
I have seen this mistake in production. The Dual Write Problem is not a myth.
Two solutions deal with it.

The Dual Write Problem is not just theoretical; I've seen it firsthand in production environments, and it is a genuine challenge.
This problem arises when two or more operations across different systems or databases must remain consistent, but there's no built-in transaction support to ensure they do.
A classic example is when you must write to a database and publish an event to an event broker.
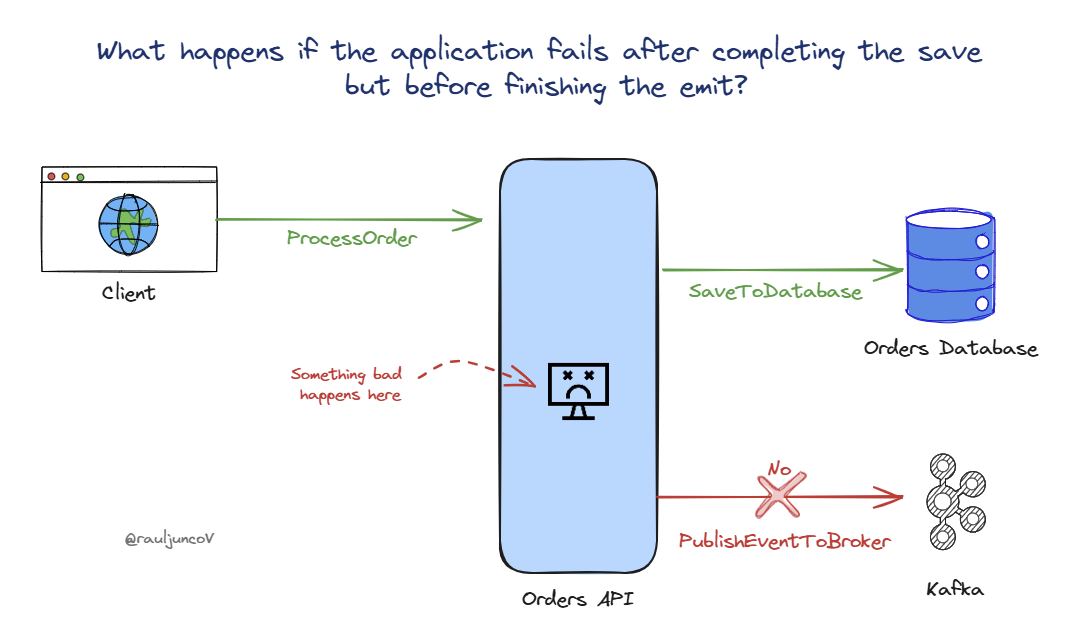
If your application crashes after committing the database transaction but before publishing the event, you've now introduced inconsistency.
Thank you to our sponsors who keep this newsletter free:
Multiplayer auto-documents your system, from the high-level logical architecture down to the individual components, APIs, dependencies, and environments. Perfect for teams looking to streamline system design and documentation management without the manual overhead.
Because we deal with separate systems, transactions are unavailable in this context. That said, if you don't implement a solution, you will have issues when one operation succeeds while another fails.
Without cross-system transactions, there are two standard solutions to handle this:
1. Using Change Data Capture (CDC)
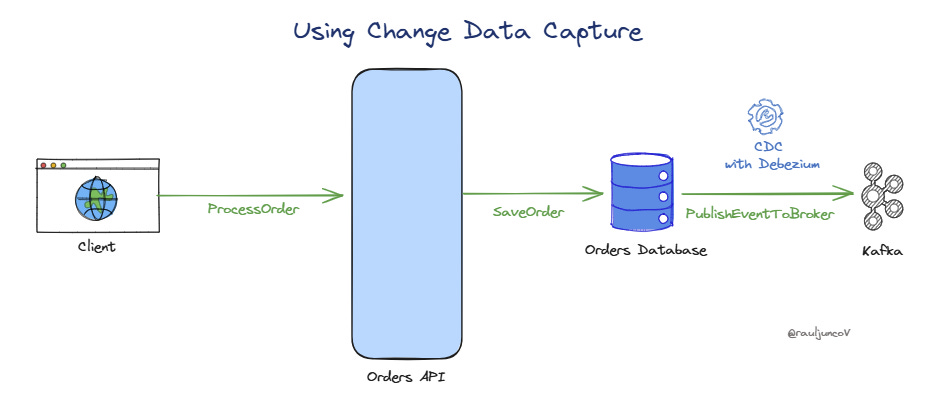
CDC works by tapping into the database's transaction logs, which contain records of every change made to the data.
By reading these logs, CDC tools can detect changes in (near) real-time and reliably capture all insert, update, or delete operations that occur.
This data is then streamed to other systems, such as an event broker, ensuring that downstream systems are informed of the changes as soon as they happen.
There are multiple ways to implement CDC, including:
Database Native CDC: Many databases have built-in CDC capabilities, like MySQL's binlog or PostgreSQL's logical replication. These options are often the easiest to integrate because they use native database features.
Third-Party CDC Tools: Tools like Debezium provide CDC as an external solution that can connect to various databases. These tools offer flexibility across different database technologies, making them a great choice for heterogeneous environments.
Benefits:
No Application-Level Responsibility: The CDC tool handles the event publishing, freeing the application from dealing with this.
Reliability: CDC is tightly coupled with the database, ensuring that committed transactions are eventually captured and emitted as events.
Scalability: CDC-based architectures are often easier to scale since the application doesn't need to manage both the core data changes and event emissions simultaneously.
Trade-off:
Operational Complexity: Setting up and managing CDC tools adds operational complexity.
Latency: While CDC typically captures changes in near real-time, there may be a slight delay between when a change is committed and when it is published to downstream systems. This latency needs consideration if your use case requires ultra-low latency.
Monitoring and Maintenance: Ensuring the CDC pipeline remains healthy requires robust monitoring and handling of edge cases, such as schema changes or database restarts.
2. The Outbox Pattern

In the Outbox Pattern, events are stored in an "outbox" table as part of the same database transaction that modifies the data. A separate asynchronous process then reads from the outbox table and publishes these events.
The Outbox Pattern ensures that event publishing does not get out of sync with data changes because both operations occur within the same transactional boundary. Here's how it works:
When a change is made to the application database, the event to be published is also stored in an outbox table in the same database transaction.
Since the data change and the outbox insertion are part of the same transaction, they either succeed or fail. This means that the event will always reflect the change to the database.
A separate worker process or background job periodically scans the outbox table for new events and publishes them to an event broker (like Kafka or RabbitMQ).
There are multiple strategies to implement the Outbox Pattern, including:
Polling Mechanism: A background process continuously polls the outbox table to check for new events and publish them.
Transactional Log Tailing: Similar to CDC, the worker can tail the transaction log and capture outbox changes, although this is less common.
Benefits:
Atomicity: The data modification and event are recorded in a single transaction, ensuring either both succeed or both fail.
Eventual Consistency: Even if the application or worker fails, the asynchronous process will eventually publish the event, preserving consistency.
Simpler Application Logic: The application logic remains simple because the outbox table handles persistence, and publishing happens asynchronously.
Trade-off:
Infrastructure Overhead: Managing an outbox table requires additional infrastructure, such as a scheduled job or worker service, to read and publish the events.
Outbox Table Growth: The outbox table can grow large over time if not managed correctly. Regular cleanups are needed to avoid performance issues.
Latency: Depending on the frequency of polling or the scheduling interval of the worker process, there might be some delay between when the data is committed and when the event is published.
Operational Complexity: Setting up and managing the outbox pattern still requires careful consideration of failure scenarios (e.g., retries, deduplication).
Final Thoughts
The Dual Write Problem underscores the challenges of maintaining consistency across different systems without transactions.
Solutions like CDC and the Outbox Pattern help minimize inconsistencies and ensure reliability.
However, these solutions introduce additional complexity that must be managed carefully.
Remember, without transactions, we can only build “eventually consistent” systems.
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Articles I enjoyed this week
What is Idempotency in Distributed Systems? by Ashish Pratap Singh
How to use Reducer in React for better State Management by Petar Ivanov
Thank you for reading System Design Classroom. If you like this post, share it with your friends!
What we are trying to achieve is a write to DB and also publish to kafka. What if we first publish to kafka and make the DB as one of the consumer to it ? Is this viable ?
Great article Raul.
We had implemented dual writes using CDC for one of the projects. It was a good outcome overall.
Also, thanks for the mention!