Dead Letter Queues (DLQs) are designed to catch messages your system can’t process after a certain number of retries. They’re supposed to give you breathing room. A second chance to act before data is lost.
But here’s what really happens in most systems:
Messages fail.
They get moved to a DLQ.
No one notices.
No one investigates.
Messages expire.
And the failure becomes permanent.
Let’s break down why this happens and how to fix it.
Cut Code Review Time & Bugs in Half
Code reviews are critical but time-consuming. CodeRabbit acts as your AI co-pilot, providing instant Code review comments and potential impacts of every pull request.
Beyond just flagging issues, CodeRabbit provides one-click fix suggestions and lets you define custom code quality rules using AST Grep patterns, catching subtle issues that traditional static analysis tools might miss.
CodeRabbit has so far reviewed more than 5 million PRs, installed on 1 million repositories, and used by 50 thousand Open-source projects. CodeRabbit is free for all open-source repo's.
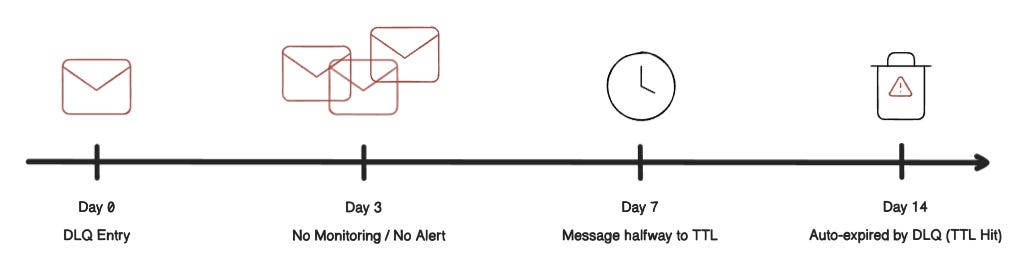
There’s no alert when messages arrive. No dashboard tracking queue size. No process to investigate what failed and why.
Failures go unnoticed for days or weeks, until someone stumbles across missing data or a downstream report looks off.
By then, it’s often too late.
Fix: Set up metrics for DLQ depth and message age. Trigger alerts when thresholds are breached. Make the DLQ part of your system health dashboard, not a hidden corner.
❌ Problem 2: Blind Redrives Create Loops
Some teams automate the reprocessing of messages from the DLQ. It sounds efficient, until it’s not.
Redriving a failed message without understanding why it failed is asking for trouble.
If the downstream service is still down, it will fail again.
If the payload format changed, it will fail again.
If your logic is flawed, it might break more than just that message.
Some systems allow messages to bounce between the main queue and the DLQ indefinitely. Others eventually discard them after repeated failure.
Fix: Don’t redrive blindly. Attach metadata when a message is moved to the DLQ: error type, timestamp, originating service, trace ID. Redrive only after the root cause has been addressed.
❌ Problem 3: Messages Disappear Without Warning
In systems like AWS SQS, messages in the DLQ are deleted after 14 days. That’s not configurable.
If no one processes them by then, they’re gone forever. No reprocessing. No audit trail. No accountability.
Fix: Track the age of DLQ messages. Alert when messages approach the expiration threshold. Set a regular cadence, weekly or even daily, for reviewing and draining DLQs.
❌ Problem 4: DLQs Flatten Context
DLQs often act as a catch-all. Every failure, regardless of cause, ends up in the same place, with no context.
But not all failures are equal:
Some are malformed payloads.
Some are caused by missing downstream services.
Some are just business rule violations.
And if you treat them all the same, you make triage harder and slower.
Fix: Tag DLQ messages with structured metadata:
Failure category
Originating service
Timestamp
Retry count
Root cause summary (if available)
This turns your DLQ from a black hole into an observable failure pipeline.
Most systems—like AWS SQS, Azure Service Bus, Kafka, RabbitMQ—automatically move messages to a DLQ after the max retry threshold is hit. But:
❌ They don’t let you customize the DLQ message payload during that move. ✅ They only move the original message, untouched.
So if you want to include useful debugging metadata:
You must intercept the failure and publish to the DLQ yourself.
You must implement the logic to inspect, validate, and retry the failed messages.
These are tradeoffs you have to take into account!
⚖️ The Tradeoffs: DLQ Pros and Cons
A DLQ is a safety valve, not a safety net. It gives you a buffer, but only if you actively manage it.
✅ What Good DLQ Practice Looks Like
Here’s what a solid DLQ process includes:
Monitoring & Alerting Real-time metrics on DLQ size, age, and throughput.
Triage Automation Automatically classify failure reasons and separate transient from permanent.
Structured Logging Include trace IDs, service names, error codes, and timestamps in every failed message.
Human Ownership Assign a team to own the DLQ and act on it within defined SLAs.
Safe Reprocessing Tools that deduplicate, validate, and replay only when the root cause is resolved.
The question is not “Do you have a DLQ?” It’s “Do you actually know what’s in it, and are you doing something about it?”
Final Thoughts
A DLQ shows you where your system is failing. But only if you’re looking.
Most teams aren’t.
They quietly lose data, miss signals, and assume everything is fine until a customer reports something missing, and no one knows why.
DLQs are not backups. They are broken promises waiting to be discovered. Own them. Monitor them. Triage them. Fix the root causes.
That’s how you build resilience, for real.
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a paid subscriber.






'It gives you a buffer, but only if you actively manage it.' 100%, otherwise it's just wasted resources.
This is very insightful. Thank you