
CAP questions almost never appear labeled as “CAP theorem.”
They show up disguised as simple data questions.

This is one of the trickiest questions I have heard in system design interviews:
Can a system be accurate but inconsistent?
Many candidates pause here because the phrase sounds like an oxymoron; something contradictory that shouldn’t even be possible.
It is not.
Understanding this possibility is important because distributed systems constantly separate accuracy & consistency.
And once systems scale across replicas and regions, the gap between accuracy and consistency becomes impossible to ignore.
To see why, we first need to define what those terms actually mean.
The best way to build any app
Most “AI app builders” aren’t actually app builders. They are infrastructure middlemen. You live inside their box, choose from their secret stack, and force you to start over the moment you want to use a different database, payment processor, or tool. With Orchids:
You’re not locked-in to Supabase or Stripe.
Not forced to spend credits, bring your own AI subscriptions with you.
One-click deployment straight to Vercel
Build anything. From Web, mobile, internal tools, browser extensions, scripts, and bots. Orchids.app is capable of building anything that you can put your mind to.
Use code MARCH15 for 15% off (one-time discount).
Accuracy vs Consistency
Let’s start with the definitions.
Accuracy means the data reflects the real-world value.
Consistency can mean different things depending on context.
In casual conversations, engineers sometimes mean “replicas return the same value.”
In the CAP theorem, consistency specifically refers to linearizability, where reads always see the most recent committed write.
In a single database running on one machine, these usually appear together.
The correct value is written once, and every read returns that same value.
But distributed systems introduce replication.
Multiple nodes store copies of the same data.
Those copies must stay synchronized.
That synchronization delay is exactly where accuracy and consistency begin to diverge.
The confusion happens because small systems usually give you both properties at the same time.
And the easiest way to see that is through a very common scenario: a system that is accurate but temporarily inconsistent.
Accurate but inconsistent
This situation happens constantly in distributed systems.
Imagine a user updating their email address.
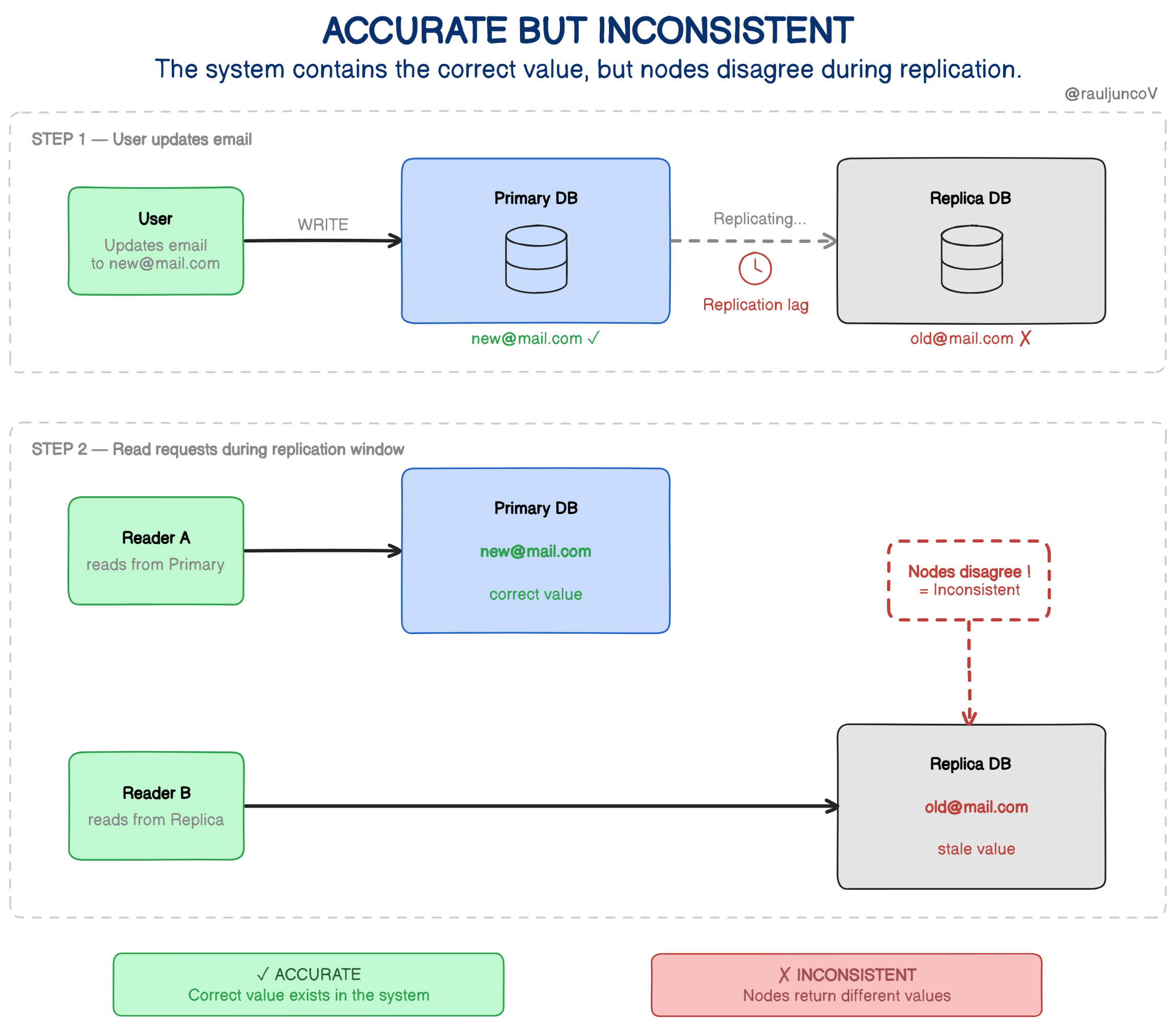
Now imagine a read request arrives during that replication window.
The primary database returns the new email.
A replica still returns the old one.
Some users see the new value.
Others see the old one.
The system already contains the correct value, so it is accurate.
But the nodes do not agree yet, so it is inconsistent.
This behavior appears in systems using:
read replicas
multi-region databases
asynchronous replication
eventual consistency models
The inconsistency usually resolves itself once replication finishes.
But not all inconsistencies are temporary. In fact, the more dangerous scenario is when a system becomes perfectly consistent while being completely wrong.
Consistent but inaccurate
Now consider a different situation.
A bug writes the wrong tax rate.
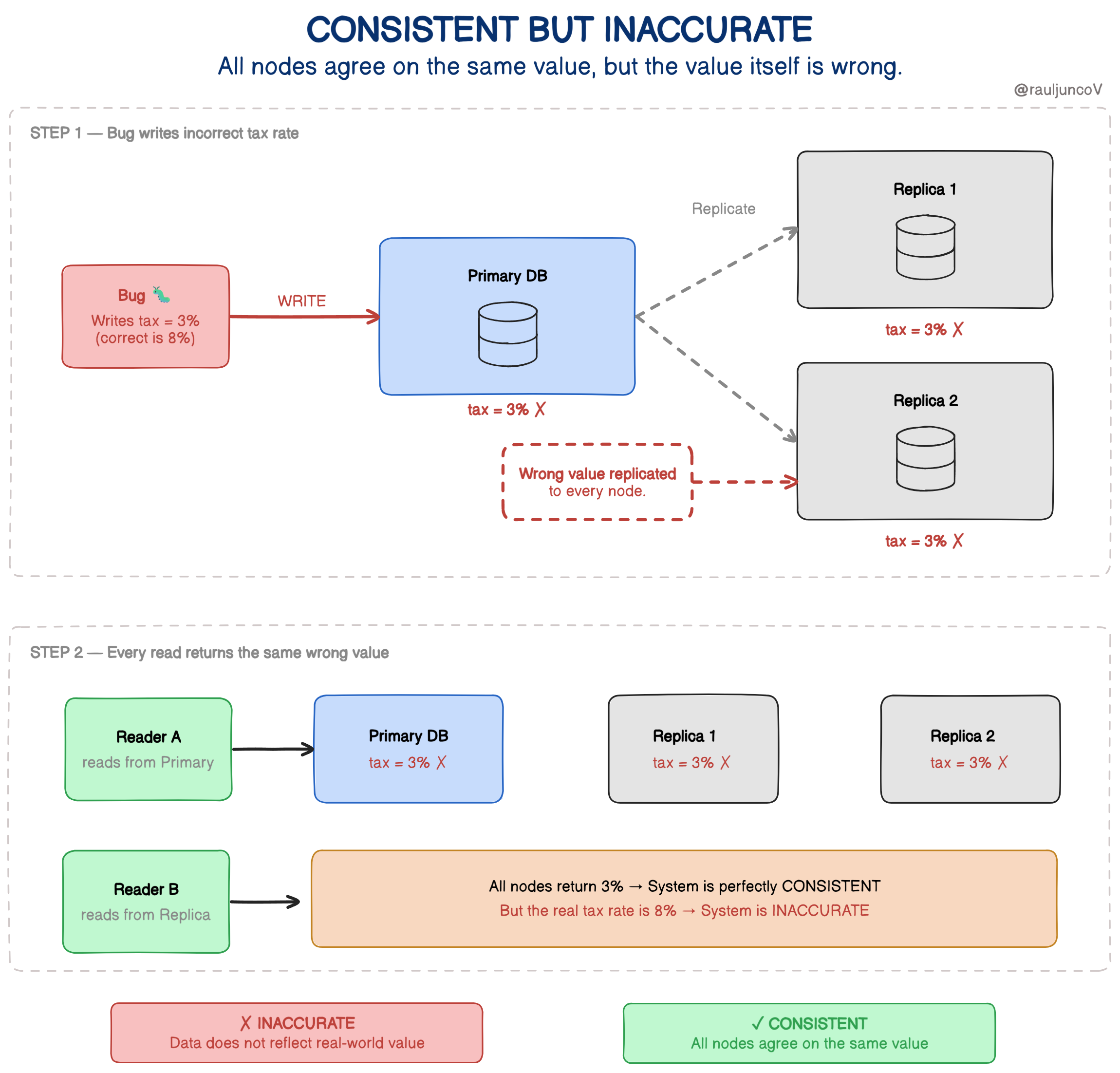
Every node returns the same number.
The system is now perfectly consistent.
But the number itself is incorrect.
Consistency guarantees agreement about the relative order of reads and writes as observed by clients, in a way that behaves like a single global log.
It does not guarantee correctness.
A distributed system can synchronize bad data just as efficiently as good data.
This is why strong consistency does not protect a system from logical errors.
And that leads to one of the most common misunderstandings engineers have about the CAP theorem.
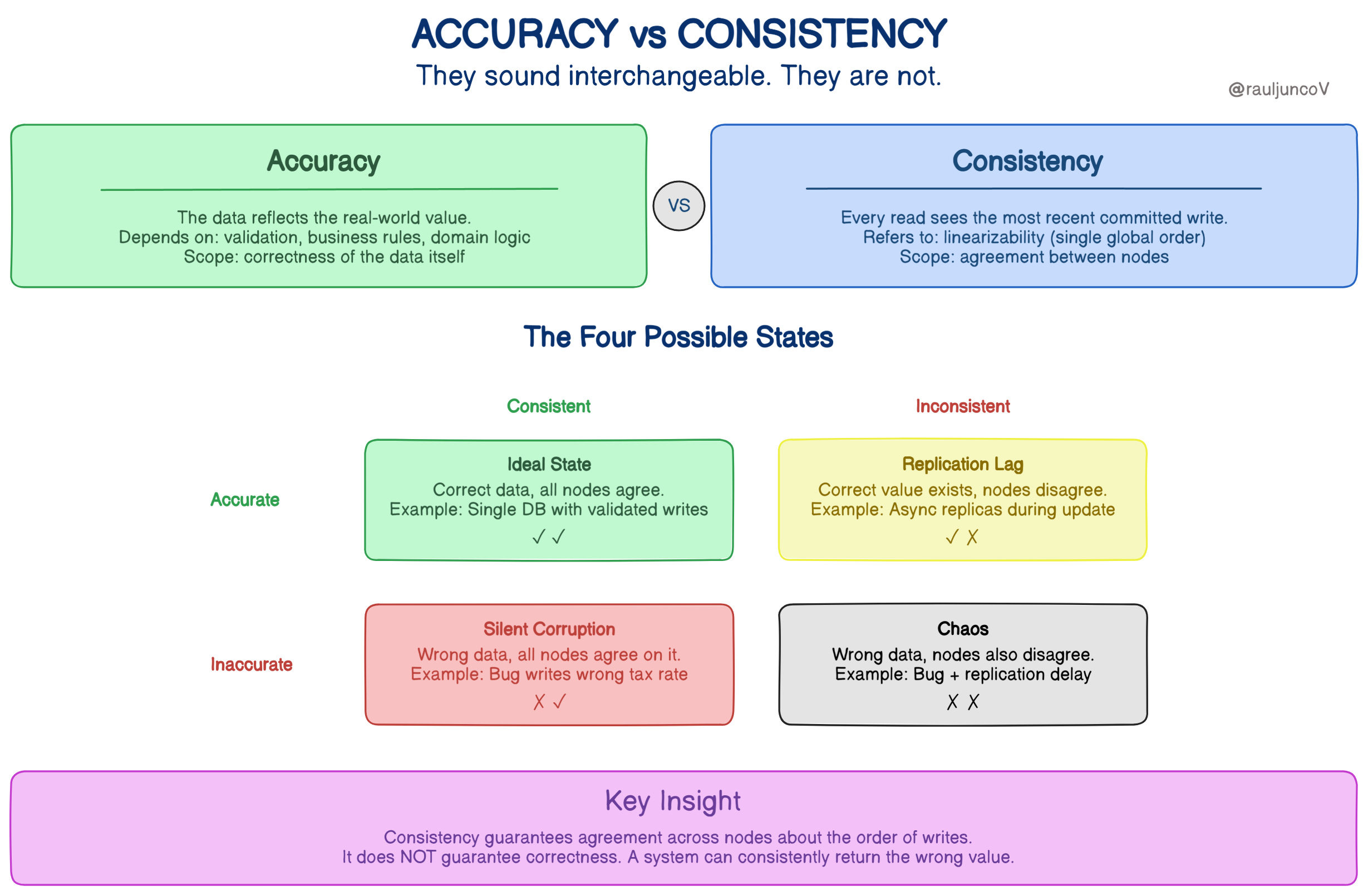
The CAP misconception
Many engineers assume strong consistency prevents incorrect data.
But that’s not what the CAP theorem promises.
In the CAP theorem, consistency refers to linearizability: every read appears to see the most recent completed write as if all operations happened in a single global order.
This is different from the everyday meaning of “replicas having the same value” or SQL-style consistency constraints.
If the write itself is wrong, the system will consistently return the wrong value everywhere.
In other words:
Consistency protects agreement about the order of writes, not the truth of the data itself.
Truth depends on things like:
application validation
business rules
transactional safeguards
domain logic
Distributed systems coordinate during and after writes so nodes agree on the result.
Many production systems relax this guarantee and instead provide eventual consistency, where replicas may temporarily diverge but converge over time.
But that agreement comes at a cost, because coordinating nodes across machines or regions is never free.
The latency tax of coordination
Strong consistency requires nodes to coordinate before confirming a write.
A typical strongly consistent write looks like this:
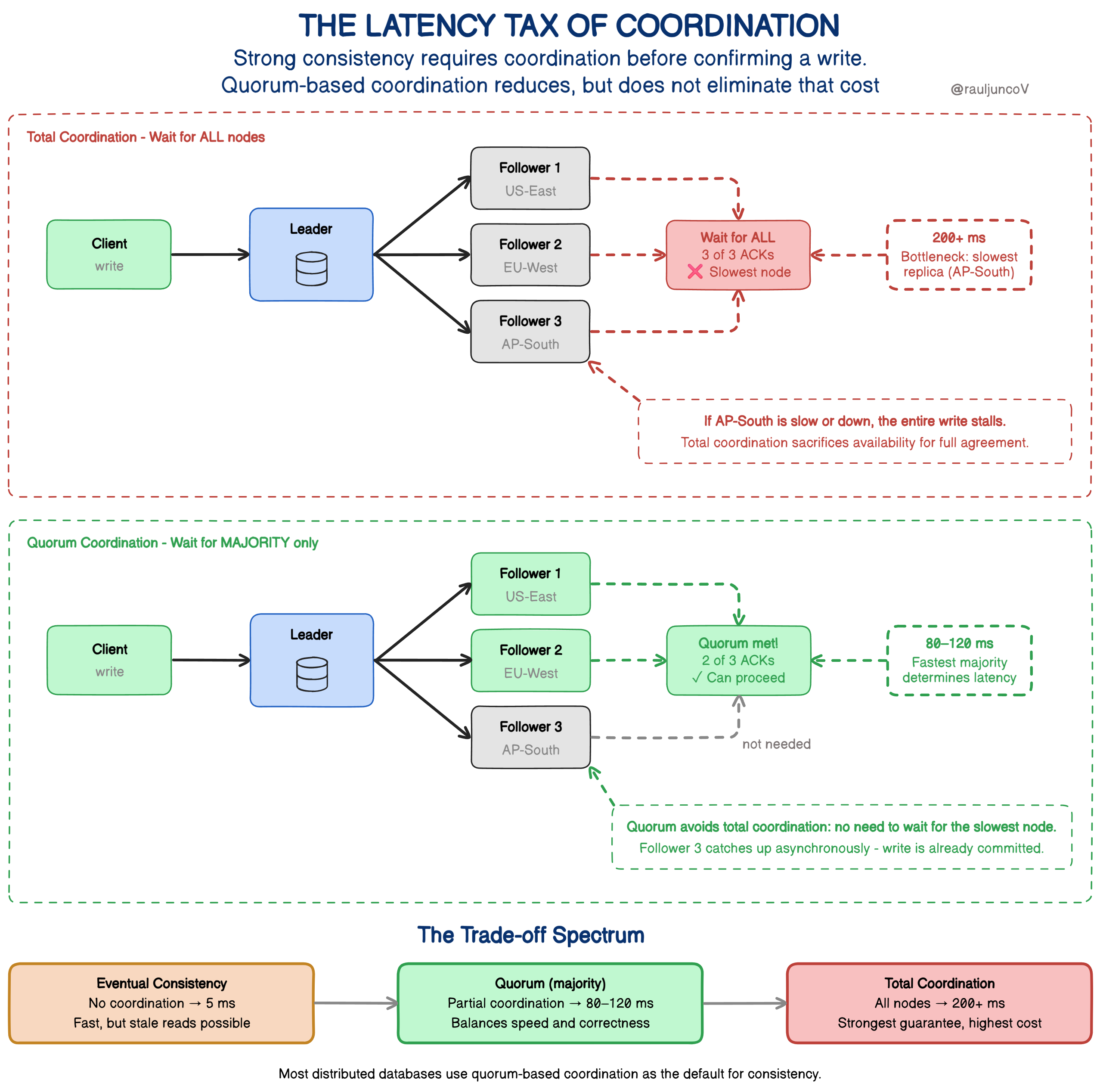
Each additional replica adds more communication.
Across regions, this becomes expensive.
A write that takes 5 ms locally might take 80–200 ms globally.
At scale, that latency affects user experience.
To avoid that cost, many distributed systems allow writes to succeed without waiting for every replica to confirm.
Updates propagate asynchronously.
This reduces latency but introduces temporary inconsistency.
Strong consistency requires coordination between nodes before a write is considered committed.
Most distributed databases implement this using quorums or consensus protocols, where a majority of replicas must acknowledge the write.
And different products choose different approaches depending on what matters most for the system.
Why systems choose different trade-offs
Architecture decisions always depend on the domain.
Some systems must guarantee correctness immediately.
Others must prioritize speed and availability.
Systems that require strong consistency
These domains cannot tolerate incorrect values:
banking balances
payment processing
financial ledgers
inventory reservations
If two nodes approve the same payment simultaneously, the system could double-charge a user.
To prevent that, these systems accept the latency cost of coordination.
Correctness with respect to business invariants must be guaranteed before a transaction commits.
But not every system faces that constraint.
Systems that accept eventual consistency
Other domains prioritize responsiveness and global scale:
social feeds
analytics dashboards
recommendation engines
caching layers
If a post appears a few seconds later in another region, the user experience barely changes.
But forcing every write to coordinate globally would slow the system dramatically.
These architectures allow temporary inconsistency while updates propagate across replicas.
Eventually, all nodes converge to the same value.
And that design decision reveals the real lesson behind CAP.

The real lesson of CAP
The CAP theorem often appears in textbooks as a theoretical concept.
In practice, it represents a constant architectural choice.
Every distributed system must balance:
coordination cost
latency
availability
correctness guarantees
At a small scale, these trade-offs are easy to ignore.
But once systems span multiple replicas, regions, and networks, they become unavoidable.
Which is why the real challenge in system design isn’t eliminating trade-offs.
It’s deciding which trade-off hurts the least.
Final thought
Distributed systems will always contain imperfections.
Nodes fail.
Networks partition.
Replication lags.
You cannot design those problems away.
But you can decide how the system behaves when they happen.
A system can be:
accurate but temporarily inconsistent (replication lag)
consistent but permanently wrong (a bad write replicated everywhere)
both inaccurate and inconsistent (bugs combined with replication delay)
And the architecture determines which one occurs.
Good engineers don’t try to build perfect systems.
They design systems where the inevitable failure mode causes the least damage.
Because at scale, system design isn’t about perfection.
It’s about choosing the right compromise.
Until next time,
— Raul
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a paid subscriber.
Simple and nicely explained. Thanks
It's always a game of tradeoffs. This was a great breakdown of CAP Theorem. Another great article Raul!