
Every repeated LLM call is money on fire
Redis 8 just changed the game with semantic caching that understands meaning, not just keys.

Your cache may be fast.
But it doesn’t understand your data.

That’s been the hidden flaw in conventional caching, especially in AI and search-heavy systems.
You can store the output. You can key it smartly. But unless the input exactly matches, you're back to a cache miss.
The result?
LLMs answering the same questions phrased 100 ways.
Search engines recomputing nearly identical vector queries.
Agents re-processing states they’ve already seen.
Caching by key doesn’t work when your users speak in meaning.
Redis 8 offers a serious upgrade: semantic caching, made practical with new native features like Vector Sets, LangCache, and to also help, Redis Flex.

Let’s break down the shift and what it unlocks.
Something I’m excited to share with you:
I’ve been working with a couple of friends on a platform designed to make us better engineers—one challenge at a time.
It’s called Join Enginuity.
Every day, you get a system design problem that forces you to think, research, and sharpen your instincts.
No fluff. No endless reading. Just practical challenges that make you better.
The Caching Problem in LLM Systems
Caching works great when your input is stable:
GET /product?id=123
You cache product:123 and call it a day.
Now compare that to an LLM workload:
User 1: What is Redis LangCache?
User 2: Can you explain how LangCache works in Redis?
User 3: Tell me about Redis' new caching for LLMs.
Semantically identical.
But unless you normalize or fingerprint aggressively, the cache sees them as totally different.
That means every slight rephrasing triggers a full LLM call. You pay again. You wait again.
Same output, burned compute.
What Redis 8 Introduces (And Why It Matters)
1. Vector Sets – Native Vector Similarity in Redis
Previously, you’d need a bolt-on vector DB like Pinecone or FAISS. Redis had no efficient built-in support.
Now it does.
Imagine you have a collection of colored balls. Each ball has:
A label (like "red ball" or "blue ball").
A set of numbers describing it (its "vector", which could be like [1.0, 2.0, 3.0]).
Extra info, like "size=large" or "owner=John".
What do Redis vector sets do?
They store all these balls, each with their numbers and labels.
You can ask Redis: "Which balls are most similar to this one?" — It compares the numbers (vectors) to find matches.
You can also limit your search to certain balls (like only balls with "owner=John").
Why use Redis for this?
It’s super fast at searching for similar items, which is great for things like recommendations, finding related products, or grouping similar texts/images.
Example in plain steps:
Add balls with their numbers and info.
Ask for the most similar balls to a given one.
Filter results by extra info ("only large balls").
Remove balls or check how many you have.
It’s just a clever way to quickly store and search for things that are "close" to each other, based on their numbers. Perfect for finding related items, instantly!
The following commands are available for vector sets:

2. LangCache – Caching for Meaning, Not Just Keys
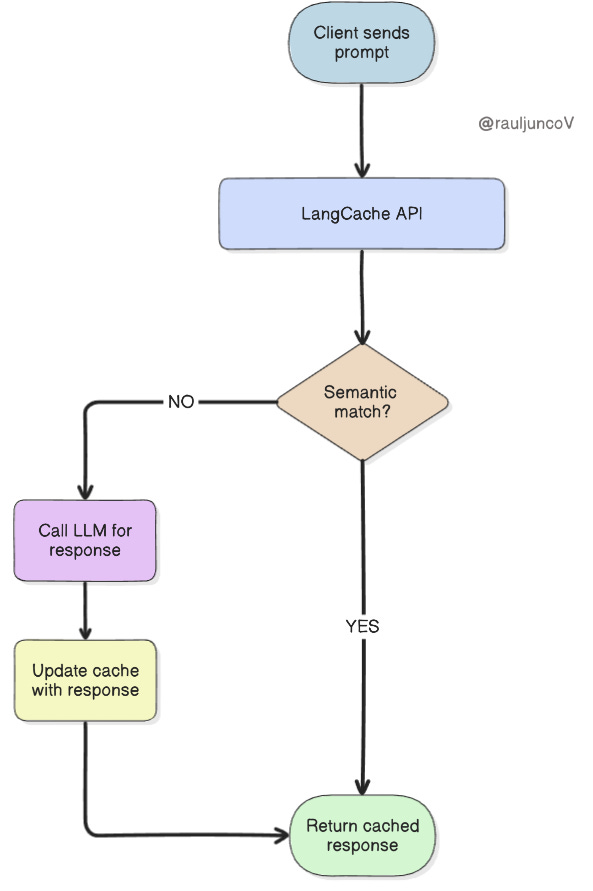
LangCache is a fully managed semantic cache built on Redis 8.
It flips the caching model:
Instead of: cache[exact_string] = result
Now: cache[embedding] ≈ result
LangCache uses your existing embedding model (OpenAI, Cohere, etc.) to generate a vector from the prompt. Then it searches the cache for similar past entries. If it finds one, it skips the LLM and returns the cached output.
You just saved money and time, without losing correctness.
LangCache is available via REST API and is fully managed on Redis Cloud.
The request flow looks like this:
This is ideal for:
Chatbots and support agents
RAG pipelines
Multi-step planning agents
Any system with input redundancy
No key shaping. No hashing. Just raw meaning.
Use this formula to estimate savings:
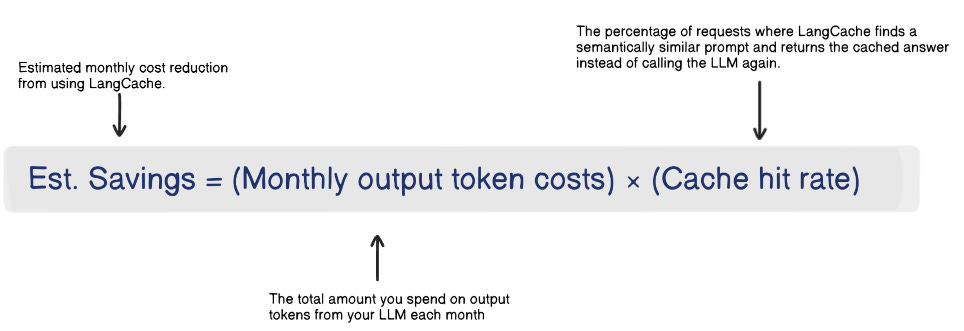
Example: If your monthly LLM spend is $200, 60% of that is output tokens ($120), and you get a 50% hit rate, that’s $60 saved per month
3. Redis Flex – Cache More for Less
Caching gets expensive at scale, especially if everything lives in RAM.
Redis Flex lets you offload less-used data to SSD, increasing cache capacity up to 5x without a 5x cost bump.
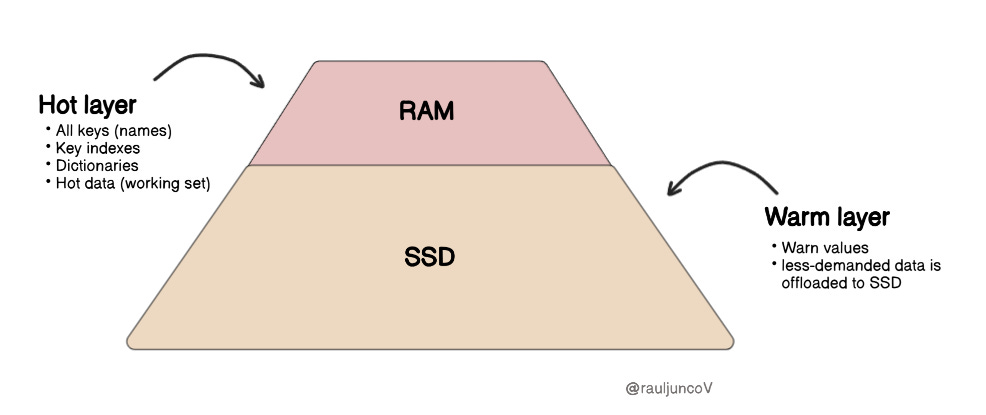
RAM storage holds:
All keys (names)
Key indexes
Dictionaries
Hot data (working set)
RAM can handle hot data, while your SSD handles warm data. You control eviction policies, thresholds, and performance trade-offs.
Frequently accessed data stays fast in RAM; less-demanded data is offloaded to SSD automatically. Applications use the same Redis API and don’t need to change to take advantage.
Redis Flex is ideal when your:
working set is significantly smaller than your dataset (high RAM hit rate)
average key size is smaller than average value size (all key names are stored in RAM)
most recent data is the most frequently used (high RAM hit rate)
Redis Flex is not recommended for:
Long key names (all key names are stored in RAM)
Broad access patterns (any value could be pulled into RAM)
Large working sets (working set is stored in RAM)
Frequently moved data (moving to and from RAM too often can impact performance)
Redis Flex is not intended to be used for persistent storage.
With Flex + LangCache, you can serve semantic cache hits at scale affordably.
Why This Matters (Beyond Buzzwords)
Let’s be blunt: most current AI architectures are duct-taped.
RAG pipelines re-embed the same documents.
Agents reprocess state with no memory.
Teams pay LLM costs repeatedly for cached knowledge.
The tools weren't ready until now.
Redis 8 changes that:
You can store and search semantic data directly.
You can cache LLM responses intelligently.
You can scale caching affordably with hybrid RAM/SSD.
It’s not just faster. It’s a different model.
What Could Go Wrong?
Every system has trade-offs. Here are a few worth flagging:

LangCache offers controls for most of this: TTLs, thresholds, scoped caches, etc.
Still, it’s not fire-and-forget. You’ll need to test thresholds and observe cache hit rates.
Takeaways
Conventional caches will break under semantic load. Redis 8 fixes that with new primitives.
Vector Sets allow Redis to natively support vector similarity search.
LangCache turns prompt caching from string-matching into meaning-matching.
Redis Flex makes it scalable without blowing up costs.
Semantic cache isn’t just nice-to-have—it’s the only way to avoid repeated LLM waste.
Final Thought
Caching isn’t dead.
But the old rules don’t hold when your inputs are probabilistic, fuzzy, or phrased 10 different ways.
The next generation of infrastructure needs to understand meaning, not just match keys.
Redis 8 is the first real step toward that future.
If you’re building anything with LLMs, embeddings, or real-time retrieval, this upgrade isn’t optional.
It's overdue.
Every LLM call you make that could’ve been a cache hit is tech debt you’re paying in real time.
Until next time,
— Raul
References:
https://redis.io/docs/latest/develop/whats-new/8-0/
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a paid subscriber.
This would be a great improvement for every Agentic / LLM application. I'll have to give Redis 8 a try.
Thanks for this breakdown, Raul!
Awesome post! I didn't know about this new Redis thing. I'll check it out to learn more.