
Don’t share schemas. Share APIs.
There are many anti-patterns in microservices. Content Coupling is the worst.

A Microservices architecture offers many benefits: independent scalability, clear separation of concerns, and modular team ownership.
But, it also has pitfalls that can lead to serious headaches—Content Coupling is the worst.
Content Coupling happens when one service directly accesses or manipulates another service's database. It might seem convenient or "more efficient," but it poses serious risks that compromise the integrity and maintainability of your entire system.
Let's look at Content Coupling, why it's a problem, and how to avoid it.
Thank you to our sponsors who keep this newsletter free:
Multiplayer auto-documents your system, from the high-level logical architecture down to the individual components, APIs, dependencies, and environments. Perfect for teams looking to streamline system design and documentation management without the manual overhead.
Understanding Content Coupling
Imagine you have the following services in an e-commerce system:
Order Processor: Manages order creation and updates.
Orders API: Handles order-related operations.
Shipping API: Handles all aspects of order shipment.
Orders Database: The data store for order details.
In a content coupling scenario, the Shipping API accesses the Orders Database directly to change the status of an order, like marking it as "Shipped." This might seem straightforward and optimal. But it's anything but.

Why Content Coupling Is Problematic
Direct database access leads to issues that undermine the reliability and scalability of a microservices architecture. Let's break down the core problems:
1. Unclear Ownership and Responsibility
When multiple services access a database directly, ownership becomes unclear.
Who manages and updates the order data? In this scenario, both the Orders API and Shipping API can make changes, causing confusion and conflicts.
Microservices succeed in having well-defined boundaries and responsibilities—content coupling destroys this clarity.
2. Duplication of Business Logic
For the Shipping API to update the order status directly, it must replicate some of the logic from the Orders API.
This could involve rules like validating allowed status transitions or ensuring data integrity. Duplication means any change to business rules needs to happen in multiple places, increasing the risk of inconsistency and errors.
3. Synchronized Deployments and High Coordination Costs
When services share direct access to the database, even simple changes to the Orders Database schema can impact multiple services.
Teams need careful coordination to prevent failures, and this beats the purpose of the agility that microservices are meant to provide.
Instead of moving fast and evolving services independently, teams must synchronize updates, delaying progress.
4. Loss of Encapsulation
One core principle of microservices is encapsulation—internal details should stay internal while only the contract (usually an API) is shared.
The database schema becomes a public contract by allowing the Shipping API to interact with the Orders Database directly.
This limits the ability to refactor or optimize internal structures without breaking other services.
5. Increased Risk of Data Corruption
When multiple services update the same data independently, the risk of corruption grows.
Without centralized control over the logic governing state changes, the integrity of the order data can easily be compromised by out-of-sequence or improper updates, leading to cascading failures.
The Correct Approach: Service-to-Service Communication

Instead of letting the Shipping API directly manipulate the Orders Database, a better design is to have Shipping communicate with the Orders API. You can do this:
Synchronously: using HTTP/REST or gRPC requests.
Or Asynchronously: using a Message Broker.
Example Flow for Updating Order Status
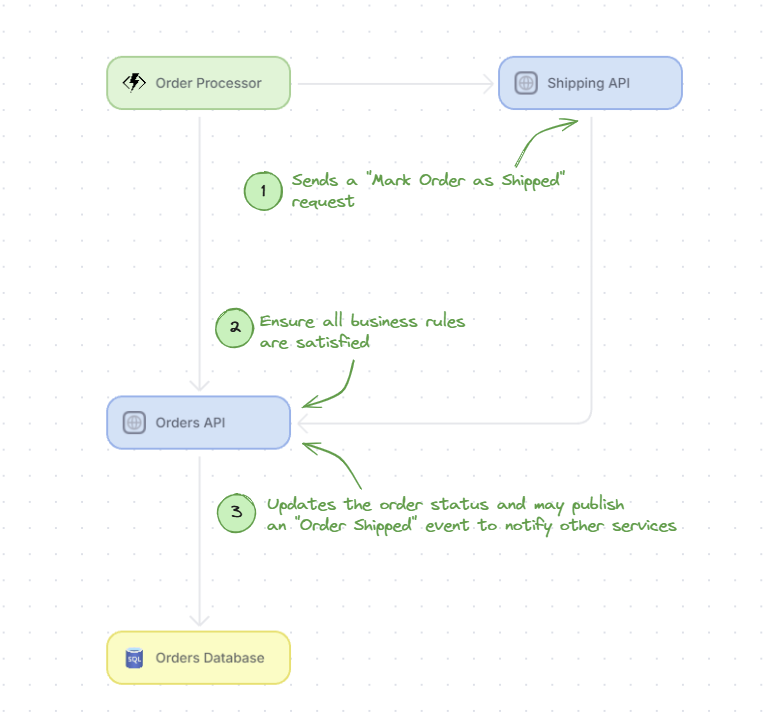
The Shipping API sends a "Mark Order as Shipped" request to the Orders API.
The Orders API validates the request, ensuring all business rules are satisfied.
The Orders API updates the order status and may publish an "Order Shipped" event to notify other services.
Benefits of This Approach
Centralized Logic and Ownership: The Orders API manages the business rules, ensuring consistency and avoiding duplication.
Independent Evolution: Services don't need to worry about database changes affecting others, allowing them to evolve independently.
Fault Isolation and Scalability: Services only interact via APIs or messaging, improving fault isolation, scalability, and observability.
Summary: Keep Databases Internal
The crux of microservices architecture lies in separating concerns and clear contracts.
A database is an internal detail of a service, not a public API. When you allow other services to access your database, you break encapsulation and make independent evolution nearly impossible.
Avoiding content coupling isn't just a best practice—it's necessary for creating maintainable, scalable, and resilient microservices.
A clear separation between what a service exposes and what it keeps private allows teams to develop independently, evolve freely, and sleep better at night, knowing that changes in one part of the system won't inadvertently break another.
Database ≠ Public API; Don’t share schemas. Share APIs!
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Articles I enjoyed this week
Thank you for reading System Design Classroom. If you like this post, share it with your friends!
Clear APIs between services are a must. It might look easier to access other DBs directly but with the project's growth maintaining that will become a mess.
Solid article, Raul!
Well explained, Raul! Thanks for sharing!