
Most Engineers Want Both Consistency and Scalability.
Reality Doesn't Work That Way.
If you’ve ever tried to process payments across multiple services or coordinate seat reservations during a flash sale, you know the pain:
Some users double-book.
Others get stuck in “processing” forever.
And your pager lights up at 2 AM.
That’s the cost of ignoring distributed transaction design.

You get choices. You don’t get them all.
Let’s talk about the Three Big Guns in distributed transactions:
Two-Phase Commit (2PC)
Saga with Orchestrator
Saga with Choreography
Each solves the same problem: keeping distributed workflows safe.
Each comes with brutal trade-offs.
As developers increasingly turn to CLI coding agents like Claude Code for rapid development, a critical gap emerges: who reviews the AI-generated code?
CodeRabbit CLI fills this void by delivering senior-level code reviews directly in your terminal, creating a seamless workflow where code generation flows directly into automated validation. Review uncommitted changes, catch AI hallucinations, and get one-click fixes - all without leaving your command line.
It’s the quality gate that makes autonomous coding truly possible, ensuring every line of AI-generated code meets production standards before it ships.
Two-Phase Commit (2PC): The Illusion of Atomicity
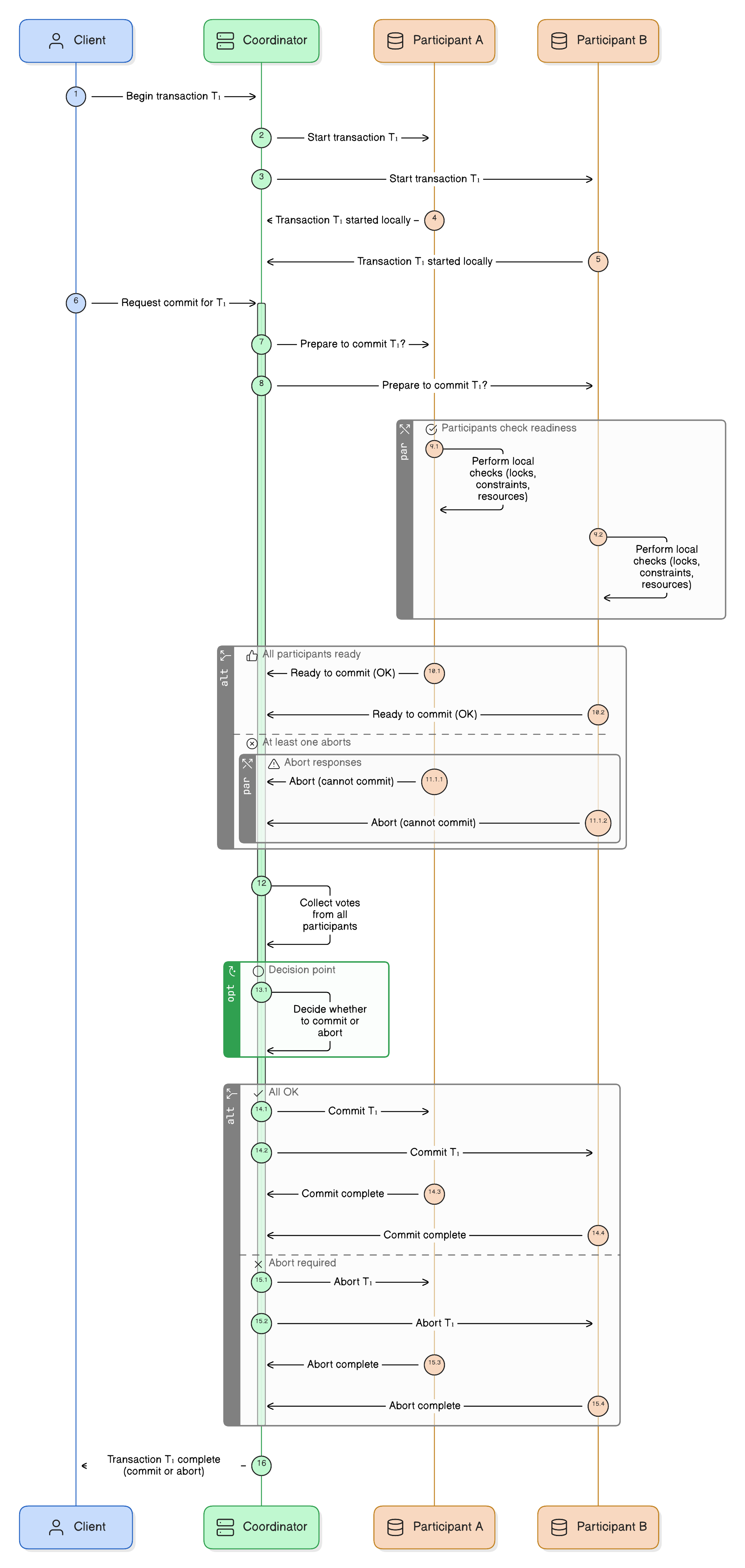
2PC coordinates a distributed transaction by introducing a “transaction Manager/Coordinator.” Each participant (database, service, or resource) is asked to prepare first. If all of them vote yes, the manager sends a final commit message. If any vote no, everyone rolls back.
What it delivers:
Strong consistency: either all commit, or none do.
Simplicity in mental model; behaves like a local ACID transaction.
The cost:
Adding more participants degrades performance. Every resource is locked until the final decision.
Global locks block unrelated work. A single slow participant stalls the entire transaction.
Coordinator failures leave transactions “in doubt,” requiring manual intervention or complex recovery logic.
If the Coordinator crashes after prepare, but before broadcasting the decision, the entire algorithm is blocked until the Coordinator recovers.
It’s like asking every wedding guest to raise their glass for a toast at the exact same moment. The picture looks perfect, until one late uncle delays everyone.
When to use:
Small, short-lived transactions where correctness outweighs throughput, such as seat reservations or atomic money transfers.
When not to use:
Anything requiring scale across services or regions. Throughput will collapse.
Saga with Orchestrator: Control Through Compensation
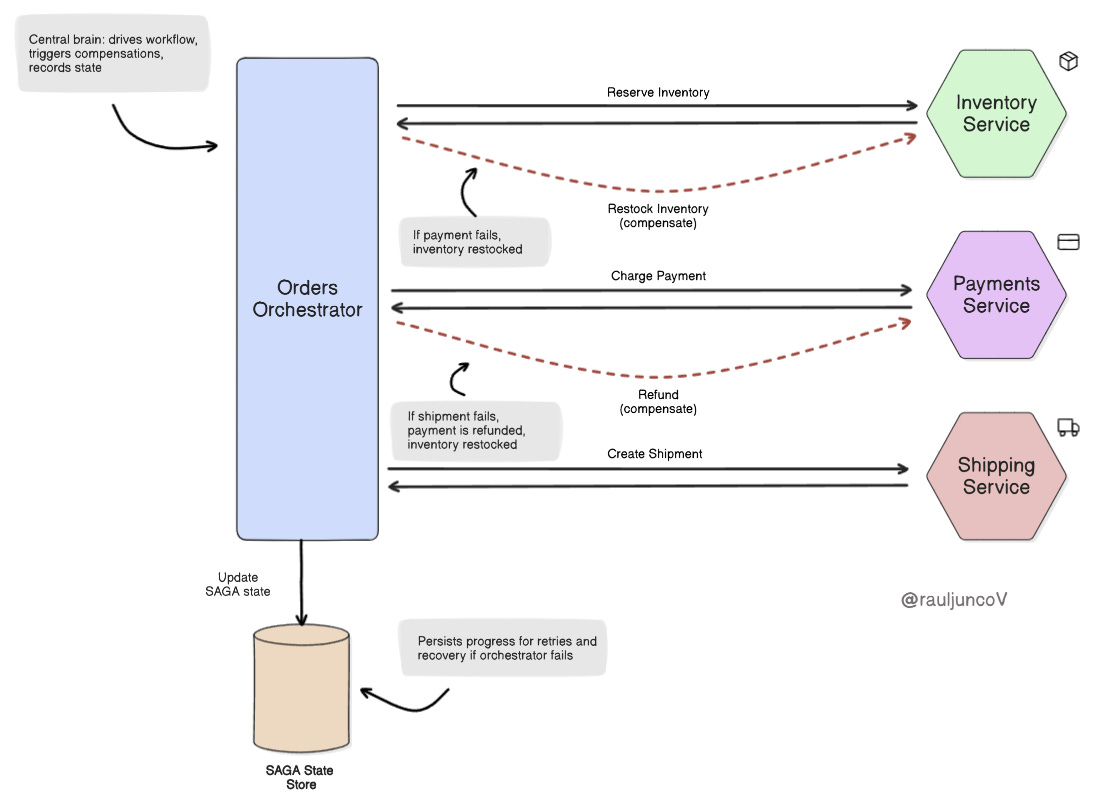
An orchestrator does things differently. Instead of enforcing atomicity with locks, a Saga breaks a workflow into independent steps. A central orchestrator issues commands in order: “reserve inventory,” “charge payment,” “create shipment.” Each step has a compensating action (undo payment, restock inventory) if something fails.
What it delivers:
Business-level atomicity. Failures unwind with compensations rather than strict rollbacks.
Visibility: the orchestrator provides a timeline, retry logic, and consolidated monitoring.
Reliability under flaky conditions: compensating actions make the system resilient to partial failures.
The cost:
The orchestrator itself becomes a target for scaling and reliability.
Every service must implement both “do” and “undo,” doubling the contract surface area and the testing burden.
State persistence, retry policies, and orchestration logic are non-trivial engineering work.
Think of a travel agent. They book your flight, hotel, and car in sequence. If the hotel fails, they cancel the car and refund the flight. The customer never sees the failure; they just get a consistent experience.
It is perfect for complex, multi-step workflows that map to real-world business processes, like e-commerce orders or financial transactions.
Saga with Choreography: Autonomy at Scale
Choreography removes the central brain. Services publish events, and other services react. For example:
Order Service publishes “Order Created.”
Payment Service reacts and emits “Payment Completed.”
Shipping Service reacts and schedules delivery.
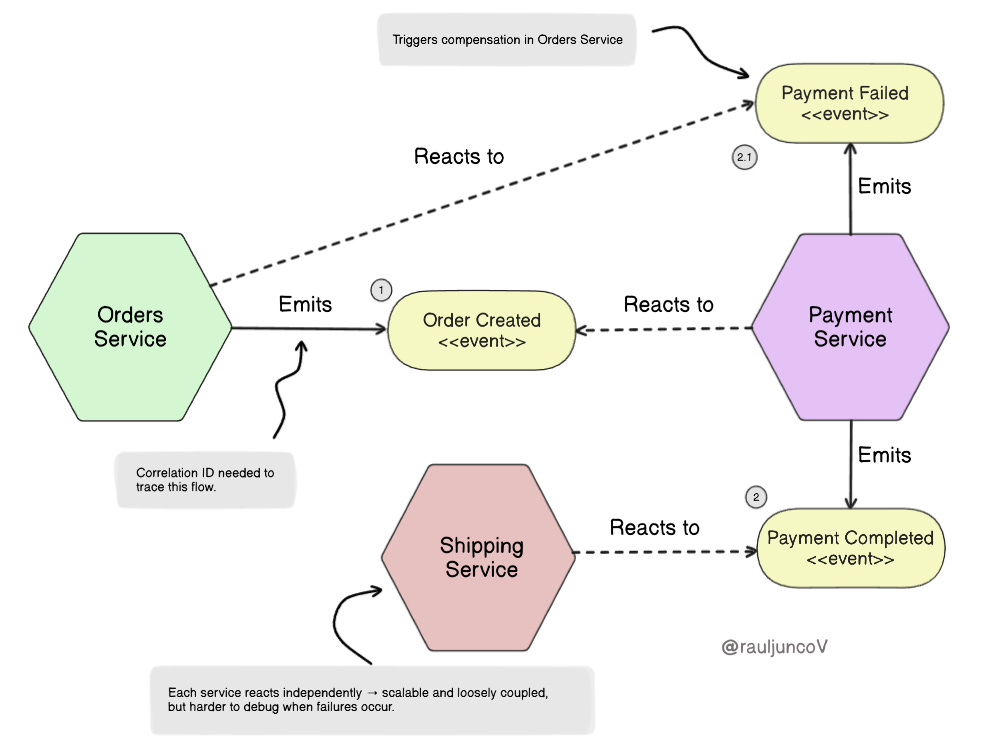
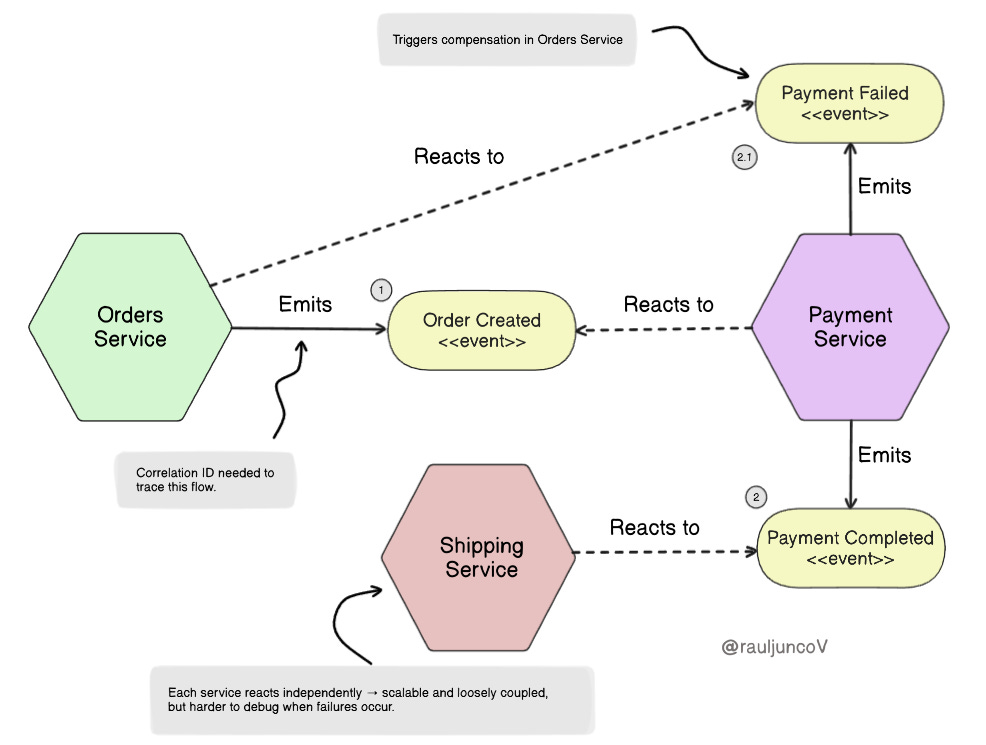
The workflow emerges from the event flow rather than a central authority.
What it delivers:
Loose coupling. Teams own services independently and deploy without coordination.
Horizontal scalability. Adding new participants is as simple as subscribing to the event stream.
High autonomy. Systems evolve faster because no single orchestrator dictates flow.
The cost:
Eventual consistency. Data may take time to settle, and systems must be able to tolerate temporary divergence.
Debugging becomes difficult. Tracking who triggered what and when requires strong observability.
Each service manages its own compensations; it must know how to undo its own work.
Adding more services increases the risks of event storms, feedback loops, and hidden dependencies.
It works really well for autonomy. Large-scale systems with autonomous teams, where independence and scale are more important than immediate consistency.
Practical Considerations Beyond the Patterns
Event Storms and Hidden Dependencies
Choreography scales by removing the central brain, but the price is unpredictability. Poorly designed event chains can create storms: one service reacts, triggers another, which triggers the first again.
The loop grows until queues overflow. This isn’t theory; it happens when services emit broad events like Order Updated without clear contracts.
The fix: design events narrowly, enforce idempotency, and monitor for abnormal event volume.
Observability and Debugging
Distributed workflows are only as reliable as your ability to see them. Without end-to-end tracing, you must guess which service failed and when. Use correlation IDs in every event. Centralize logs for compensations and retries.
Add distributed tracing to visualize entire sagas across services. And don’t stop there, automated anomaly detection can catch unusual retry patterns before they become outages.
Choosing the Right Pattern
No single approach wins everywhere.
2PC fits short, critical operations where correctness beats throughput.
Orchestrator sagas shine when workflows need predictable undo steps.
Choreography works when autonomy and scale outweigh strict consistency.
Most real systems mix patterns. Payments might use strong consistency, while downstream shipping notifications settle eventually.
Map requirements, data criticality, latency tolerance, traffic volume, to the pattern that fits.
Failure Recovery in Practice
Every system fails. Recovery is the differentiator.
2PC needs recovery logs and leader election to survive Coordinator crashes.
Sagas need thoroughly tested compensations and idempotent steps so retries don’t double-charge or restock twice.
Transactional outbox and idempotency keys are battle-tested tools that make retries safe and events reliable.
Where the Industry is Heading
Modern systems rarely stop at 2PC or Sagas. Patterns like CQRS, event sourcing, and the transactional outbox are becoming standard ways to balance consistency with scalability.
They don’t eliminate the trade-offs; you still pay, but they shift the costs to places you can manage more easily.
If your system is stretching, these are the next patterns to explore.
The Trade-offs You Cannot Escape
Each pattern buys you one benefit by forcing you to accept a cost.
Two-Phase Commit gives you the strongest consistency guarantees: either all participants commit, or none do. That makes it the safest option when correctness is non-negotiable.
But the cost is scalability. Global locks stall unrelated work, a single slow participant blocks the group, and cross-region use is nearly impossible. You trade throughput and resilience for atomic truth.
The Orchestrator Saga provides centralized control. The workflow is visible, compensations are predictable, and the system mirrors real business logic, refunds, cancellations, and restocks.
The downside is complexity. You must build and operate the orchestrator itself, and every service must support both forward and undo actions. The price of control is additional engineering overhead.
Choreography pushes autonomy and scale. Services react to events, teams ship independently, and you can add new capabilities without central coordination.
But you inherit the mess of distributed compensations and debugging event chains. Consistency becomes eventual, not immediate. The gain is speed and independence; the trade-off is clarity.
In short:
2PC → Strong guarantees, but poor scalability.
Orchestrator Saga → Predictable rollbacks, but central complexity.
Choreography Saga → Scalable autonomy, but messy debugging.
The real question is which cost you’re willing to pay: latency, complexity, or chaos.

Outages don’t come from picking the wrong pattern. They come from pretending trade-offs don’t exist
Until next time,
— Raul
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a paid subscriber.
Love the detailed explanation, great work!
Loved the visuals as always, keep these coming brother!