Relational Databases are so good at joining data that we often forget until we miss our JOINs.
Breaking the database apart is one of the most complex tasks.
When you move to microservices, you realize how hard it is to replicate that efficiency. Since all those JOINs will become inter-communication calls, adding a performance tax.
Let's review an example and a practical approach.
Thank you to our sponsors who keep this newsletter free:
Multiplayer's Platform Debugger provides deep session replays with every detail you need to find and fix a bug. From Frontend screens to Backend traces, metrics, and logs, all in one place. Debug faster and fix customer problems more easily, so you and your team can stay focused on building great software, not combing through APM data.
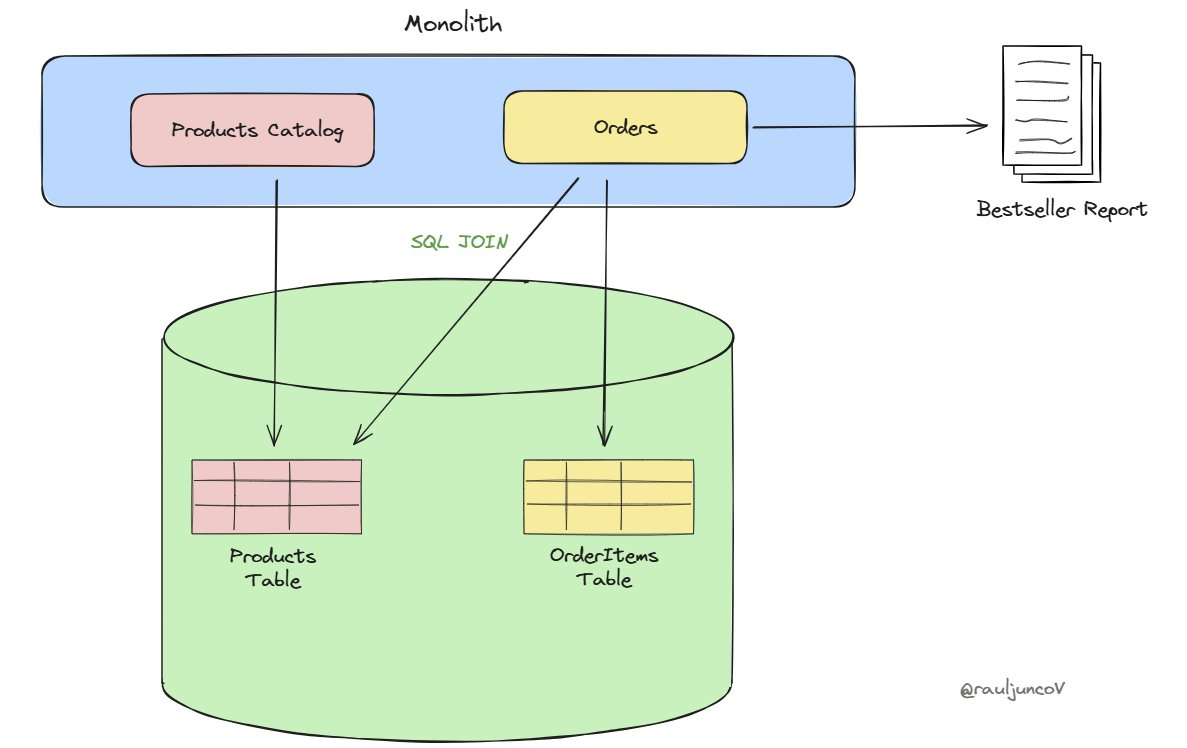
Picture an online bookstore that's growing fast. At first, the system runs on a single database. Does the marketing team need a "Bestseller Report"? No problem. A simple query combines data from the Products and Orders tables, and the report is ready in seconds.
As your store grows, the system needs to scale. It switches to microservices.
Now, Product data lives in the Products Catalog Microservice, and Order data sits in the Orders Microservice. To create the same report, you have to query Orders first, then call Products for details on each unique item.
Even if you group these calls, network latency slows everything down. What used to take milliseconds now requires more effort and time, making it much harder to deliver fast reports.
We've gone from our handy JOIN to an HTTP call, and the latency has grown exponentially.
Although, it comes with its own set of challenges:
Pros:
Services can work faster by using local data, skipping cross-service calls.
Systems stay available even if one service is down, as they don't rely on live data from others.
Cons:
Keeping data in sync becomes harder. Updates need to be shared across copies.
You use more storage because you're saving the same data in multiple places.
Data replication is not only a solution for reducing latency but also highly useful during migration stages.
When transitioning from a monolithic architecture to microservices, replicating data allows new services to operate independently while still accessing the necessary information.
This temporary duplication ensures that the migration process doesn't disrupt existing functionality.
Other Ways to Solve the JOIN Problem
1. Materialized Views
Think of this as a separate database just for reports. It stores pre-processed data that's updated when something changes in Products or Orders.
Reports are fast because they only read from this optimized source. However, the data may not always be up-to-date because of delays in syncing.
2. Event-Driven Replication
Imagine the Products Service announces every update, like a news broadcast. The Orders service listens and keeps a local copy of important details.
When you create a report, you get all the data from Orders without calling Products. This reduces latency but requires careful planning to ensure accuracy.
3. Batch Data Sync
This approach works like a nightly routine. Every night, the system gathers data from all services, processes it, and stores it in a central database for reports.
The reports run quickly and consistently but won't show real-time updates.
Some Takeaways:
For real-time needs, Replication, Materialized Views, or Event-Driven replication work well. For occasional reports, batch syncing keeps things consistent without overloading your system.
Moving from a monolithic database to microservices introduces both opportunities and challenges. While microservices improve scalability and flexibility, they require rethinking not just the Domain but how data is accessed and managed.
No solution fits every scenario. Focus on understanding your system's specific performance, consistency, and scalability needs.
Document your decisions and revisit them as your architecture evolves.
Joins are the simplest way to fetch data from different sources. The moment we can't use them (due to microservices), the other solutions involve eventual consistency which can be tricky to handle. The trade-offs should be considered.
Very good article. One way to use option 3 (batch data sync) in a systematic way in a corporation is by using the Data Mesh model. It is quite challenging to implement, but once the main services are ready, it starts to generate benefits quickly for the organization.






Nice explanation Raul.
Joins are the simplest way to fetch data from different sources. The moment we can't use them (due to microservices), the other solutions involve eventual consistency which can be tricky to handle. The trade-offs should be considered.
Thanks for the mention as well!
Very good article. One way to use option 3 (batch data sync) in a systematic way in a corporation is by using the Data Mesh model. It is quite challenging to implement, but once the main services are ready, it starts to generate benefits quickly for the organization.