
High Availability Isn't About Luck
It's About Patterns.

Downtime isn’t random. It’s the result of decisions.
And so is high availability.
If your system stays up during failure, it’s not because the universe smiled on you.
It’s because you made design choices, failover and replication, that absorbed the hit.
Availability isn’t magic. It’s math and architecture.
To design for it, you need to understand two ideas:

Failover is about keeping the service up when a node dies.
Replication is about making sure the data is still there and is fast to access.
They both solve different problems, but both are necessary and must work together. Let’s break down some key design patterns and their trade-offs for both so you can choose the right one before your pager buzzes.
They solve different problems but work together.
Thanks to our partners who keep this newsletter free for the reader.
CodeRabbit → Free AI Code Reviews in VS Code
CodeRabbit brings AI-powered code reviews directly into VS Code, Cursor, and Windsurf. Get free, real-time feedback on every commit, before the PR, helping you catch bugs, security vulnerabilities, and performance issues early.
Per-commit reviews: Identify issues faster and avoid lengthy PR reviews
Context-aware analysis: Understand code changes deeply for more accurate feedback
Fix with AI and get AI-driven suggestions to implement code changes
Multi-Layered Reviews: Benefit from code reviews both in your IDE (free) and in your PR (paid subscription)
Failover Patterns
Failover is your answer to system failure.
When a node crashes or a zone goes dark, what takes over?
Failover is your solution to the problem: keeping the service running when the primary component becomes unavailable. It’s about redundancy, having backup instances that can step in without user impact. You don’t want downtime, so you need a standby.
It’s not about preventing failure. It’s about absorbing it with minimal disruption.
There are two main patterns to implement Failover:
Active-Active: All instances are live and share the load.
Active-Passive: One instance handles traffic, others stay on standby.
The choice between these two affects everything: latency, cost, failover time, operational complexity.
You don’t want downtime. So you need a standby.
1. Active-Active Failover
In an active-active setup, all nodes are live and actively serve requests.
They share traffic through a load balancer or service mesh. If one node fails, the others continue operating, no warm-up, no handoff.

This pattern gives you high availability and high throughput, but comes at the cost of complex coordination:
You need consistent state across nodes, or idempotent operations if state sync lags.
Your load balancer must detect unhealthy nodes and remove them from rotation fast.
If nodes write to shared resources (like a DB), ensure concurrency safety and conflict handling.
✅ Pros
No downtime on node failure
Scales horizontally under load
Better resource utilization
✘ Cons
Requires robust load balancing
Harder to manage stateful workloads
Can mask underlying issues due to redundancy
📌 Use when:
You need zero-downtime failover and your service can tolerate or handle eventual consistency between nodes. Ideal for stateless APIs, edge services, and front-door layers.
Take into account this pattern maximizes uptime and capacity, but you’re also paying for that uptime 24/7.
2. Active-Passive Failover
In an active-passive setup, only one node serves requests.
One or more standby nodes remain idle until the active fails, then a failover mechanism promotes a standby to become active.

This pattern favors simplicity and consistency over speed of recovery.
But failover isn’t instant. Depending on detection and promotion logic (manual, DNS TTL, heartbeat monitoring), recovery can take seconds to minutes.
✅ Pros
Simple to wrap you head around
Easier to implement for stateful systems
Reduced risk of data conflicts
✘ Cons
Downtime during failover
Backup node is underutilized
Potential for data loss if replication lags
📌 Use when:
Failover speed is less critical than data correctness and operational simplicity. Common in primary-standby databases, DR setups, and tightly coupled monoliths.
3. Hybrid Active-Passive Failover
You don’t always have to choose between fully active or fully idle systems.
A hybrid model combines multiple active nodes with one or more passive backups.
For example, two nodes actively serve traffic, and a third is passive, ready to take over if either fails

This setup gives you the throughput and fault tolerance of active-active,
but with lower cost and simpler coordination, because not every node is participating at all times.
You’ve got:
Redundancy from the passive instance
Load distribution across the active ones
Faster failover than cold standby
Lower cost than scaling all nodes equally
✅ Pros
Load is shared across fewer active nodes → less infra cost
Passive node offers quick recovery without full duplication
Easier to understand than full active-active with N nodes
✘ Cons
Still requires sync between active and passive
Uneven load may bottleneck if one active fails
Failover logic must detect and rebalance
💰 Cost Consideration:
Lower than full active-active
Better utilization than pure passive
Scales better as demand grows
📌 Use when:
You want to reduce infra spend while maintaining high availability and good performance.
Ideal for medium-scale services where failover speed matters, but cost discipline is required.
Failover can keep your services available when components fail.
But that’s only half the story.
To keep your data available and consistent, you need replication.
Let’s shift focus from infrastructure failover to data durability and distribution, and explore the core replication strategies.
Replication Patterns
Failover helps you survive infrastructure failure.
Replication helps you survive data loss and scale reads.
Replication means keeping multiple copies of your data in sync across nodes.
If one copy is lost, another can take over.
If your read traffic spikes, replicas can help offload the pressure.
There are two primary replication strategies:
Single-leader replication: one node handles all writes
Multileader replication: multiple nodes accept writes
Let’s break them down.
1. Single-Leader Replication
In this pattern, only one node accepts writes (the leader).
One or more read replicas sync from it asynchronously.

Clients can read from the leader or any replica, but all writes must go to the leader.
✅ Pros
Simpler to conceptualize
Strong write consistency
Works well with read-heavy workloads
✘ Cons
Single point of failure (without external failover logic)
Replication lag → stale reads
Leader can become a write bottleneck under heavy load
Failover requires promotion and reconfiguration
📌 Use when:
You care about data consistency, simplicity, and read scalability.
Common in OLTP systems, dashboards, and APIs where write throughput is moderate.
2. Multileader Replication
In a multileader setup, multiple nodes can accept writes.
Each node replicates its changes to the others.
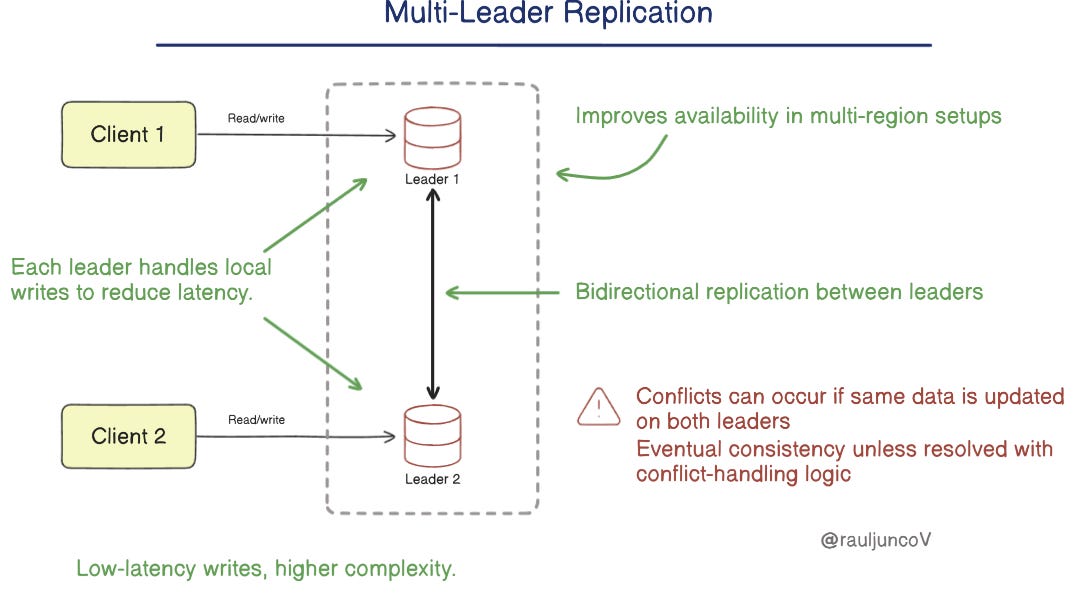
Write locally, sync globally.
Multileader setups are eventually consistent by default.
You’ll need logic to resolve conflicts, like "last write wins", version vectors, or CRDTs.
✅ Pros
High availability across regions
Local write performance (reduced latency for global users)
Avoids a single point of failure
✘ Cons
Complex conflict resolution
Increased write latency due to cross-node sync
Harder to figure out the data state
Greater operational overhead
📌 Use when:
You need multi-region write availability, or your system must remain writable even during partial outages.
Used in collaborative tools, messaging platforms, and edge-aware databases.
Bonus: Leaderless Replication (For Context)
Some systems (e.g., Cassandra, Dynamo) use leaderless replication:
Clients write to multiple nodes directly, and consistency is managed via quorum reads/writes.
Trade-offs vary, but typically:
Very high availability
Eventual consistency unless tuned carefully
Complex consistency guarantees
You likely won’t build this yourself, but you should at the very least understand it when choosing infrastructure.
Trade-offs in a table

Final Thought
Systems don't become highly available by accident.
They become resilient through intentional design.
Failover absorbs failure.
Replication protects data.
Here's what that means for you:
Don’t assume replication means zero data loss.
Don’t assume failover means zero downtime.
Don't pick a pattern based on popularity—pick based on recovery time, latency tolerance, and consistency needs.
Good architecture isn't about uptime. It's about controlled failure.
If you don't understand the trade-offs, you're not as "available" as you think.
What’s one thing your system can’t recover from today?
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a paid subscriber.
This makes sense when I think of a system that’s self aware and self healing. Very detailed 👏
Loved this detailed article, Raul!