
Distributed Transactions Are the Root of All Complexity
SAGAs provides a structured way to deal with them.

Most software complexity isn’t in the code.
It instead lies hidden in the coordination.
And nothing makes coordination harder than distributed transactions.
What Are Distributed Transactions?
A distributed transaction is a single logical operation that spans multiple services or databases. You typically see this in microservices, where multiple components need to work together to fulfill a single user action.
For example, placing an order might involve:
Charging a payment method (Payments Service)
Reserving stock (Inventory Service)
Scheduling delivery (Shipping Service)
Ideally, these should either all succeed or all roll back. But in distributed systems, that's far easier said than done. The moment you introduce separate services and network calls, you set the stage for failures, latency spikes, retries, and only partial successes.
The Challenge with Traditional Transactions
In monoliths, you might solve this with a database transaction (ACID guarantees). But in distributed systems, two-phase commits (2PC) become risky, hard to scale, brittle under failure, and expensive in performance.
You're left with a painful tradeoff: consistency vs availability.
That's where sagas come in.
👉 Quick sidenote: if you're gluing together retries, compensations, and half-broken workflows…
You might want to check out Kestra.
It's an open-source, event-driven orchestration platform that makes it way easier to build, monitor, and scale complex flows, including distributed ones like SAGAs. You write in YAML, plug into your existing stack (Terraform, Slack, DBs, etc.), and get full visibility when things go sideways.
I've been playing with it lately and it just… clicks.
They already had my ⭐️.
What Is a Saga?
A Saga is a design pattern for managing long-running distributed transactions through a sequence of local transactions, coordinated with events or commands.
Instead of relying on locks or global transactions, each service performs its own local operation, and if something fails later, a compensating transaction is invoked to undo previous steps.
In other words:
Forward-only steps, with explicit undo logic.
🧭 Orchestrated Sagas: The Central Brain
In an orchestrated saga, a central coordinator (called the orchestrator) defines and manages the order of operations.
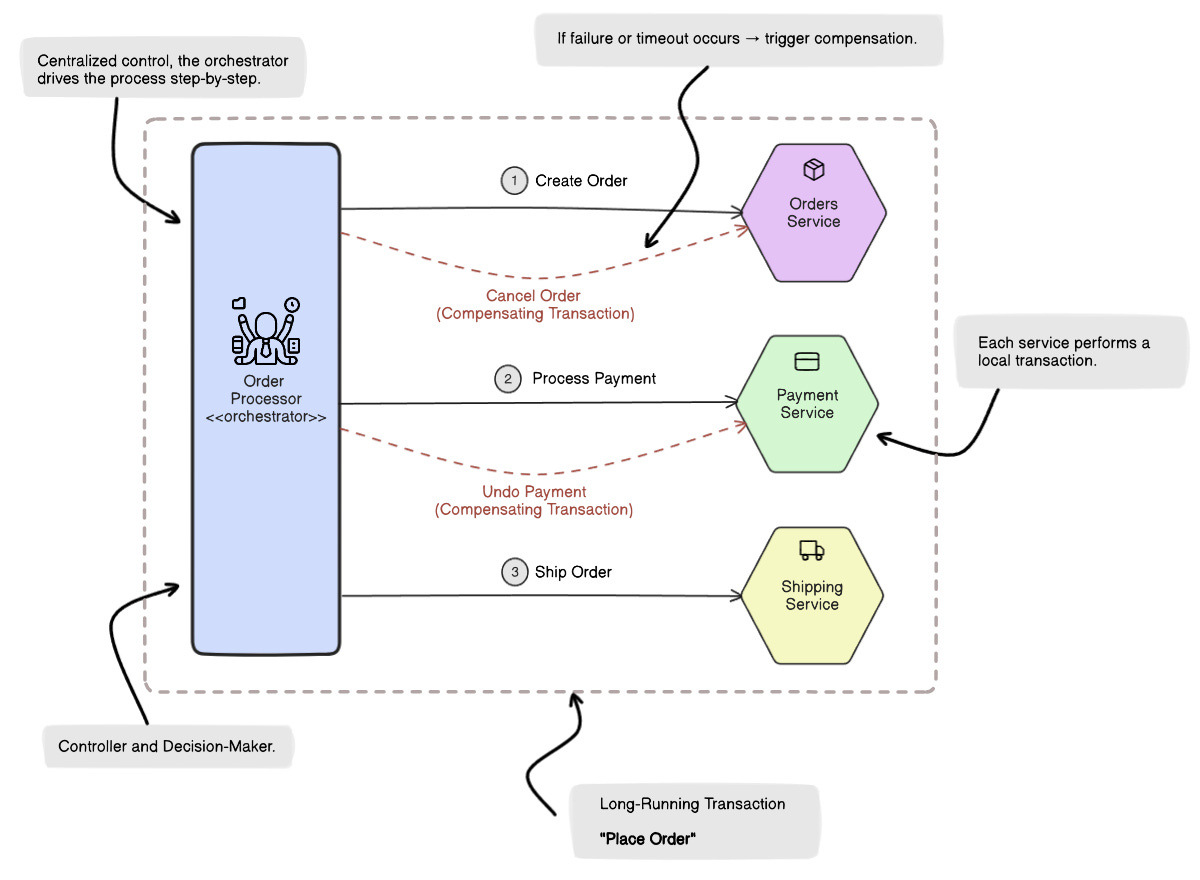
Think of it like a conductor:
“Service A: place order.” → “Service B: charge payment.” → “Service C: ship package.”
The orchestrator explicitly calls each step. If anything fails, the orchestrator triggers the appropriate compensation, like cancelling the order or refunding the payment.
✅ Pros:
Clear control flow and centralized logic
Easier to test and debug
Easier to visualize
❌ Cons:
Orchestrator becomes a single point of failure
Can become a coordination bottleneck between teams
Slower to evolve when different teams own services
Real-world example:
An e-commerce company I worked with used orchestrated sagas for order management. It worked well until the orchestrator failed under holiday load. Half-completed orders piled up, and coordination across services broke down.
The orchestrator was technically fine, but organizationally fragile.
🔀 Choreographed Sagas: Domain Events + Distributed Ownership
In choreographed sagas, there's no central conductor. Each service listens for and emits events to progress the flow.

Service A publishes “Order Created.”
Service B listens and emits “Inventory Reserved.”
Service C listens and emits “Order Shipped.”
No central logic, just a chain of reactions.
✅ Pros:
Team autonomy: Each team owns its part.
Scales across domains: No need for central coordination.
Loose coupling: Easier to evolve services independently.
❌ Cons:
Flow invisibility: Harder to see the full process in one place.
Complex compensation: Rollbacks require scattered logic.
Harder to test end-to-end without observability tools.
Observability: The Missing Map
When you're dealing with distributed sagas, especially choreographed ones, observability isn't optional. It's how you make sense of chaos.
You need to answer:
What triggered this flow?
Which services ran, in what order?
Where did it break?
And what needs to be compensated?
Recommended Tools & Practices:
Distributed tracing with OpenTelemetry, Jaeger, or Honeycomb:
Trace execution across services end-to-end.Structured logging with correlation IDs:
Pass trace IDs in every request to stitch logs into a coherent narrative.Centralized log aggregation (ELK, Loki, Datadog):
Keep everything searchable across services, regions, and retries.Custom dashboards for saga metrics:
Monitor failure rates, compensation triggers, and flow durations.
Without visibility, sagas devolve into distributed guesswork.
A Quick Cheatsheet

Here is how I decide which one to use
Personally, I've leaned more toward choreographed sagas, especially when the business process spans multiple teams. It's not perfect, but the autonomy and flexibility it gives outweigh the tracing complexity (most days 😅).
That said, orchestrated sagas can be a great choice when one team owns the entire process and wants clarity over autonomy.
One final tip: You can combine them by orchestrating critical paths (e.g., payments) with choreography for non-critical actions (e.g., notifications).

So… how do you handle distributed transactions?
Do you lean toward orchestration, choreography, or try to avoid the problem entirely through event stores, retries, or outbox patterns?
Hit reply or drop a comment, I'd love to hear your war stories.
“Most complexity isn't in code or data — it's in the space between them.”
Until next time,
— Raul
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a paid subscriber.
Quick and easy to follow introduction to sagas, thank you very much 👍
Great explanation Raul.
I especially liked the point about observability being a key player while implementing Sagas. Without that, it can become really difficult to make sense of things when they go wrong in a Saga flow. We realized that pain in one project a few years back, where multiple teams ended up blaming each other without any clear indication of which service was causing a particular issue.
Orchestration makes this somewhat easier as you mentioned, but again it's better to use that mainly if all services are within the team and you don't have to ping 5 people to understand what's happening...lol.