
Event-Driven Systems Are Easy to Build but Hard to Keep Correct
4 ways event-driven systems fail without looking broken

The biggest lie event-driven systems tell is that working infrastructure means a working system.
It does not.
The broker is healthy.
Consumers are online.
Messages are flowing.
Dashboards are green.
And yet, somehow, the business is still getting the wrong result.
A customer gets charged twice. A refund lands before the payment. An order exists in the database, but no downstream service knows about it. A producer ships a harmless-looking schema change and breaks consumers without triggering any visible outage.
That is the real difficulty in event-driven systems. They rarely fail as loud availability incidents. They fail as quiet correctness bugs that spread across retries, ordering gaps, dual writes, and schema drift. That is where this article starts.
Your team’s second brain. Now in Slack.

Your engineers talk in Slack. They code in the terminal. Somewhere between those two things, context goes to die.
A bug was debated in #incidents at 2 AM.
An architectural call was made in a DM.
Every handoff leaks context and every leak costs you. That’s the context tax - and your team pays it every day.
CodeRabbit Agent for Slack is built for agentic SDLC workflows. One agent for your entire Software Development Lifecycle, living in the channel where the work already happens. It’s built on four things:
Context - your org’s operating picture, pulled from across code, tickets, docs, monitoring and cloud.
Knowledge Base - a living memory of your team. Every run leaves a trace, so yesterday’s decisions don’t become tomorrow’s debates.
Multi-Player - works in shared threads alongside your team. Steerable, resumable and aligned as work evolves.
Governance - scoped access, cost attribution. Every run explainable and attributed.
Your team keeps shipping. Agent keeps the context.
From the team that pioneered AI code reviews. 2M code reviews every week. 6M repos. 15K customers. And now, one agent for your entire SDLC, right in Slack.
1) Duplication breaks correctness long before it breaks infrastructure
Most teams know duplicate events can happen. Fewer teams build like they actually believe it.
In distributed systems, duplicate delivery is normal. A consumer can process an event, crash before acknowledging it, and receive the same event again after restart. A producer can time out while publishing, retry, and accidentally send a second copy. A broker can redeliver during failover or rebalance. None of this is exotic. This is standard behavior once networks, retries, and failures enter the system.
The problem starts when the business operation is not safe to repeat.
If PaymentCaptured gets processed twice, you can charge the customer twice. If InventoryReserved gets processed twice, you can overshoot inventory and block legitimate orders. If OrderConfirmed gets processed twice, you can create duplicate shipments, emails, or loyalty updates. The infrastructure still looks healthy, but the system has already started to decay.
This is why idempotency is not a nice-to-have in event-driven systems. It is part of the contract.
An idempotent consumer can receive the same event more than once and still leave the system in the same final state. In practice, that usually means the event carries a stable unique ID, and the consumer checks whether it already processed that ID before applying side effects. If it has, it skips the work. If it has not, it processes the event and records that fact in a durable way.
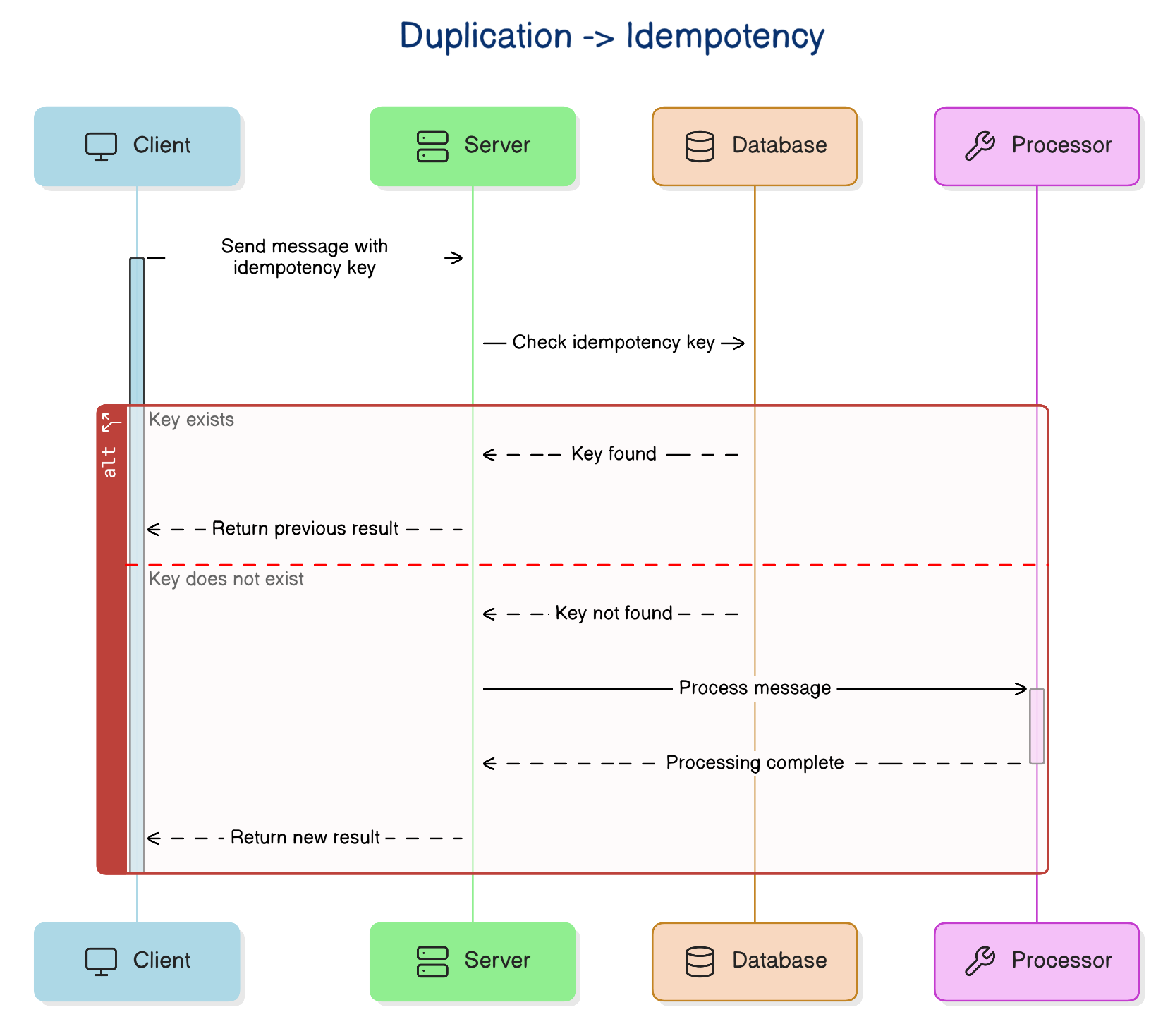
The durable part matters. If you process first and record later, a crash between those two steps puts you right back in trouble. The safest versions of this pattern make the business update and the deduplication record happen atomically. A unique constraint on event_id in a database table can go a long way here because it lets the storage layer enforce what the code can easily get wrong.
That protection stops at the database boundary. If the consumer also sends an email, calls a payment gateway, or triggers a webhook, you need an idempotency key that the external service understands, otherwise retries can still duplicate the side effect.
You can also reduce risk by shaping operations in a more idempotent way. Setting a resource to a target state is often safer than applying an incremental mutation. status = SHIPPED behaves better under replay than shipped_count += 1. Replacing a projection row behaves better than appending blindly. These are small choices, but small choices compound in distributed systems.
There is a trade-off. You pay with extra storage, retention decisions, and more complexity in the consumer path. But that cost is predictable. The cost of duplicate side effects is not.
Once a team accepts that events can show up more than once, the next uncomfortable truth appears quickly: even if every event arrives only once, it may not arrive when you expect it to.
2) Ordering assumptions collapse as soon as the system gets real traffic
A lot of event-driven workflows work perfectly in local testing for one simple reason: local testing is too polite.
Messages arrive one at a time.
The consumer is fast.
Nothing retries.
Nothing gets delayed.
Nothing competes for the same partition, queue, or resource.
But production is not polite.
Under real traffic, events can arrive out of order for many reasons:
One message gets delayed in the network while a later one moves through faster.
A retry brings back an older event after a newer one already succeeded.
Parallel consumers finish work in a different sequence than the messages were produced.
The result is the same: the workflow still runs, but the sequence stops matching reality.
That is how you end up with business nonsense. A refund gets processed before the original payment. An account gets closed before the final balance adjustment arrives. A shipment marked as delivered reaches a read model before the shipped event shows up. The system is not down. It is just wrong.
This is where many engineers reach for a broker feature and stop thinking. “Kafka preserves order” gets repeated a lot, but it is incomplete. Kafka and similar systems can often preserve order within a partition. That is useful, but it is not the same as global ordering across the whole system.
That difference matters.
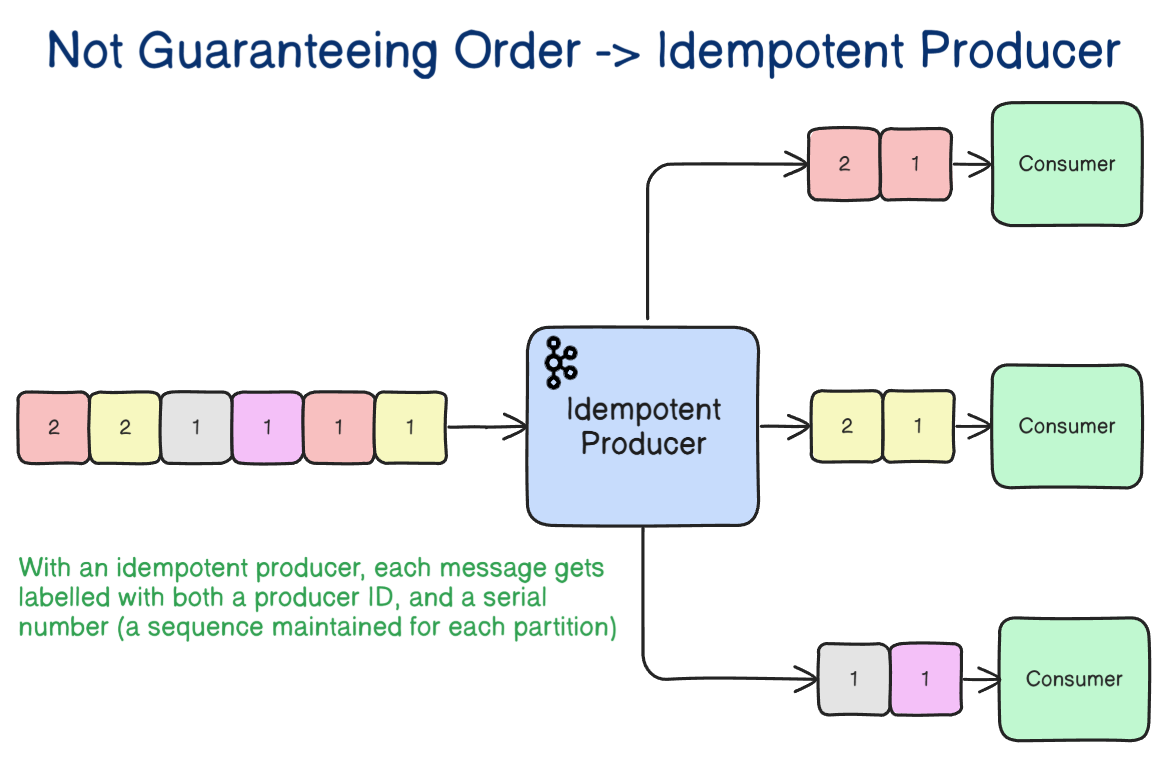
In most systems, order matters only within a business entity: one order, one account, one cart, one user. This gives you the right mental model. Partition by the entity whose timeline must remain consistent. If all events for order-123 land in the same partition, you get a realistic path to local ordering where it matters. That is usually enough.
Even then, broker-level ordering does not remove processing gotchas. During consumer-group rebalancing, one consumer can lose a partition while another takes over, so sloppy offset handling or side effects in flight can still create behavior that looks out of order from the business point of view.
Also, a strong design carries enough information to detect stale or missing events. Sequence numbers help. Aggregate versions help. State-machine validation helps. If the consumer receives event 12 before event 11, it should know that something is off. If it receives an old transition that no longer makes sense, it should reject it instead of applying it.
This is one of the biggest system design lessons in event-driven architecture: strict ordering is expensive, fragile, and easy to lose as scale grows. Good systems reduce how much they depend on it. They use ordering where necessary, but they do not build the whole workflow on the hope that events will always arrive in the exact right sequence.
And once you stop trusting sequence, another design flaw becomes impossible to ignore: what happens when one action needs to update the database and publish an event at the same time.
3) The dual write problem creates inconsistencies that look invisible at first
This is one of the easiest mistakes to write and one of the hardest to clean up later.
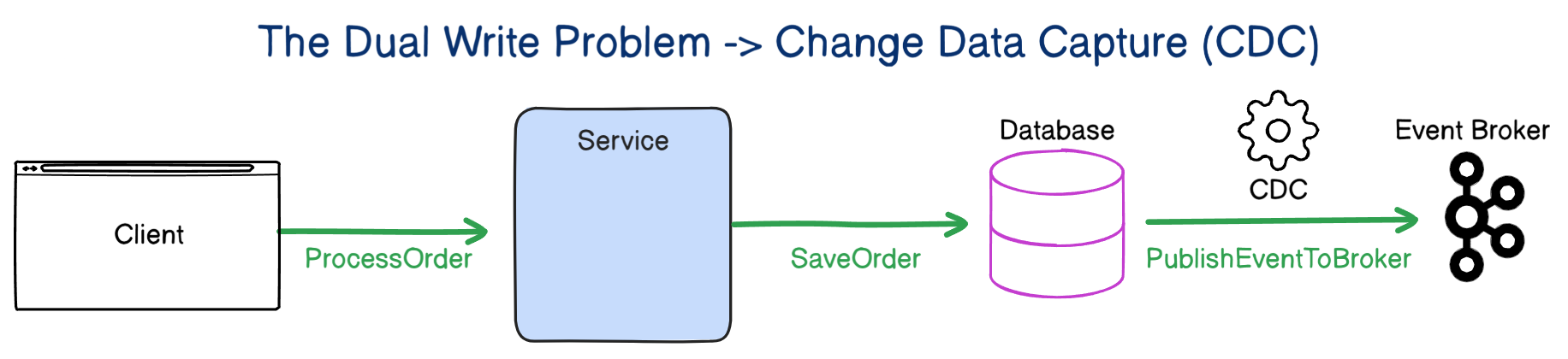
The service saves business data to the database. Then it publishes an event to the broker.
Two lines of code.
Two successful API calls in the happy path.
One serious correctness problem.
These two writes do not share the same transaction boundary. The database can succeed while the publish fails. The publish can succeed while the database rolls back. The moment that happens, the system starts telling two different stories.
Imagine an order service that writes a new order row and then publishes OrderPlaced. If the database commit succeeds but the broker publish fails, the order exists, but inventory, billing, shipping, and analytics never hear about it. The source of truth says the order is real. The rest of the system behaves as if it never happened.
Flip the failure and the problem is just as bad. If the event reaches the broker but the database transaction fails, downstream services react to an order that never truly existed. Now you have phantom work spreading into places that trust events as facts.
That is why the dual write problem is so dangerous. It does not usually create a loud outage. It creates silent divergence.
Kafka’s exactly-once semantics help with atomicity and deduplication inside Kafka workflows, but they do not make your database write and your broker publish one atomic step. That is why they do not remove the dual-write problem by themselves.
The most practical default fix is the transactional outbox pattern.
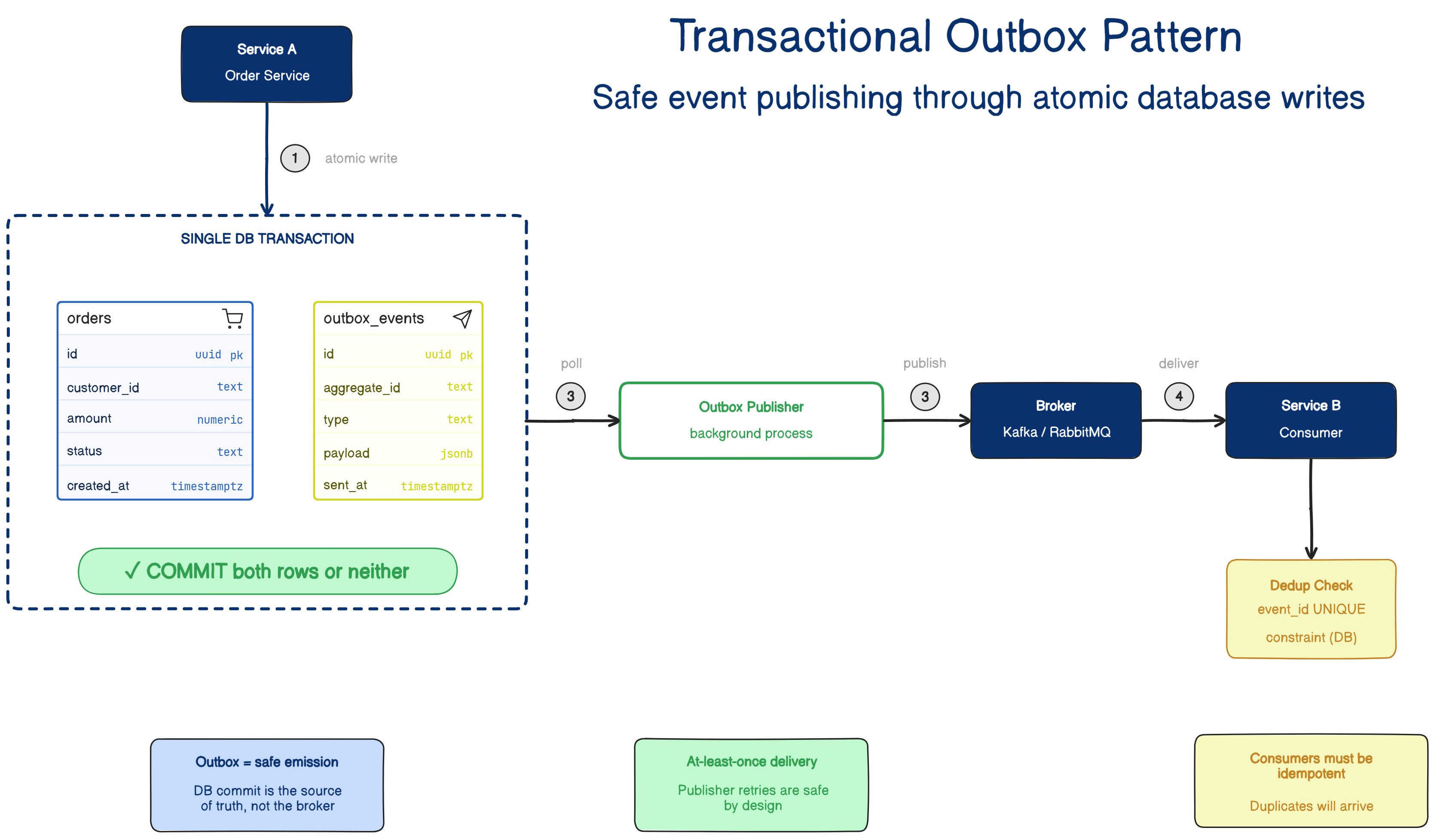
Instead of saving business data and publishing directly in the same request flow, the service writes two records in one local database transaction: the business change and an outbox row that represents the event to be published. If the transaction commits, both persist together. If it fails, neither does. A separate publisher process reads from the outbox table and sends events to the broker later.
This is a much stronger model because it moves the atomic boundary to the database, which you already control. You stop pretending the broker and database can behave like one atomic write when they live in different systems. You make the database authoritative, then publish from durable intent.
That does not remove all complexity. The outbox publisher can still retry. Events can still be published more than once. Consumers still need idempotency. But the architecture now fails in a way that is easier to reason about and recover from.
The publisher also needs ordering discipline. If parallel workers or retry logic publish outbox rows out of sequence, you can reintroduce ordering bugs in the very layer that was supposed to make delivery safer.
Log-based CDC solves a similar problem from a different angle. Instead of explicitly writing to an outbox table, log-based CDC captures committed database changes from the transaction log and turns them into events. That can work well, especially when a team wants the database log to drive integration. But CDC adds another operational layer: connectors, lag, replay concerns, schema mapping, and debugging through infrastructure that sits outside the application code. Outbox usually gives most teams a simpler starting point.
Once you see how dangerous contract mismatches between systems can be, the next problem becomes predictable. If writing data and publishing events can split your truth, then changing the shape of those events can split your meaning.
4) Schema changes break systems quietly because contracts fail quietly
A producer changes an event schema and the deployment goes through cleanly.
That is often the moment the trouble starts.
Maybe a field gets renamed.
Maybe a required field gets removed.
Maybe a number becomes a string.
Maybe a nested object gets restructured.
Maybe the meaning of a field changes even though the name stays the same.
From the producer’s point of view, the change can look harmless. Their service still compiles. Their tests still pass. Their deployment looks green. But downstream consumers may still depend on the previous shape or semantics. Some will fail loudly. Others will keep running and do the wrong thing more quietly, which is usually worse.
This happens because teams treat events like implementation details. They are not implementation details once another service depends on them. At that point, the event is a contract.
And contracts need change discipline.
Backward-compatible changes should be the default. Adding an optional field is usually safe. Removing a required field is usually not. Renaming a field looks small in the producer codebase, but it behaves like a breaking API change to every consumer. Changing semantics without changing shape is even more dangerous because it can preserve technical compatibility while breaking business meaning.
That is why schema evolution needs explicit rules, not assumptions.
Versioning helps because it makes change visible. Schema-aware formats like Avro or Protobuf help because they force teams to think about compatibility instead of drifting casually. Compatibility checks in CI help because they catch bad changes before they spread. But even with all of that, there will still be moments when a producer needs to move to a new schema before every consumer is ready.
In production, teams usually pair those formats with a schema registry so compatibility rules get enforced before a breaking change reaches consumers.
That is where adapters earn their place.
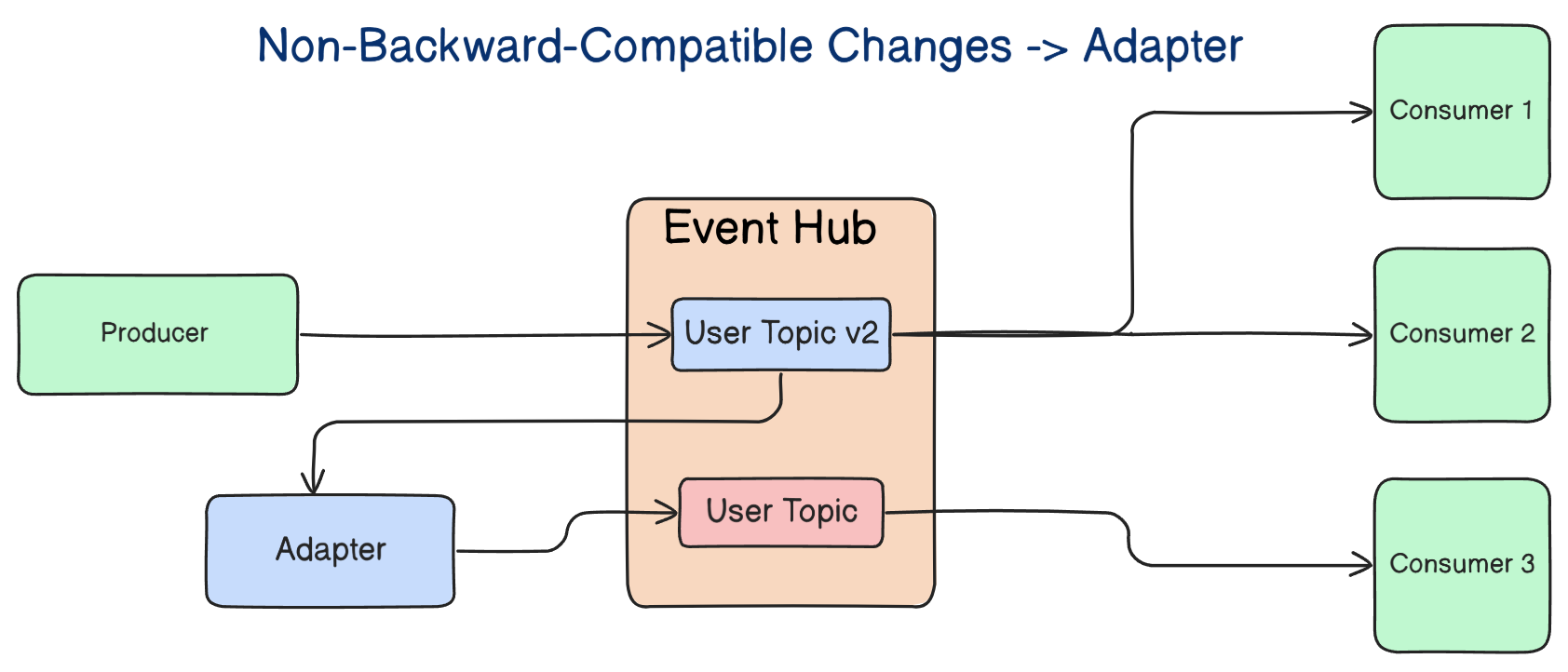
An adapter can translate a new event shape into an older one so legacy consumers keep working while the system migrates gradually. It is not glamorous, but it is practical. It reduces synchronized deployments, avoids forcing five teams to coordinate a single rollout window, and gives the system room to evolve without turning every schema change into an organizational incident.
The deeper point is that schema evolution is not just a serialization concern. It is a coordination concern. It tests whether teams understand that shared events create shared responsibility.
At this point, the pattern behind all four failures should feel familiar.
The real problem is not events. It is designing only for the happy path
Duplication, reordering, dual writes, and schema drift look like separate issues, but they usually come from the same mistake.
Teams design the happy path in detail and treat failure behavior as cleanup work.
They spend time on what events exist, who publishes them, who subscribes to them, and how the workflow should behave when everything goes right. They spend less time on redelivery, replay, stale data, partial failure, delayed delivery, and contract evolution. That imbalance is exactly why so many event-driven systems look elegant in diagrams and turn messy in production.
This is why I do not judge event-driven systems by how clean the event flow looks on a whiteboard. I judge them by what happens when the same message arrives twice, when event 8 shows up before event 7, when the broker is healthy but the publish still fails, and when one team changes an event contract without fully understanding who depends on it.
That is where the architecture stops being theoretical and starts becoming real.
And once you see that, the right takeaway is not “avoid events.” The right takeaway is to design them with the same seriousness you would apply to a database schema or a public API.
What to internalize from this
If you build event-driven systems, assume four things from day one.
Duplicates will happen.
Order will break somewhere.
Two-step writes will eventually diverge.
Schemas will change before everyone is ready.
If your design does not account for those realities, it is not finished.
That does not make event-driven architecture bad. It makes it honest. Async systems can decouple teams, absorb load well, and support useful integration patterns. But they do not remove complexity. They move it into retries, consistency boundaries, replay, and contracts. You still pay the bill. You just pay it in different places.
That is why event-driven systems are easy to build and hard to keep correct.
Takeaways
Event-driven systems often fail as correctness problems, not availability problems.
Duplicate delivery is normal, so consumers need idempotency from the start.
Ordering usually matters per entity, not across the whole system.
Dual writes create silent inconsistency, which is why the outbox pattern is such a strong default.
Schema changes are contract changes, even when the producer team treats them like local refactors.
The hard part of event-driven architecture is not publishing events. It is keeping business behavior correct when the system stops behaving neatly.
Until next time,
— Raul
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a paid subscriber.