
Focus on Building Resilient Interactions, Not Just Resilient Services
5 things a truly resilient system needs.

Many teams on distributed systems work in isolation, and of course, they focus on making individual services resilient.
But, the real challenge is how these services interact under heavy stress.
A resilient system isn't just about the durability of its parts—it's about how these parts work together when things go wrong.
Here are 5 essential practices that will help you build a truly resilient system by focusing not just on services but also on their interactions:
Thank you to our sponsors who keep this newsletter free:
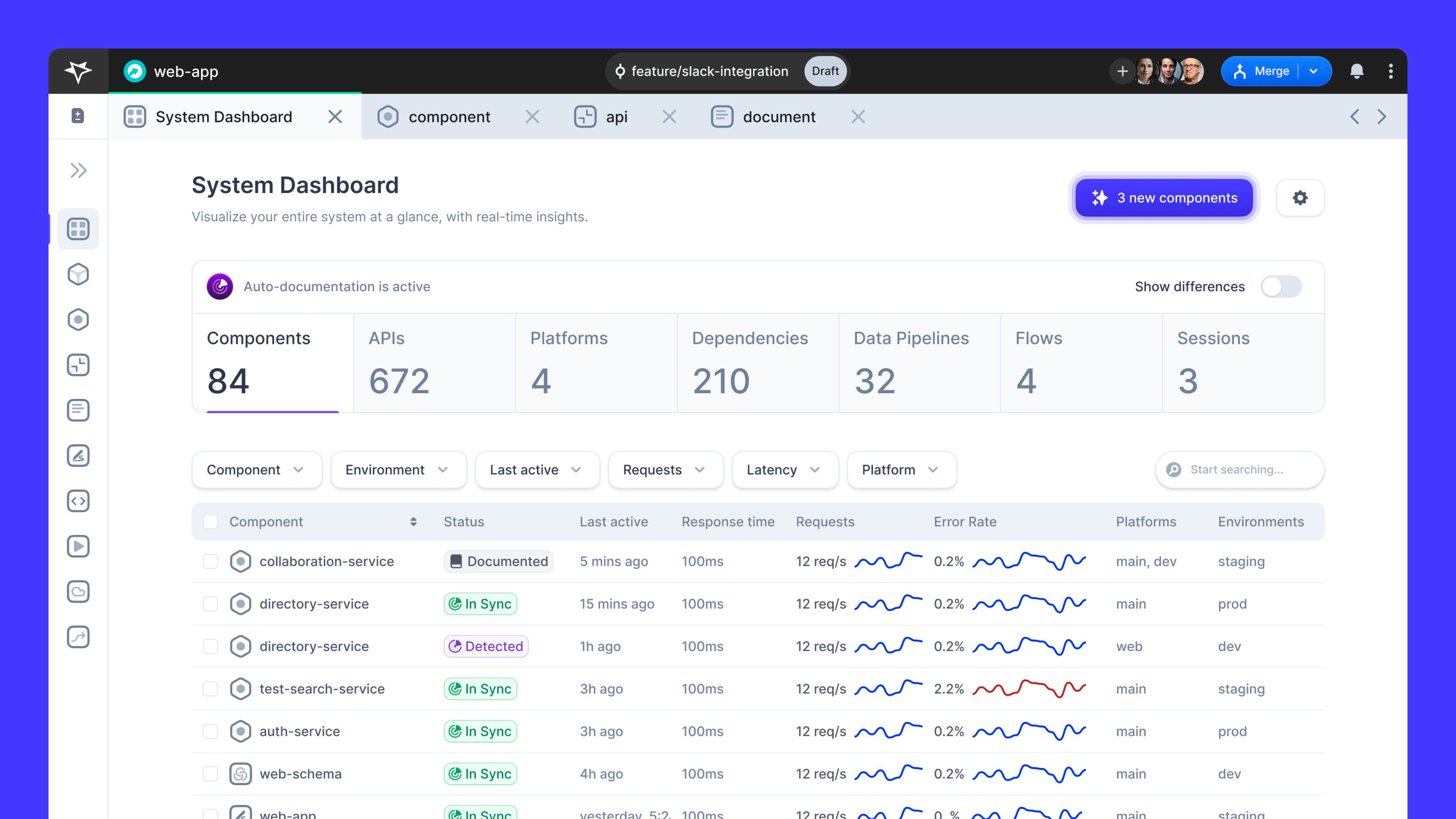
Multiplayer's System Dashboard auto-discovers, tracks, and documents your entire system architecture—from its components to APIs, dependencies, and environments. Gain real-time, comprehensive visibility into your system, all at a glance.
1. Caching is your First Line of Defense
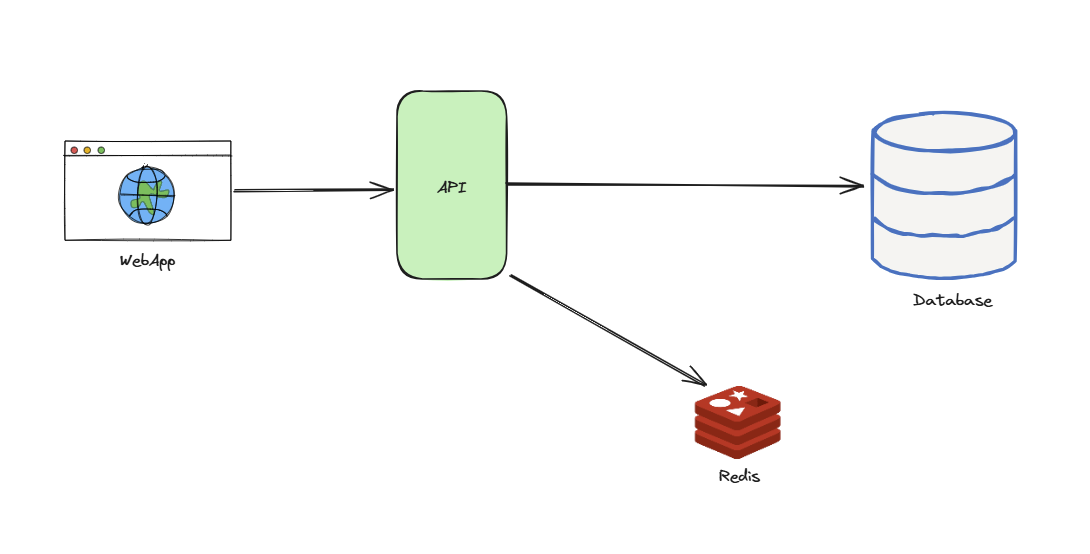
Caching frequently-read data is a powerful way to build resilience. When done effectively, caching reduces the load on the system by avoiding expensive, repeated computations and database hits. This protects against transient issues and significantly reduces costs and latency.
Even time-sensitive data, like news articles, is great for short-lived caching. Caching popular items avoids recomputing and reduces system stress.
Just be ready to deal with the complexities caching will bring:
Outdated Data: Plan how to handle stale information. Decide on expiration policies to balance freshness and performance.
Cache Stampede: When the cache expires, many clients may hit the backend simultaneously. Use request coalescing or "lazy population" to avoid overwhelming the system when refreshing the cache.
2. Prevent Cascading Failures
When one service fails, it can quickly overload others, leading to a cascading effect that spreads through the system and takes down healthy services.
These are the three most straightforward ways to deal with cascading failures:
Circuit Breakers: Stop failing services from overwhelming the system by "tripping" and stopping further requests until the service recovers.
Load Balancing: Distribute traffic evenly to prevent hotspots from overloading certain instances.
Bulkheads: Partition system resources to stop a failure from consuming all resources, isolating faults in specific components.
3. Implement Fallback Behaviors

Failure is inevitable, but how you fail gracefully is crucial. Users should never experience a crashed service directly.
When designing fallback behaviors, consider:
Fallback Data: Instead of showing an error, show cached or default data. If fetching product recommendations fails, showing some best-sellers could still engage the user.
Partial Degradation: Some parts of the system can hide gracefully. If a minor feature fails, like an analytics widget, hide it instead of disrupting core functionality.
Critical vs. Non-Critical Components: Design the system to degrade non-critical services before they affect the main user journey.
4. Retry Strategies: Don't Overdo It

Retries are key for handling temporary failures, but too many retries can overwhelm your system and turn a minor issue into a major outage.
To control retries:
Retry Budget: Give each request a retry "budget." Set a time limit or a maximum number of retries to keep things manageable.
Exponential Backoff: Instead of retrying instantly, use exponential backoff with jitter to spread out retry attempts. This prevents a "retry storm" that makes things worse.
Combine with Circuit Breakers: Stop retries if a circuit breaker is open, giving failing components time to recover.
5. Go Asynchronous Whenever Possible
Synchronous communication is brittle. If one service is down, it can block an entire request chain, causing downtime or errors.
Consider using asynchronous patterns:
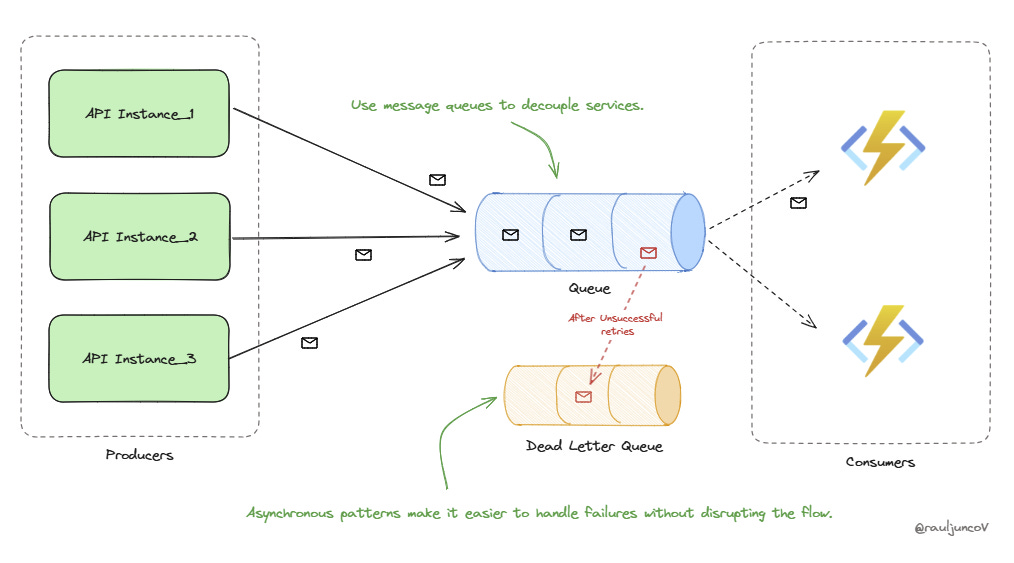
Message Queues: Use message queues to decouple services. This way, if one service is slow or down, it won't immediately impact the others.
Event-Driven Architecture: Emit events to notify other services when something important happens. Event-driven communication reduces tight coupling, which leads to more fault-tolerant interactions.
Dead Letter Queues: Sometimes messages can't be processed even after retries. Dead letter queues help isolate these messages for later analysis instead of blocking the entire flow.
My main takeaway: Focus on Interactions, Not Just Components
A resilient system doesn't just rely on tough services—it relies on how well those services work together. True resilience means your services can handle failures without triggering a domino effect.
Failures will happen. What really matters is how your system handles them. Use caching smartly, manage cascading failures, add effective fallback behaviors, control retries, and embrace asynchronous patterns.
These strategies make your system stronger, more reliable, and ready to bounce back.
Building resilience is not only about individual services but the interactions between them.
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Articles I enjoyed this week
Don't Use Sync Communication For Every Case by Saurabh Dashora
From Concept to Clarity: 2 Easy Steps to Kickstart Your Product Idea by Petar Ivanov
The Reliability Factor: Building Trust in Your Professional Journey by Riccardo Causo
Thank you for reading System Design Classroom. If you like this post, share it with your friends!
Amazing article Raul. And thanks for the mention 🙏
these are some great tips, Raul.
And a must-know for building modern web apps.