afford to lose.
Denormalize when:
You’ve identified repeated JOINs on high-traffic queries.
You’re operating on immutable data (like historical logs).
You’ve validated the benefit through metrics, not assumptions.
Denormalize with evidence, not fear.
Most systems suffer not because of normalization, but because of shortcuts taken before the first slow query ever appeared.
2. Use the Right Data Types
Your choice of data types decides how efficiently the database stores, compares, and retrieves your data.
It’s not a trivial decision, it’s a design constraint with real cost.
Most performance issues trace back to oversized or mismatched types.
Developers reach for VARCHAR(255) out of habit, or store timestamps as strings because it “just works.”
Those shortcuts add up, in memory, CPU, and I/O, especially when your table holds millions of rows.
Here’s what to remember:
Use the smallest data type that fits.
Smaller data types mean smaller indexes, faster scans, and less memory pressure.
For example,SMALLINT(2 bytes) can handle values up to 32 767; often enough for bounded IDs.Avoid generic types like
TEXTandBLOBunless absolutely necessary.
They live off-page in most engines, increasing read latency and memory churn.
If you must store large blobs or unstructured text, isolate them in a side table or a storage service optimized for that pattern.Match semantics to type.
Don’t store dates as strings. Don’t store numbers in text. Don’t use floats for currency.
Every mismatch forces implicit casts and wastes CPU cycles.Prefer fixed-width types when possible.
Fixed-width data (INT,DATE,CHAR) makes row access predictable and cache-friendly.
Variable-width types (VARCHAR,TEXT) require extra bookkeeping and page splits.Use JSON types with intention.
JSON columns (JSONin MySQL,JSONBin Postgres) They are great for flexible metadata, feature flags, configuration, and sparse attributes.
But they come with trade-offs:They’re harder to validate at the database level.
They can’t always use traditional B-tree indexes.
They tempt teams to bypass schema design entirely.
Treat JSON as an extension, not an excuse. Store structure when you know it; store JSON when you don’t.
If you rely on JSON queries heavily, index specific keys with expression or GIN indexes.
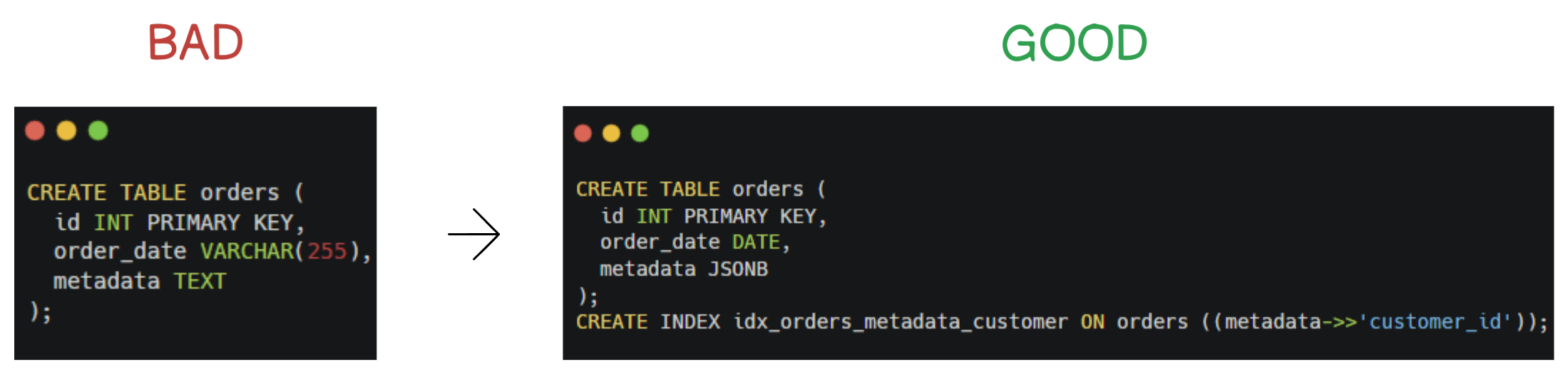
Even though both versions “work,” the second tells the database exactly what to expect.
Databases are only as smart as the hints your schema provides.
The more precise your data types, the less work your database (and your team) has to guess.
Clean, intentional typing isn’t just about performance, it’s about truth in design.
A schema that reflects reality scales longer, breaks less, and reads like documentation.
3. Build Intentional Indexes
Indexes are like caffeine; they give your queries a quick boost, but too much of them will crash your writes.
They’re one of the most misunderstood performance tools in databases.
Engineers often add them reactively, every time a query slows down, until write operations start crawling.
The key is balance: index what’s read often, not what’s written often.
This simple hierarchy helps you reason about how indexes differ in purpose and structure:
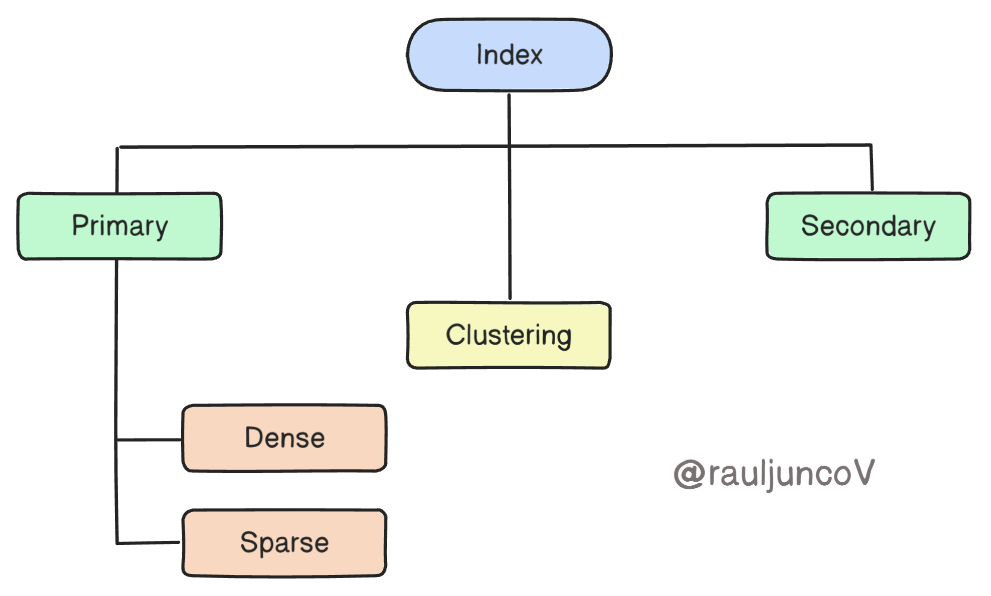
Primary vs. Secondary:
Primary indexes are built on the primary key, ensuring logical ordering of data.
Secondary indexes exist for non-primary-key lookups (like email or status).Clustering:
Determines whether data is stored physically in the same order as the index.
(e.g., In MySQL’s InnoDB, the primary key is the clustered index.)Dense vs. Sparse:
Dense indexes store an entry for every search key value.
Sparse indexes store entries for blocks of data, reducing storage but slightly increasing lookup time.
Here’s how to design them with intent:
Index columns that filter, join, or sort.
Indexes shine when they reduce search space.
If a column appears frequently inWHERE,JOIN, orORDER BYclauses, it’s a good candidate.Avoid indexing volatile columns.
Every index must be updated on every write.
Indexing frequently changing columns (likestatus,last_updated, orlogin_count) can double your write cost.
Composite indexes matter.
When queries filter on multiple columns together, a composite index performs better than separate ones.
But order matters; always align the index order with your query’s filter order.

Understand the “Leftmost Prefix” rule.
A composite index only helps when the query filters on the leftmost columns of the index definition.
If you skip the first column, the index can’t be fully used.Use covering indexes for hot paths.
A covering index contains all columns required by a query, allowing the database to serve it directly from the index without touching the base table.
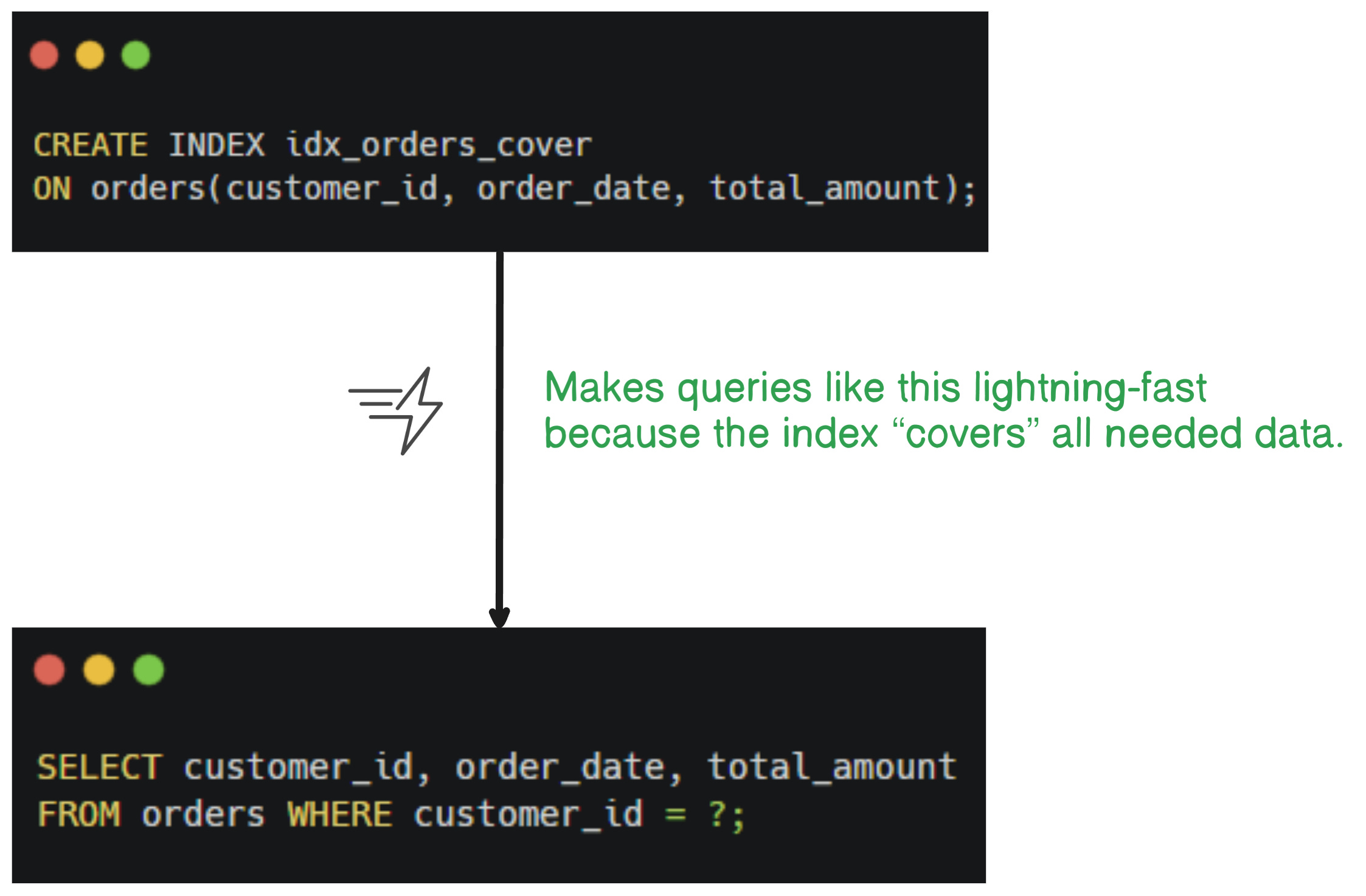
Watch out for index bloat.
Indexes take space, slow writes, and can grow faster than the data itself.
Periodically audit and drop unused indexes.
Tools likepg_stat_user_indexes(Postgres) orsys.dm_db_index_usage_stats(SQL Server) can show you which ones actually get used.Use specialized indexes when needed.
GIN/GiST indexes for JSON, arrays, and full-text search (Postgres).
HASH indexes for equality lookups on simple keys.
BRIN indexes for large, sequential data (e.g., logs or time-series).
The right index type can outperform dozens of generic ones.
A good index strategy is like caching: the wrong one helps no one, the right one changes everything.
Indexes are not about adding speed; they’re about removing unnecessary work.
Each index is a contract; a trade-off between faster reads and slower writes.
Treat them as investments, not defaults.
4. Enforce Integrity with Constraints
Most performance problems aren’t caused by the database doing too much; they’re caused by it trusting you too much.
When you skip constraints, you shift data validation from the database to the application layer.
The result?
Redundant checks, unpredictable data, and queries that have to work harder to clean up your mess.
Constraints are the foundation of both performance and correctness; because a database that knows the rules can optimize around them.
Here’s how each one helps:
PRIMARY KEY→ guarantees identity and access speed.
It enforces uniqueness and creates a clustered index (in most engines), which improves range scans and lookup consistency.FOREIGN KEY→ ensures relationships and prevents orphans.
When properly indexed, foreign keys actually improve join performance by guaranteeing referential integrity; the optimizer doesn’t have to plan for missing matches.NOT NULL→ simplifies query plans.
When a column is guaranteed to be non-null, the optimizer can skip conditional branches and null checks, producing faster execution plans.UNIQUE→ enforces business rules at scale.
It prevents duplicates early and ensures consistency without expensive application-side lookups or retries.CHECK→ enforces domain rules early.
These simple guards (e.g.,CHECK (age >= 0)) stop invalid data from ever being written, reducing downstream complexity and debugging time.
Constraints aren’t about restriction. They’re about communication; telling the database what’s impossible so it can stop checking for it.
Proper constraints lead to:
Smaller, cleaner indexes
Faster joins (less null logic and filtering)
Fewer defensive checks in code
Safer migrations and refactors
The only valid reason to skip a constraint is when the database physically can’t enforce it (e.g., external dependencies, event streams).
Otherwise, you’re just outsourcing correctness to a place with fewer guarantees and more bugs.
5. Partition What Grows Fast
Even a perfect schema will choke under scale if everything lives in one table.
Indexes get bloated, queries slow down, and maintenance becomes painful.
Partitioning is how you keep growth predictable.
It doesn’t make your database magically faster; it makes it stay fast as data volume explodes.
There are two main flavors:
Horizontal Partitioning (Sharding):
Split a large table into smaller ones that share the same schema but hold different rows.
For example, you might partition orders by region, tenant, or date range.
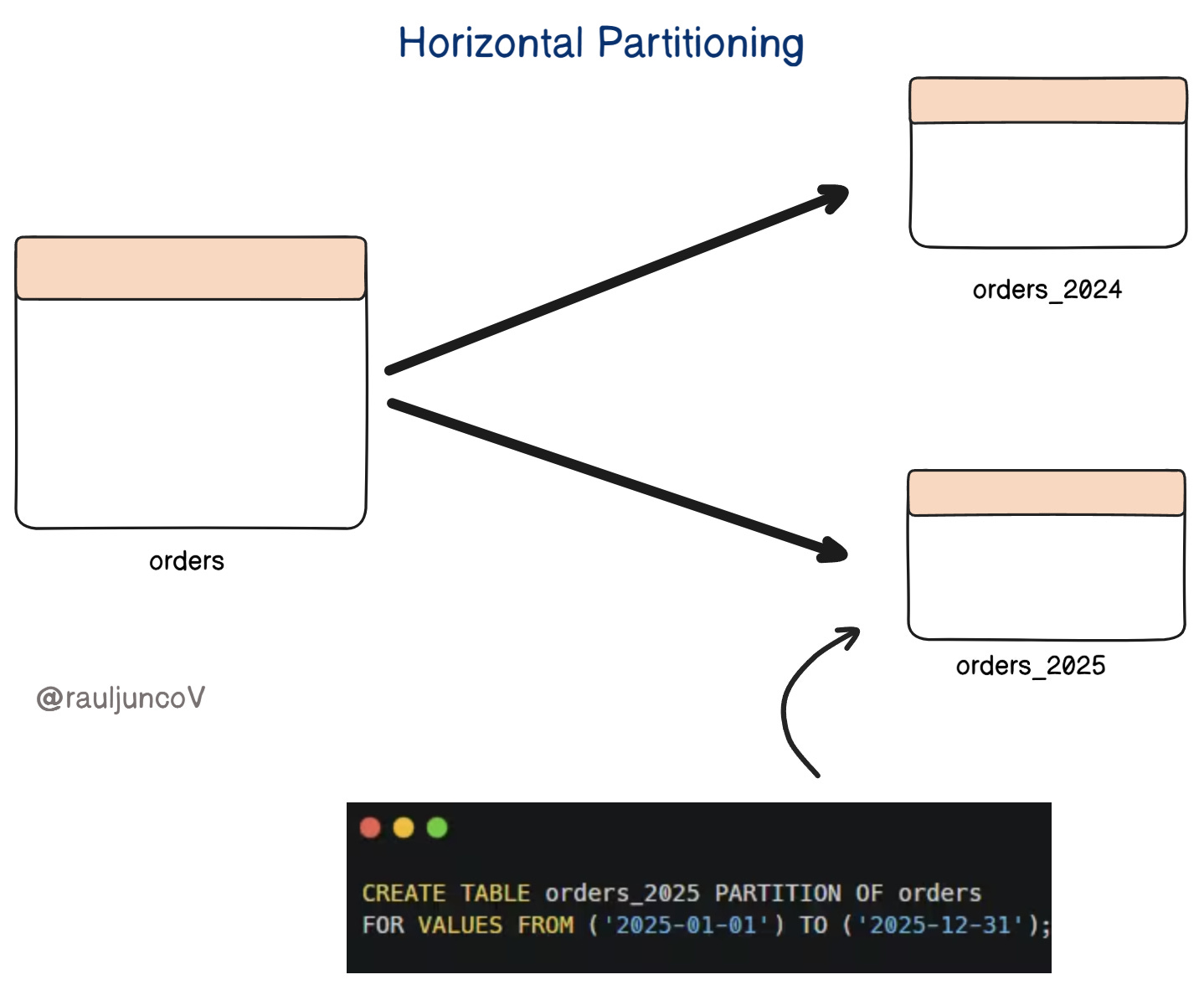
This keeps each partition small and manageable, so queries only scan what’s relevant.
In systems like Postgres, native table partitioning can automatically route inserts to the right partition and prune irrelevant ones during queries.
Time-based partitioning is especially common. It keeps operational queries fast and archival data isolated.
Vertical Partitioning:
Split columns across tables to separate “hot” from “cold” data.
Frequently accessed columns stay in the main table; large or rarely used columns move to a secondary table.
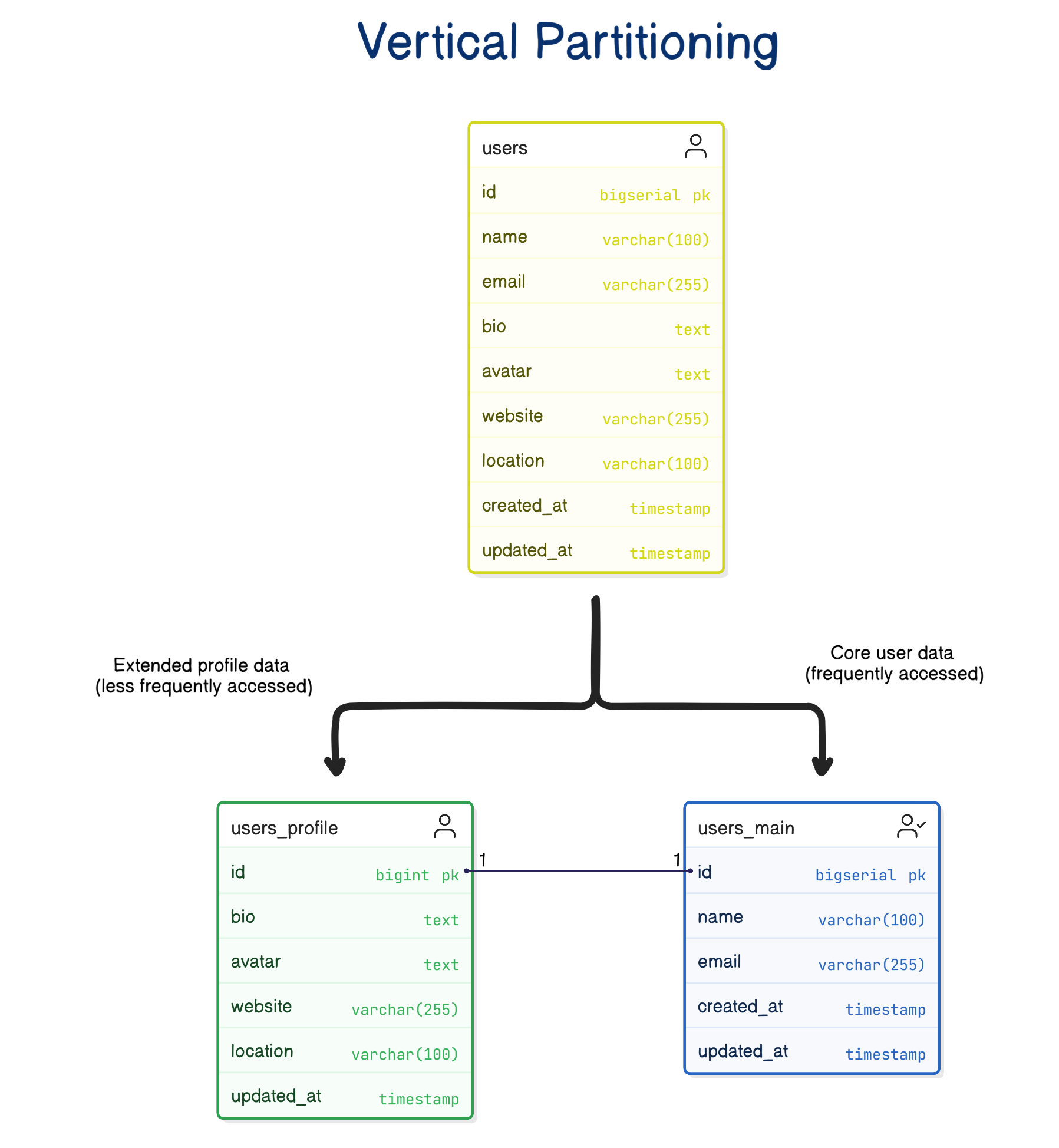
This keeps your main table lean, smaller I/O, faster scans, and cheaper caching.
When to Partition
Partitioning adds complexity, so don’t reach for it too early.
Use it when:
Your tables cross tens or hundreds of millions of rows.
Maintenance operations (vacuuming, backups, deletes) start impacting uptime.
You need data lifecycle management; archiving, pruning, or region-based compliance (e.g., GDPR).
Query performance drops even with proper indexing.
How It Improves Performance
Query Pruning: Only relevant partitions are scanned.
Faster Maintenance: You can rebuild or drop partitions independently.
Improved Caching: Smaller working sets fit better in memory.
Parallelism: Queries can run across partitions concurrently.
Partitioning doesn’t make queries faster — it keeps them from getting slower as data grows.
The Trade-offs
Partitioning comes with operational cost:
More tables to manage and monitor.
Cross-partition queries can be slower if not designed carefully.
Secondary indexes must be rebuilt for each partition.
Application logic or ORM support can complicate inserts and reads.
When done right, though, it buys you years of runway before you need to consider database sharding or distributed systems.
Partitioning is scalability’s quiet superpower; invisible when it works, painful when it’s missing.
After Almost 20 Years Designing and Re-Designing Databases
What I’ve learned is simple: databases never forget your early mistakes.
A careless column type, a missing constraint, or an unnecessary denormalization will come back, just when your system is at its busiest.
Good schema design doesn’t just make things faster; it makes them last.
The teams that win long-term are the ones who treat table design with the same respect they give code.
Some Realistic Considerations
Over-normalization can hurt read performance. Let query patterns guide final design.
Indexes require maintenance. Rebuild periodically to prevent bloat.
Constraints add minor write overhead, a small price for guaranteed correctness.
Partitioning adds complexity. Keep boundaries simple and visible.
I’ve seen teams spend weeks chasing query plans when a single redesign could’ve fixed the issue forever.
If you take one thing away, let it be this:
Performance isn’t something you tune; it’s something you design.
Until next time,
— Raul
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a paid subscriber.
I'd also add that a good design in the beginning is hard, especially when you don't know the full business context. It's good to keep things simple and extensible, + apply the mentioned tips. And ofc, don't be afraid to update later if needed.
Really enjoy, completely agree.