
Good System Design Starts With Constraints, Not Diagrams, Not Tools
Most Engineers Learn System Design Backwards

Many engineers study system design from the wrong end.
They start with Kubernetes. Then microservices. Then queues. Then service meshes. Then they memorize diagrams full of boxes, arrows, and cloud logos.
But when a real system gets slow, unstable, or expensive, they struggle to explain what is actually going wrong.
Why did latency spike?
Why did retries make the outage worse?
Why did the database collapse even after adding more app servers?
Why does everything look healthy on dashboards while users still get the wrong behavior?
That happens because system design is not really about diagrams or tools.
It is about constraints.
If you do not understand the forces underneath the system, the architecture picture gives you confidence without understanding. It helps you describe the system, but not reason about it.
The tax you pay to run multiple agents
If you’ve spent any time with coding agents, you know the feeling. You start the morning with a clean plan. Spin up a few agents. One is refactoring the auth module. Another is writing tests. A third is scaffolding a new API endpoint. You’re flying.
Then, around 10:30 AM, you look up and realize you have 20 terminal windows open. One agent is blocked waiting for a decision you forgot to make. Another finished 40 minutes ago, and you never noticed. A third went sideways three commits back. You’re no longer flying. You’re drowning.
You’ve shifted from human as driver to human as director. When running coding agents in parallel, the bottleneck isn’t just context. It’s your own attention trying to manage 10 agents across 10 terminals. You’re losing your mind to terminal chaos.
Meet Cline Kanban, a CLI-agnostic visual orchestration layer that makes multi-agent workflows usable across providers. Multiple agents, one UI. It’s the air traffic controller for the agents you’re already running, regardless of where they live.
Interoperable: Claude Code and Codex compatible, with more coming soon.
Full Visibility: Confidently run multiple agents and work through your backlog faster.
Smart Triage: See which agents are blocked or in review and jump in to unblock them.
Chain Tasks: Set dependencies so Agent B won’t start until Agent A is complete.
Familiar UI: Everything in a single Kanban view.
Stop tracking agents and start directing them. Get a meaningful edge with the beta release.
Install Cline Kanban Today: npm i -g cline

The real issue with how system design gets studied
The problem is not a lack of resources. Engineers have more books, videos, posts, and courses than ever. The real issue is that many people learn solutions before they understand the problems those solutions were built to solve.
They learn microservices before they understand network cost.
They learn queues before they understand duplication and ordering.
They learn caching before they understand staleness and invalidation.
They learn replication before they understand read and write access patterns.
That sequence creates a tool-first mental model. And it sounds sophisticated, but it usually breaks under pressure.
In practice, systems often fail for much simpler reasons. A service calls too many dependencies. A query is inefficient. An index is missing. A partition key is skewed. A retry policy multiplies traffic. A cache serves stale data. A queue grows without control. A hot path lacks ownership.
None of those problems looks glamorous, but they shape whether a system survives production. Yes, sophisticated-looking architectures can still fail in predictable ways. The team chose modern components but never built a clear understanding of the forces underlying them.
That is why the order of learning matters so much.
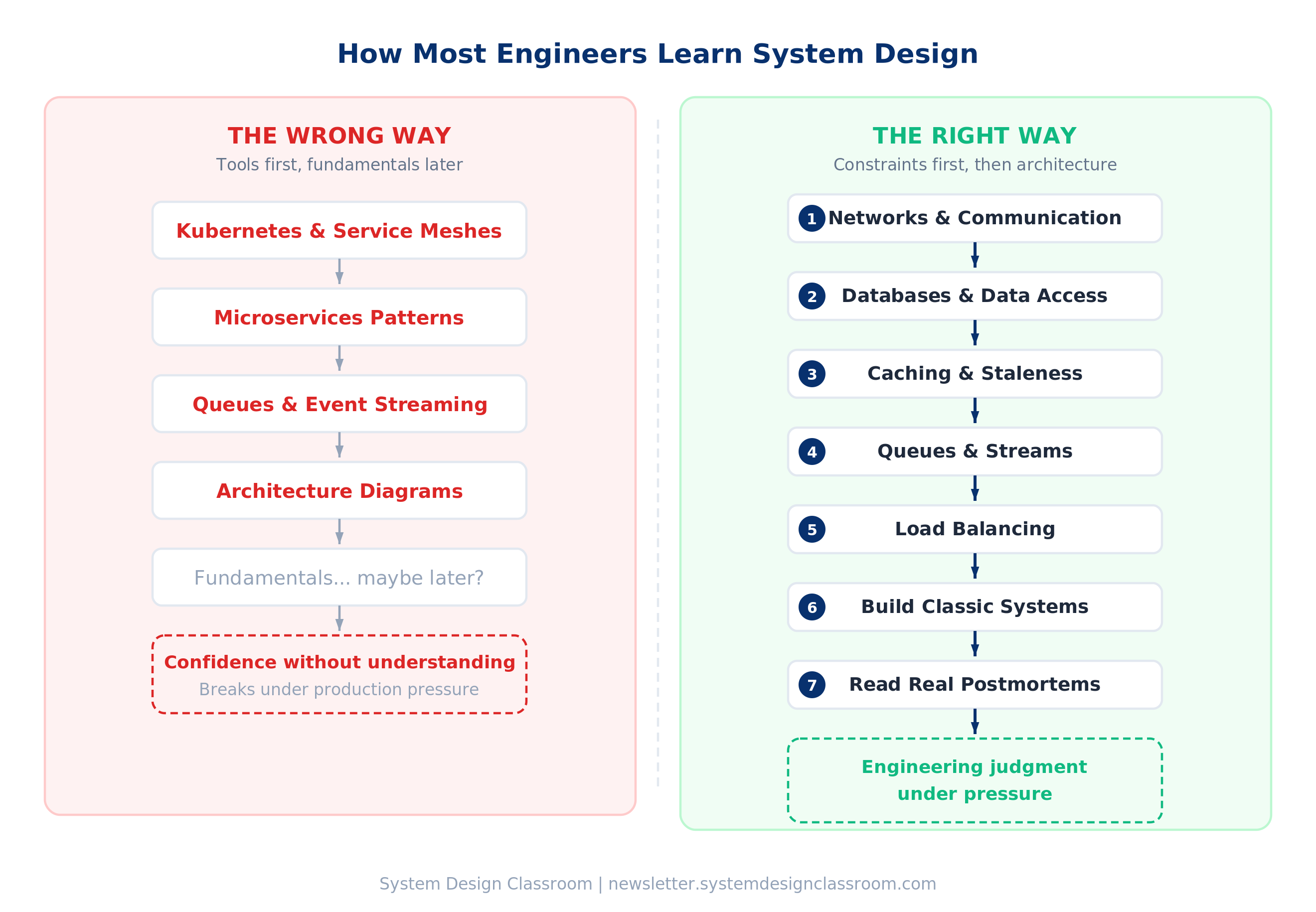
The order that actually builds intuition
If your goal is real system design judgment, the most useful sequence is much more grounded:
Start with networks
Then move into databases
Then study caching
Then queues and streams
Then load balancing
Then build a few classic systems
Then read postmortems and failure reports
This order works because each layer depends on the one below it. If you skip the lower layers, everything above turns into memorization. If you understand the lower layers, the upper layers naturally begin to make sense.
That order matters, but there is one thing that comes even before it: being clear on what problem you are actually solving.
But before all of that, learn to ask for requirements
Even the best technical foundation will not help much if you skip the first step: understanding the problem.
You need to know what matters most, what can bend, and what absolutely cannot fail.
Good system design starts with questions.
Is this system read-heavy or write-heavy?
Do we care more about latency or consistency?
How fresh does the data need to be?
Is traffic steady, or does it arrive in bursts?
What is the expected scale?
What is the budget?
What is the recovery expectation when something goes wrong?
Those questions shape everything that comes after.
And this is the part many engineers miss: every requirement is a trade-off in disguise.
“The system must be fast” sounds simple until you realize what it usually means. Speed often competes with consistency. A read that returns stale data is fast. A read that coordinates across multiple replicas is safer, but slower. In real systems, you rarely get everything at once.
The first skill in system design is deciding what you are willing to sacrifice.
A read-heavy system pushes you toward caching.
A write-heavy system pushes you toward coordination.
A bursty workload makes queues and backpressure more important.
A low-latency system makes every network hop more expensive.
A system with strict consistency requirements changes how safely you can use replicas, async flows, and stale reads.
This is where many system designs go wrong.
Engineers jump from a vague problem statement to an architecture too quickly. They start suggesting tools before they understand the actual constraints. But requirements are what tell you which constraints matter most.
That is why asking good questions is part of system design, not something that happens before it.
Requirements tell you what matters.
Fundamentals tell you why it matters.
Architecture is what you choose because of both.
And once you understand that, the next thing to study is the layer every distributed system depends on first: communication.
Networks Explain Everything Else
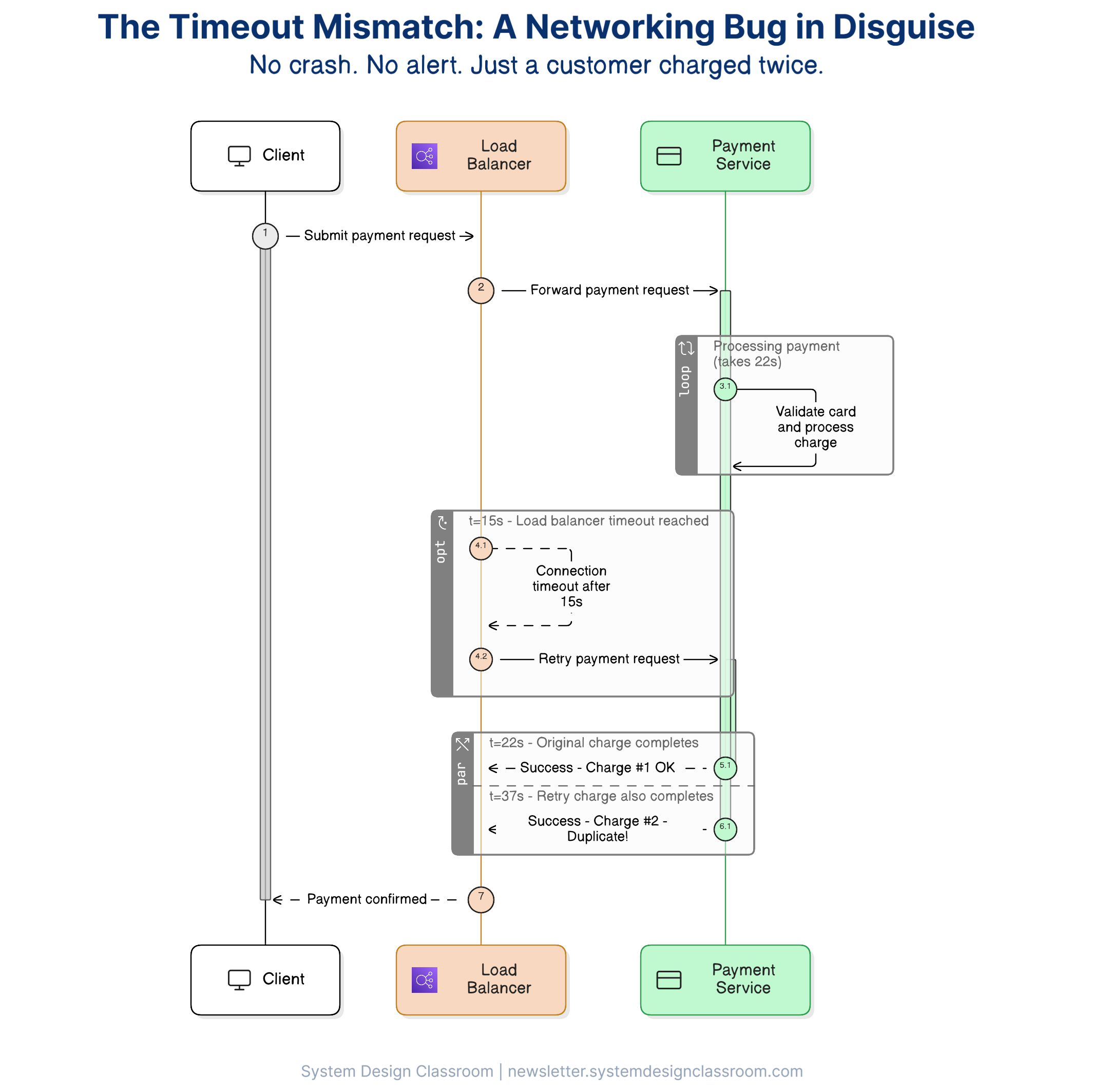
An engineer sets a 30-second timeout on an HTTP call to a payment service.
What they do not realize is that the load balancer upstream times out after 15 seconds.
At second 15, the load balancer cuts the connection and retries the request.
The original call is still running.
There are now two requests in flight.
The payment goes through twice.
No obvious application error.
No crash.
No red alert on the dashboard.
Just a clean wall of 200s and a customer who got charged twice.
That’s a networking bug wearing a business logic disguise, and it’s exactly why networking matters so much in system design.
This is what an innocent‑looking timeout mismatch really does under the hood.
It is also one of the most neglected topics in how engineers learn distributed systems.
Every request that leaves one machine and reaches another carries costs and risks. The moment your system crosses a network boundary, latency becomes real, partial failure becomes possible, retries become dangerous, and duplication becomes something you have to design for.
If you do not understand what happens when bytes leave one machine and travel to another, a lot of your architecture decisions end up resting on assumptions you cannot verify.
That is why networking should come first.
A local function call is fast and predictable. A network call is slower, less predictable, and full of edge cases that only show up under pressure. That difference changes everything.
It changes how you think about service boundaries. It changes how you think about retries. It changes how you think about failure. And it changes how expensive “just one more network hop” really is.
Once you understand the cost of communication, the next question becomes just as important: how the system stores and retrieves data.
Then learn databases
If networks explain how systems communicate, databases explain how systems remember.
A huge amount of system design is really about how data is modeled, accessed, coordinated, and maintained under load. The consequence is that shallow database advice creates so much damage. It is easy to say “use NoSQL for scale” or “add replicas,” but without understanding the fundamentals, those ideas turn into expensive guesses.
You need to understand relational and non-relational models, indexes, query plans, transactions, isolation, replication, and partitioning. Not because every system needs every one of those concepts, but because these are the things that explain why systems behave the way they do.
Many systems do not really have a scale problem. They have a data access problem. The query is inefficient. The index does not match the filter pattern. The primary handles too many reads. The write path needs too much coordination. The partition key creates a hotspot. The model fights the access pattern.
This is also where one of the most important habits in system design begins: thinking separately about reads and writes.
Reads are often easier to scale. You can cache, replicate, precompute, and sometimes serve them from the edge. Writes are harder. Writes need coordination. Writes need durability. Writes need consistency rules.
This is also where ideas like the CAP theorem stop feeling abstract.
A write lands on one node, but replication has not finished yet. A read goes to another node and gets stale data. At that point, the trade-off is no longer theoretical. You can wait for replication and pay the latency cost, or you can serve the stale read and accept temporary inconsistency.
There is no magical third option.
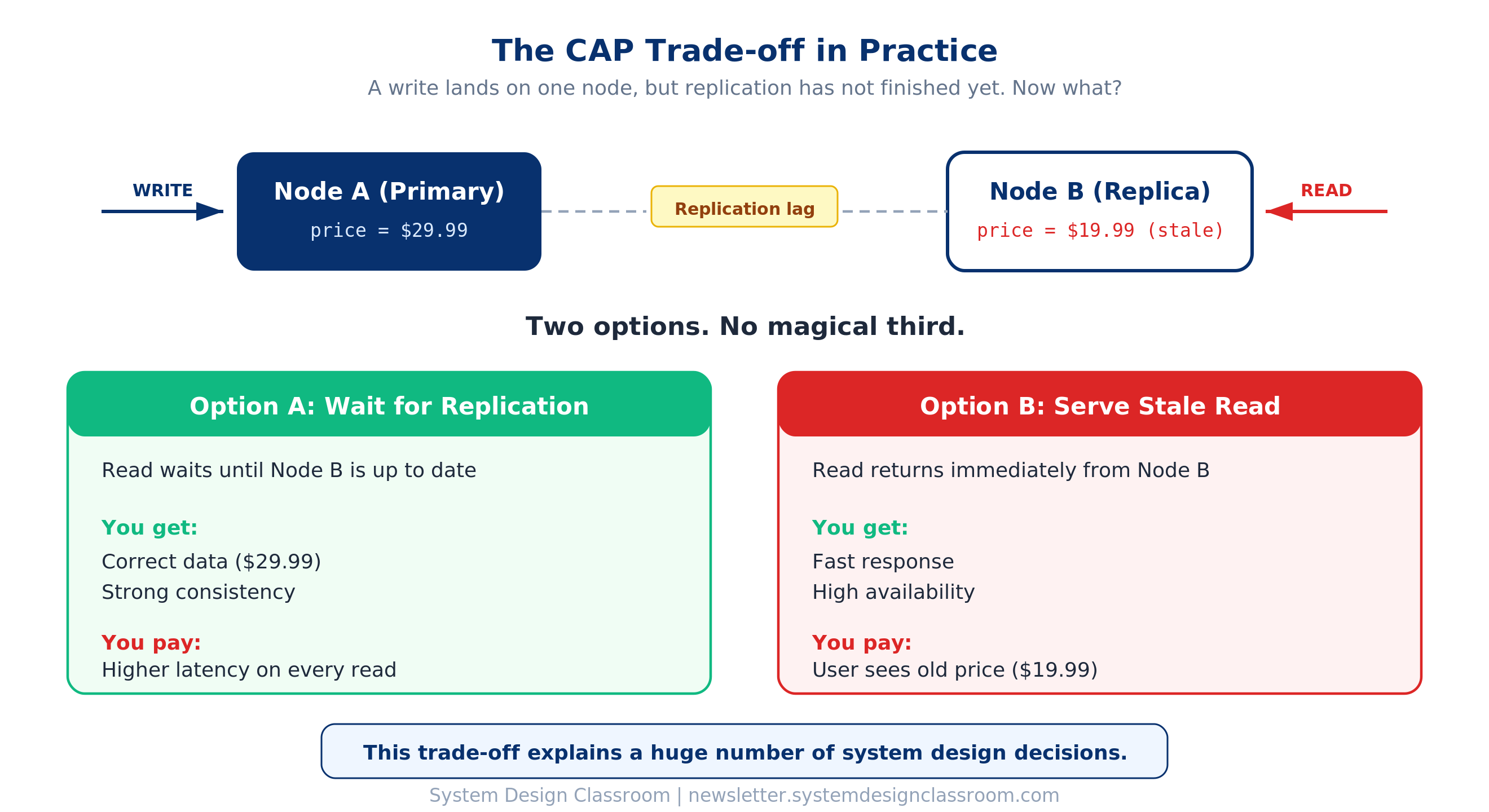
That trade-off explains a huge number of system design decisions. It explains why some systems choose replicas and eventual consistency. It explains why others keep reads close to the primary. It explains why low latency and perfect freshness often pull in opposite directions.
If you cannot reason about the write path, you cannot really reason about the architecture.
And once you understand how costly repeated reads can become, the next step becomes obvious: avoiding unnecessary work.
Then learn caching
Caching is probably the clearest example of a system design trade-off.
You are trading correctness for speed.
Every cached value is a bet that the underlying data will not change before the cache expires. Sometimes that bet pays off, and the system gets much faster at a very low cost. Sometimes it does not, and a user sees a price that no longer exists, clicks buy, and your support team spends the afternoon apologizing.
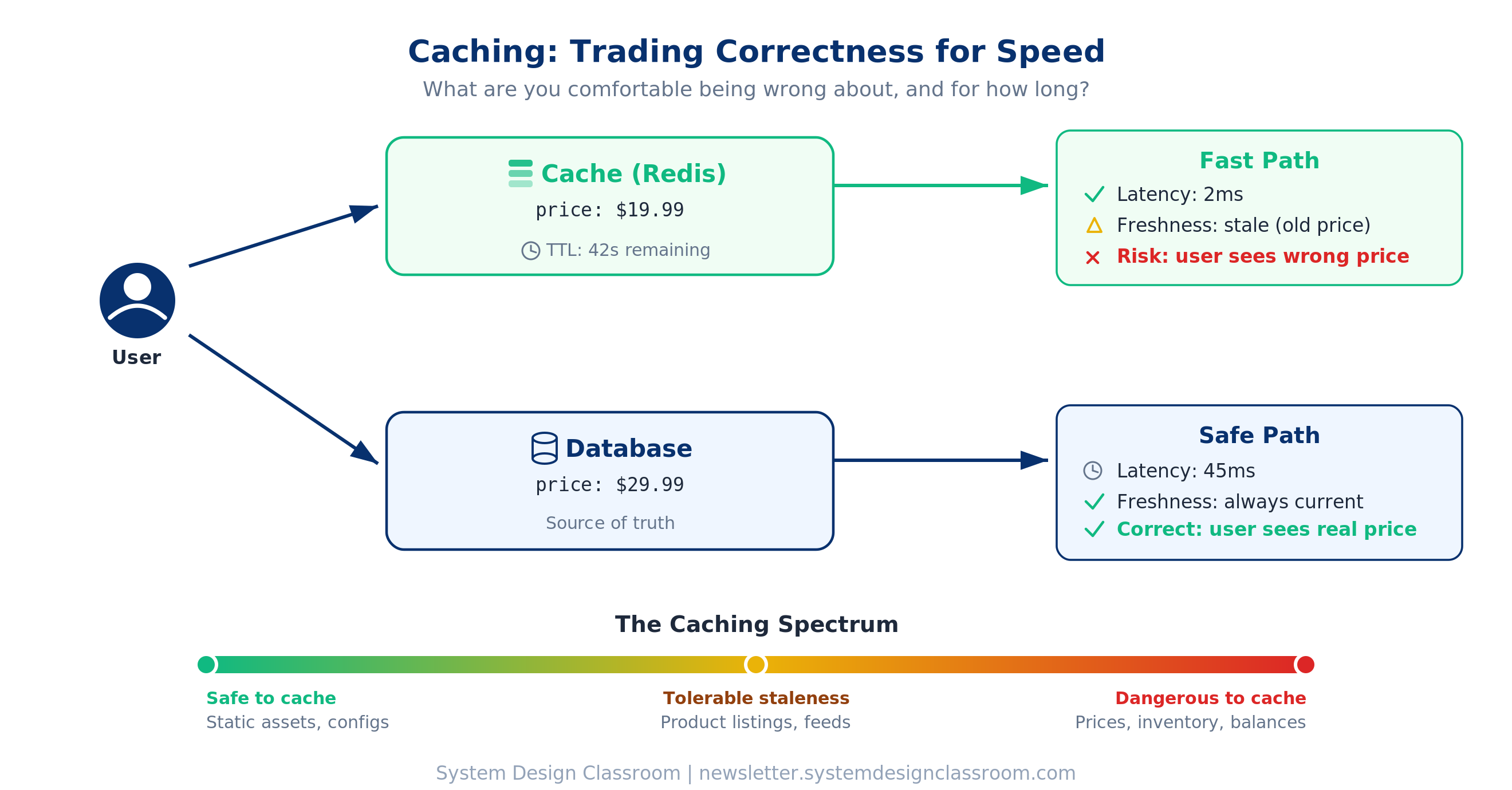
This is the reason caching matters so much in system design. It forces you to answer a harder question than “should we cache?”
The real question is: what are we comfortable being wrong about, and for how long?
That is what makes caching more than a performance trick.
It is a judgment call.
A lot of engineers first meet caching as an easy win. Put Redis in front of the database. Add a CDN. Set a TTL. Watch latency drop. And sometimes that really is the right move. Caching can remove repeated work, reduce pressure on the database, and give you some of the cheapest performance improvements in the system.
But the moment you cache something, you also accept a new kind of risk.
You accept that the fast answer may not be the latest answer.
You accept that invalidation may be harder than storage.
You accept that two users may see different realities for a short period of time.
Caching only works well when you understand the shape of the data and the cost of being wrong.
Some data is ideal for caching because it changes so little.
Some data can tolerate staleness because the business impact is low.
Some data looks cacheable until the first bad customer experience makes the trade-off painfully real.
That is the real lesson.
Caching is not just about speed. It is about deciding where freshness matters, where it does not, and how much inconsistency the system can tolerate without breaking trust.
Once you understand that, caching starts to look like what it really is: a trade-off among latency, freshness, and complexity.
And even after you reduce repeated reads, one big problem remains: what happens when too much work arrives at once?
Then learn queues and streams
Once you understand request-response systems, the next major shift is learning how to decouple time.
Queues and streams matter because they let you move work off the critical path. Instead of forcing every piece of work to complete during the user request, they let the system defer non-critical tasks, smooth out spikes, and scale consumers independently.
This is one of the cleanest ways to protect the application’s hot path.
This is why asynchronous systems are so powerful. They help absorb traffic bursts, isolate failures, and prevent slow downstream dependencies from dragging down the user-facing experience. But they do not eliminate complexity. They relocate it.
That part often gets learned too late. As soon as you introduce asynchronous processing, you also introduce duplicate delivery, out-of-order events, replay behavior, tracing complexity, idempotency requirements, and eventual consistency.
The system may become more resilient under load, but it also becomes harder to reason about.
That does not make queues a bad choice. It simply means they are a trade-off. They buy resilience and throughput at the cost of immediacy and simplicity. Once you understand that trade clearly, you can choose async patterns for the right reasons instead of treating them like a default upgrade.
As traffic spreads across multiple services, consumers, and workers, another challenge becomes unavoidable: deciding how to distribute work across infrastructure without creating new bottlenecks.
Then learn load balancing
A lot of engineers hear “the system is overloaded” and immediately think, “add more servers.”
Sometimes that works. A lot of the time, it does not.
If the database is already saturated, more app servers will just create more traffic against the same bottleneck. If your workers are slow because downstream writes are struggling, adding more workers may just increase contention faster. If the cache hit rate is poor, spreading requests across more instances does not fix the real problem.
That is why load balancing is easy to oversimplify.
Yes, it distributes traffic. But the real lesson is not “send requests to many servers.” The real lesson is understanding what kind of load you are distributing, how it should be distributed, and whether the rest of the system can absorb it.
That is where details start to matter. Round robin, least connections, sticky sessions, health checks, failover behavior, consistent hashing. These are not just implementation details. They shape whether traffic spreads intelligently or whether the system keeps pushing work into the wrong place.
Load balancing helps you scale horizontally, but only when you understand where the bottleneck actually lives. Otherwise, you are just moving pressure around and hoping it looks like progress.
That is what makes load balancing a useful learning topic. It teaches you that scaling is not about blindly adding machines. It is about controlling where work goes and knowing which layer actually needs help.
And once these building blocks start making sense, the best way to make them stick is to build with them yourself.
Build classic systems yourself
Reading helps. Courses help. Videos help. But building is what forces the ideas to stick. The moment you try to design even a “simple” system yourself, you stop thinking in labels and start thinking in constraints.
Take a rate limiter.
At first, it sounds easy: allow 100 requests per minute and block the rest. But the moment you try to build it, the real questions show up.
Where do you store the counters?
What happens if multiple servers increment the same key at the same time?
Do you reset counts with a fixed window, or use a sliding window that is more accurate but more expensive?
Do you optimize for speed, or for fairness?
What happens if the limiter itself becomes a bottleneck?
Now you are not just building a small feature. You are dealing with atomicity, concurrency, latency, memory growth, and correctness under load. A local in-memory limiter is fast, but breaks across multiple instances. A centralized Redis-based limiter is more consistent, but adds a network hop and a dependency on another system. Even here, the design is still about trade-offs.
Building these kinds of systems matters. They force you to apply the exact lessons that look abstract on paper.
A few classic systems are especially useful:
A URL shortener teaches you how to think about key generation, read-heavy traffic, redirects, and cache-friendly design.
A chat application teaches you how to reason about persistent connections, fan-out, ordering, and message delivery.
A feed system teaches you how to think through fan-out on read vs fan-out on write, ranking, and precomputation trade-offs.
A notification system teaches you how to design for retries, idempotency, provider failures, and backpressure.
Practice builds judgment.
Still, even practice systems often remain too clean compared with production. That is why reading about real failures matters so much.
Read real-world failures
Tutorials usually teach the happy path. Postmortems teach reality.
A clean architecture never shows the retry storm that multiplied traffic, the migration that locked writes, the dead-letter queue nobody monitored, the stale cache serving wrong results, or the timeout mismatch that triggered cascading failure. Those are the details that make real systems painful and instructive.
This is where your thinking starts to mature. You stop asking only how the system should work and start asking how it fails. That is the more useful question, because distributed systems are judged by behavior under pressure.
A system that works perfectly under ideal conditions tells you very little. The real design shows up when traffic spikes, replicas lag, workers crash in the middle of a task, messages get duplicated, or downstream services slow to a crawl. Postmortems sharpen your instincts for actual system behavior rather than idealized architecture.
Here are 5 strong postmortem examples worth reading:
Postmortem of database outage of January 31 (A great example of transparency, detailed timeline, and clear lessons learned)
Slack’s Incident on 2-22-22 (A strong example of how cascading failures happen in complex systems)
Meta - More details about the October 4 outage (A useful postmortem for understanding network failures at scale)
Post mortem on the Cloudflare Control Plane and Analytics outage (A good example of connecting outage cause, recovery, and follow-up fixes)
AWS Post-Event Summaries (A solid resource for studying how large platforms document incidents consistently)
[This deserves its own full article, and there is more coming on that soon.]
After you read enough of them, one idea becomes impossible to ignore: the diagram was never the whole design.
The diagram is not the design
This is one of the biggest mindset shifts in system design.
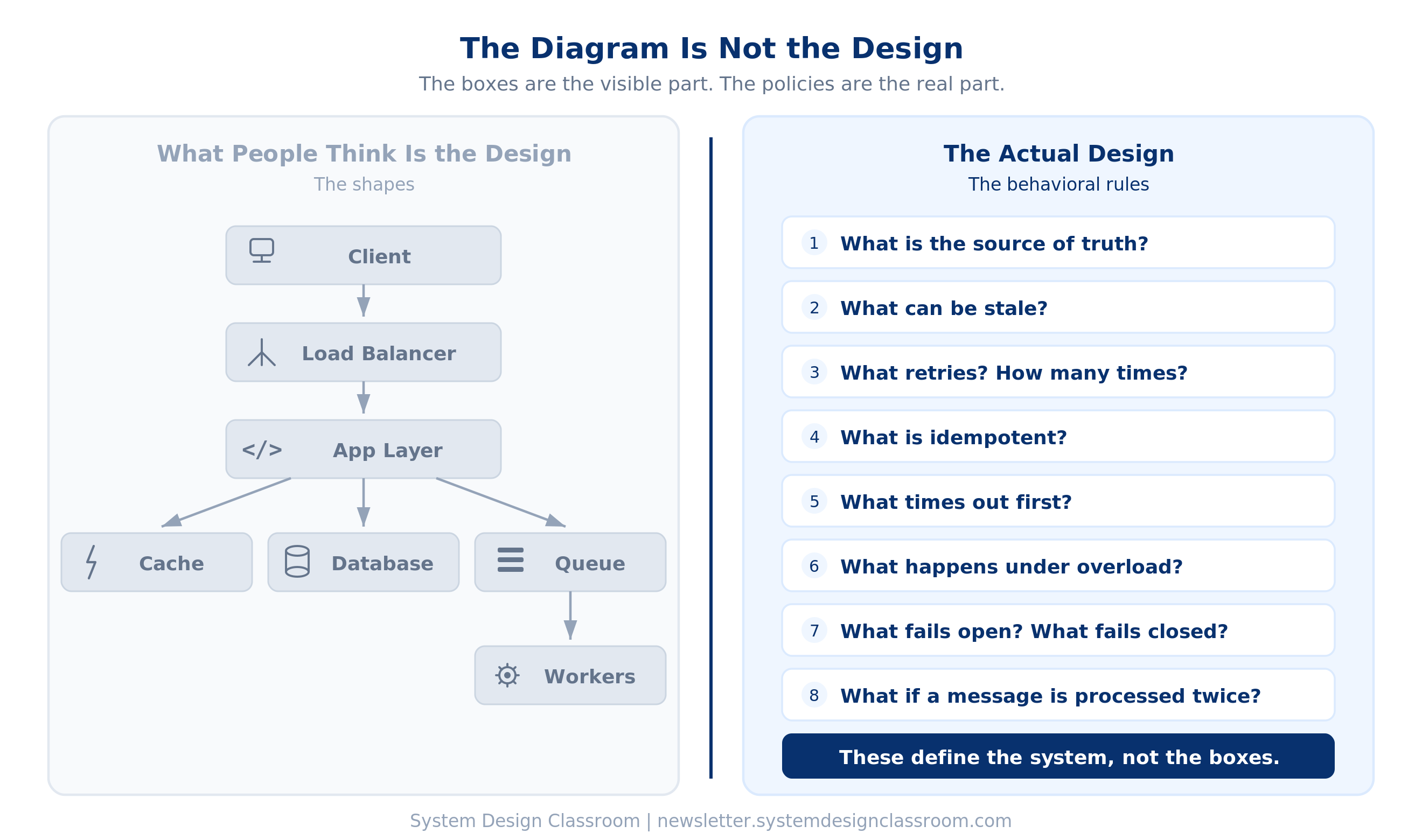
People often mistake the picture for the architecture.
Client. Load balancer. App layer. Cache. Database. Queue. Workers.
That picture is useful.
But it is not the real design. The real design lives in the rules.
What is the source of truth?
What can be stale?
What retries?
What is idempotent?
What times out first?
What happens under overload?
What fails open?
What fails closed?
What happens if a replica lags?
What happens if a message gets processed twice?
Those questions define the system far more than the visible boxes do.
You can memorize common architecture diagrams and still struggle in a real design conversation.
They know the shapes. They do not understand the behavior.
And that gap between shape and behavior is exactly what separates surface-level familiarity from actual engineering judgment.
What actually makes someone good at system design
What matters is understanding how systems behave under pressure.
That means understanding where latency comes from, why writes deserve more respect than reads, how retries can multiply outages, how caching can improve speed while hurting correctness, and why asynchronous systems need idempotency and ordering strategies.
Once those forces become clear, your design decisions change.
You stop chasing complexity because it looks impressive.
You start protecting the hot path.
You reduce blast radius.
You respect the database.
You design recovery paths instead of focusing only on success paths.
That is when system design stops being an interview performance and starts becoming engineering judgment.
Once you see it that way, the path to studying it becomes much simpler.
Final thought
Many engineers do not need more buzzwords. They need stronger fundamentals.
The best system designers are those who understand what the system is optimizing for, where pressure builds, and which trade-offs actually matter.
They know latency is real.
They know writes are expensive.
They know retries can make things worse.
They know scale is often more about controlling work than adding more machines.
They know good system design starts with constraints, not diagrams.
Until next time,
— Raul
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a paid subscriber.
Glad I found this article before learning architecture
❣️