
Horizontal Scaling Starts with Load Balancers – But Doesn’t Stop There
Two Practical Ways to Scale Beyond Load Balancers.

When it comes to horizontal scaling, a load balancer is the go-to hero. This classic solution:
Handles traffic across multiple servers
Spots troublesome nodes
Boosts your app's reliability and performance
But horizontal scaling goes far beyond the scope of load balancing.
There are more sophisticated methods that can help handle increasing workloads, especially when vertical scaling (adding more power to a single node) has reached its limits.
Let's talk about two effective ways to scale horizontally beyond load balancing.
Thank you to our sponsors who keep this newsletter free:
Multiplayer auto-documents your system, from the high-level logical architecture down to the individual components, APIs, dependencies, and environments. Perfect for teams looking to streamline system design and documentation management without the manual overhead.
1. The Competing Consumer Pattern
The Competing Consumer Pattern is all about parallelizing work to boost throughput.
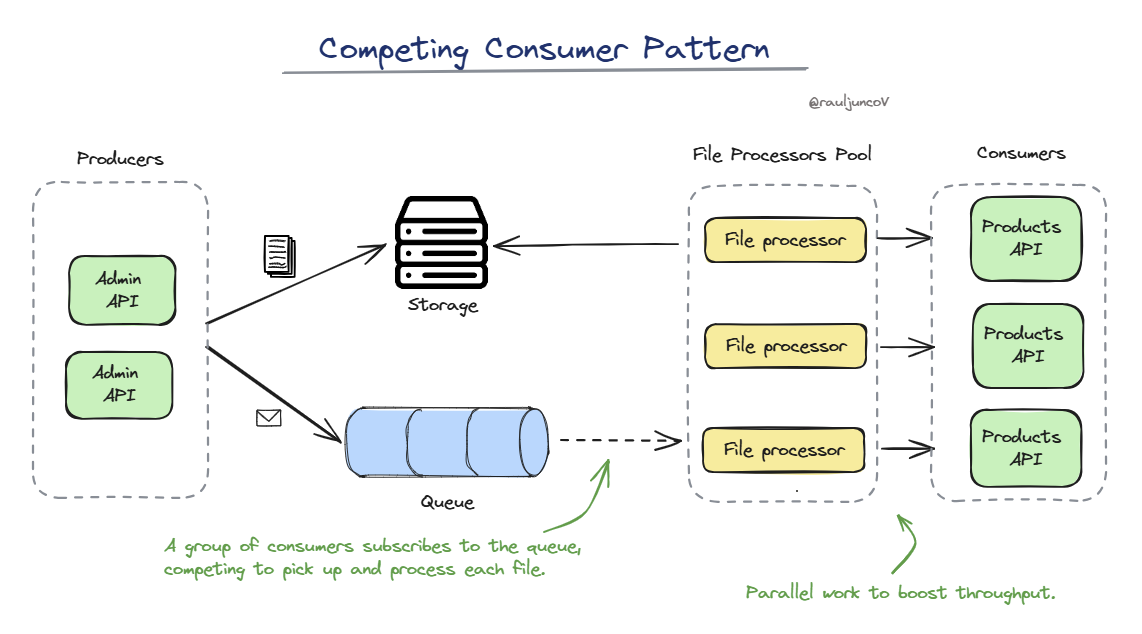
Think of this pattern as having multiple workers compete to handle tasks as they become available. It's a great way to process jobs more efficiently when you have workloads that can be broken down into smaller tasks.
Let's consider a typical scenario: a system where users can upload large files, and the files need to be processed. Here's how the competing consumer pattern can help:
Every uploaded file is placed in a message queue.
A group of consumers (i.e., worker processes) subscribes to the queue, competing to pick up and process each file.
This enables the system to scale out simply by adding more consumers.
The key to success here is the message broker (e.g., Kafka, RabbitMQ, Azure Service Bus, AWS SQS). It ensures that each job is delivered to exactly one consumer, providing a straightforward way to distribute workload.
If the system requires more throughput, the answer is easy—add more consumers.
This pattern excels in job-based systems like:
Data processing
Sending email campaigns
Even performing complex calculations.
One of its strengths is the decoupling it provides. The workload of the producer and the consumers is not dependent on each other. If you need to handle more tasks, adding more consumers will increase throughput without rewriting the rest of the system.
Of course, this doesn't come free. Solid infrastructure is required to manage a queueing system, monitor consumer health, and ensure no tasks are dropped. It adds some operational overhead.
2. Read Load Replicas
Another classic horizontal scaling strategy involves handling read-heavy workloads with Read Load Replicas.

The idea here is to reduce the pressure on a primary database by distributing read operations across replicas.
Imagine you have an e-commerce system. The database holds inventory details, customer orders, and product catalogs. Read requests are the most frequent operations for most e-commerce websites: product browsing, user reviews, inventory details, etc.
You can introduce Read replicas to ensure that these read operations do not interfere with critical write operations like orders or inventory changes.
With read replicas, the setup typically looks like this:
The primary database handles all write operations—adding, updating, or deleting data.
Read replicas get synchronized copies of the data from the primary. This allows the system to distribute read traffic across multiple replicas, significantly lightening the load on the primary database.
Read replicas are incredibly valuable in scenarios where consistency can tolerate slight delays.
For instance, if a customer places an order, it's possible that their order status might not immediately reflect on a replica (since replicas often lag behind the primary by a few milliseconds).
This lag is a minor trade-off for a huge gain in scalability and availability.
These replicas work particularly well with read-heavy systems such as social media platforms, news websites, and e-commerce stores.
They also offer a layer of resilience—if the primary database encounters a problem, read replicas can act as temporary backup options until full restoration occurs.
Wrapping up
Horizontal duplication, in general, is a straightforward concept: if you can divide the workload among several instances, you can avoid bottlenecks and scale more effectively.
The goal is always to handle more users, more requests, and more data without putting all that pressure on a single point of failure. Yet, it's important to recognize that horizontal scaling comes at a cost.
Competing Consumer Pattern requires investment in queueing infrastructure and mechanisms to monitor and restart failed jobs.
Read Replicas involve creating redundant database copies that need ongoing synchronization and careful handling of data consistency.
While horizontal scaling reduces contention and provides a way to grow without major redesigns, it does require more infrastructure, which means higher costs and increased operational complexity. This is why you need to look at these forms of scaling once vertical scaling is no longer an option.
If vertical scaling isn't viable, or you're aiming for more reliability, these forms of horizontal scaling should be on your radar.
Load balancers are often where horizontal scaling begins, but they are by no means where it ends.
The key is to understand your workload—whether it's job-heavy or read-heavy—and apply the appropriate strategy to meet demand.
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Articles I enjoyed this week
How Google Ads Was Able to Support 4.77 Billion Users With a SQL Database by Neo Kim
5 Lessons I learned the hard way from 10+ years as a software engineer by Jordan Cutler and Gourav Khanijoe
Thank you for reading System Design Classroom. If you like this post, share it with your friends!
Nicely explained Raul.
Competing consumer patterns is quite interesting.
Also, thanks for the mention!
I remember the first time I played around with Read Replicas. It boosted the overall performance of the app since we had many read requests and a few write requests.
Thank you for the mention, Raul! 🙏