
Consistency is negotiable. But the bill always lands somewhere.
Linearizable, causal, eventual, and quorum: how to pick the right consistency guarantee for each workflow in your system.

In distributed systems, consistency is not something you maximize by default. It is something you buy.
The stronger the guarantee, the more you usually pay in latency, coordination, availability, or operational complexity.
That is why the real question is never “Do we want consistency?” Every system wants some form of it. The real question is how much correctness this workflow needs, how fast it needs to be, and what kind of failure the business can survive.
That difference matters more than most architecture diagrams admit.

A banking ledger and a social media like counter should not carry the same consistency guarantees. If you give both the same answer, you either slow down the cheap path or underprotect the expensive one.
This is the tension the CAP theorem formalizes: during a network partition, a distributed system must choose between consistency and availability. You cannot have both. The PACELC extension adds that even without partitions, you still trade latency for consistency. Either way, consistency has a price tag.
To make that trade-off well, you need a clean mental model first.
Your AI shouldn’t grade its own homework
Claude Code writes beautiful code. So does Codex. But here’s the thing, they also think they write beautiful code. And when you ask an AI to review code it just wrote, you get the intellectual equivalent of a student grading their own exam. Shockingly, they always pass.
CodeRabbit CLI plugs into Claude Code and Codex as an external reviewer, different AI Agent, different architecture, 40+ static analyzers and zero emotional attachment to the code it’s looking at. The agent writes, CodeRabbit reviews, and the agent fixes. Loop until clean.
You show up when there’s actually something worth approving.
One command. Autonomous generate-review-iterate cycles. The AI still does the work. It just doesn’t get to decide if the work is good anymore.
What consistency really means
Consistency answers a very practical question: after a write happens, what are readers allowed to see?
If one user updates data, can another user read that new value immediately from any node? Can some replicas still return the old value for a while? Can different users observe different versions of the same record at roughly the same time? These are not edge questions. Instead, they are the core of distributed data behavior.
Take a simple example. A user likes a photo, and the count moves from 99 to 100. If another user refreshes the page a moment later, should they always see 100? If the answer is yes, you need a stronger consistency model. If seeing 99 for a few seconds is acceptable, then you can afford a weaker one and gain performance or availability in return.
That sounds simple on paper. It becomes much more expensive the moment the data no longer lives on one machine.
Why consistency gets expensive fast
A single-node system does not need much coordination. One source of truth handles the write, and every read comes from the same place. Life is easy until scale, redundancy, or regional distribution enters the picture.
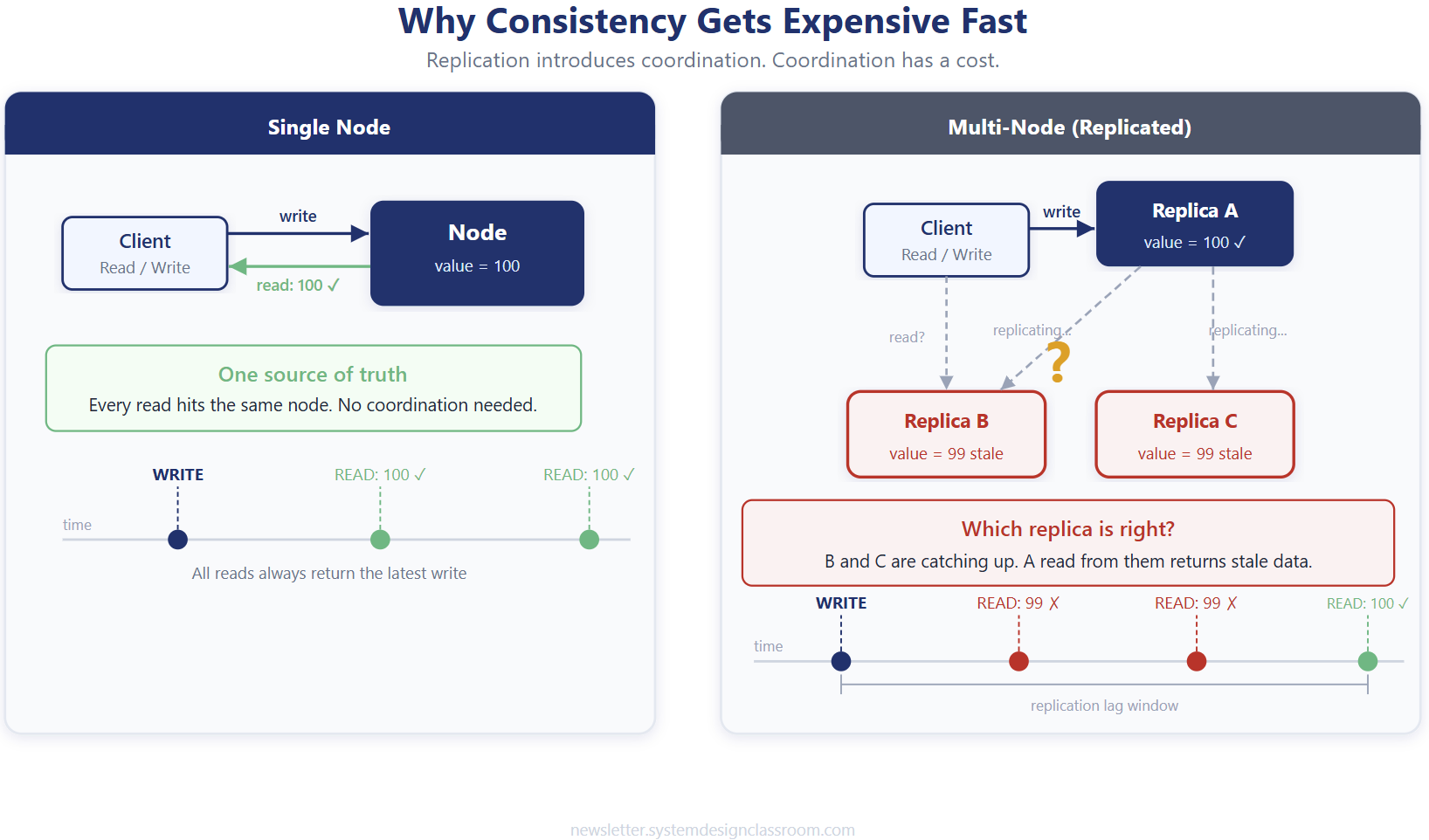
The second you replicate data across multiple nodes, you introduce a new problem: agreement. Which replica gets the write first? When do the others catch up? What happens if one replica is slow, partitioned, or unavailable? What does a reader do if two replicas disagree? Every one of those questions adds coordination, and coordination costs time.
A useful way to think about it is like a group chat trying to pick a restaurant. If everyone must agree before moving, the choice is accurate but slow. If one person decides and the others catch up later, the process moves fast but some people temporarily hold outdated information. Distributed systems play the same game, just with much harsher consequences.
Once you see consistency as a coordination problem, the different consistency models start to make more sense.
Linearizable consistency: the strict version
Linearizable consistency gives the strongest achievable guarantee in distributed systems. (Strict consistency, a theoretical model requiring instant propagation, is physically impossible across nodes, but linearizability comes as close as real hardware allows.)
Once a write completes, every later read must return that latest value. Not eventually. Not on most nodes. Immediately.
If a withdrawal changes an account balance from $500 to $300, no read that happens after that committed write should ever return $500 again. The system behaves as if every operation happened in one single global order, even if the implementation underneath uses multiple nodes.
That guarantee is powerful because it matches what humans instinctively expect from critical state. If money moved, if a lock was acquired, if a seat was sold, the answer should not depend on which node answered the read. For ledgers, distributed locks, final inventory allocation, leader election, and other correctness-sensitive paths, this model is often worth the cost.
The problem is that the cost is real. Strong consistency usually forces synchronous coordination between replicas or a leader-based commit path. That increases latency and makes failure handling harder. A slow node can delay the write path. A partition can force the system to reject operations rather than risk conflicting truth. In other words, strict correctness narrows your margin for speed and availability.
That tension is exactly why many systems relax consistency where they can and reserve the strongest guarantees for where they truly need them.
Causal consistency: keep the story in order
Causal consistency relaxes the model without throwing away meaningful ordering. It does not force the entire system into one universal timeline. Instead, it preserves the order of related operations.
That distinction matters more than it sounds. If Alice creates a post and then comments on it, other users should not see the comment before the post exists. Those actions have a causal relationship. One depends on the other. But if Bob likes a completely different post, that event has no causal connection to Alice’s sequence, so the system does not need to serialize both into one global order.
This makes causal consistency a good fit for systems where ordering matters within a context but not across the whole platform. Social feeds, comments, messaging threads, collaborative editing, and event timelines often benefit from this middle ground. It keeps the user-visible story coherent without paying the full price of strict global coordination.
You can think of it like this: linearizability says every event in the universe must line up in one clean row. Causal consistency says only the events that influence each other need to stay in order. That is a much cheaper requirement, and in many products it is also the smarter one.
Once you relax the need for a global order, the next natural step is to ask what happens when you relax freshness even more.
Eventual consistency: converge later
Eventual consistency makes a simpler promise. If no new writes happen, all replicas will eventually converge to the same value.
That means the system allows stale reads during the replication window. One node may already have the new data while another still returns the old version. If you read from the wrong replica at the wrong moment, you can observe outdated information. The key point is that the disagreement is temporary, not permanent.
This model works well when temporary staleness does not create serious harm. Like counts, follower counts, analytics views, recommendation signals, search indexes, and many cache-heavy read models fit here. In those cases, speed and availability matter more than immediate global correctness. Users can tolerate a short lag as long as the system catches up.
The mistake teams make is assuming eventual consistency means “good enough for anything.” It does not. It only works when the product and the business can tolerate brief disagreement. If a dashboard lags by ten seconds, nobody calls legal. If an account balance lags by ten seconds, that is a different story.
So eventual consistency is not weak engineering. It is often strong engineering applied to the right problem. But once you accept that some flows can be stale, you still need a way to control how stale they can become in practice. That is where quorum becomes useful.
Quorum: consistency as a dial
Quorum turns consistency into something you can tune instead of something you must choose in one giant all-or-nothing decision.
Assume your data lives on N replicas. For each write, the system waits for acknowledgments from W replicas before considering the write successful. For each read, it consults R replicas before returning a value. Now the behavior depends on how those numbers overlap.
The core rule looks like this:
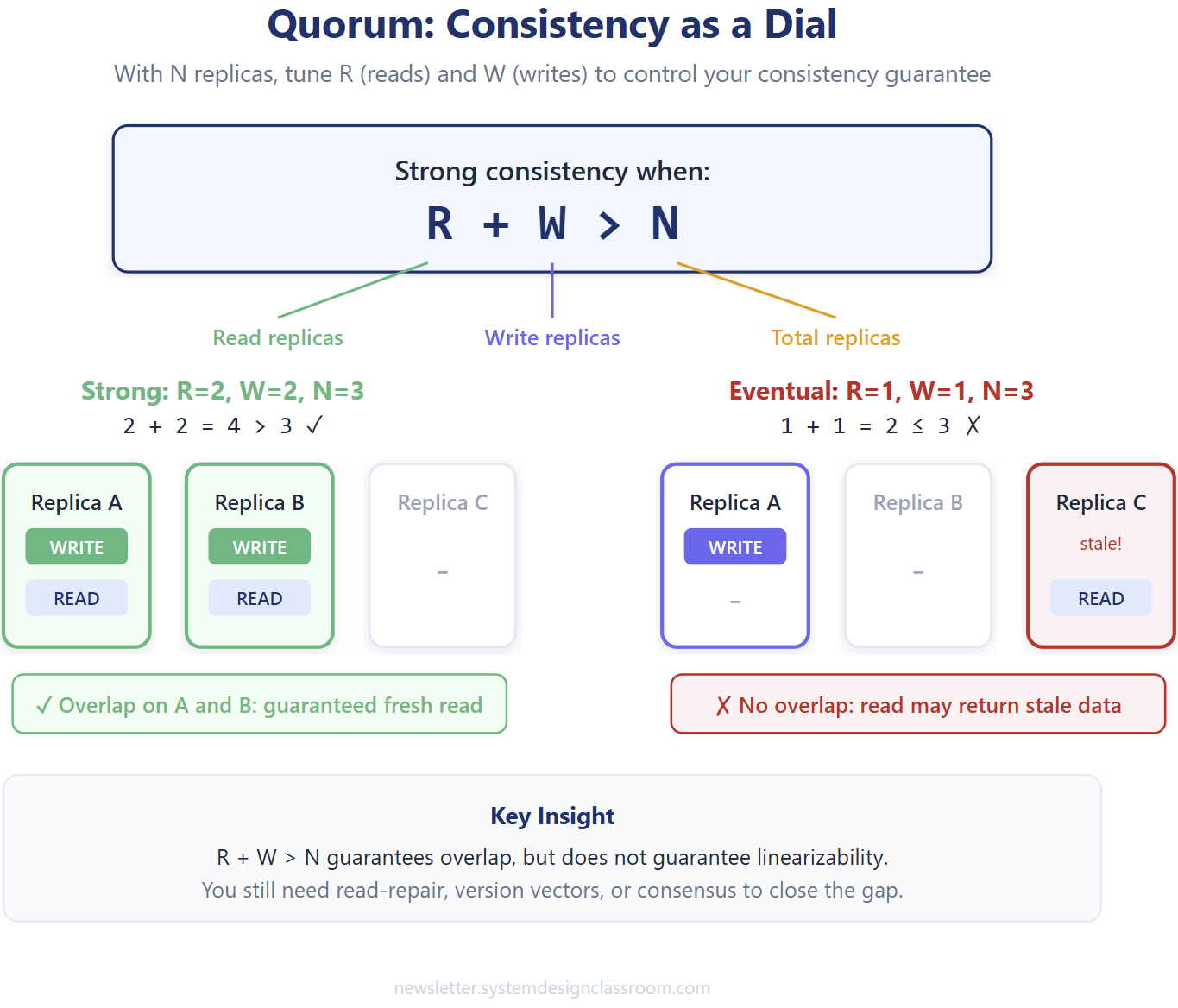
When that condition holds, reads and writes overlap on at least one replica. That overlap guarantees the read will contact at least one node holding the latest committed write. If the condition does not hold, a read can miss the newest write entirely and return stale data.
One important caveat: quorum overlap guarantees you reach a node with the latest value, but it does not automatically give you linearizable consistency. Without additional mechanisms like read-repair, version vectors, or a consensus protocol, the client could still pick a stale response from the quorum. Dynamo-style systems rely on these extra layers to close that gap.
Quorum is useful because it reflects real business trade-offs. You can favor stronger writes, stronger reads, or lower latency depending on the path.
You do not need banking-grade guarantees for every endpoint, but you also do not need to settle for blind eventual consistency everywhere.
The math is helpful, but the real value of quorum shows up when you stop thinking in replica formulas and start thinking in workflows.
One system can use multiple consistency models
A lot of teams make the mistake of asking, “What consistency model does our system use?” That question is usually too coarse to help.
Real systems often use several consistency models at once because different workflows carry different consequences when wrong. The checkout path in an e-commerce system should not follow the same consistency rules as the recommendation engine that suggests similar products. One moves money and inventory. The other moves probabilities.
That means architecture gets better when you assign consistency by boundary. Keep the critical state transitions strict. Let the derived views lag. Preserve causal order where users care about the sequence. Relax everything else that can safely converge later.
This is where the theory starts becoming practical, because most production systems do not fail from choosing the “wrong consistency philosophy.” They fail from applying the same consistency expectations to workflows with very different risk profiles.
The best way to make that concrete is to walk through a familiar backend flow.
A practical example: checkout
Imagine a checkout service. The user clicks “Buy now,” and the system must reserve inventory, charge payment, create the order, update analytics, refresh search indexing, and maybe trigger downstream recommendations.
Those actions do not all deserve the same consistency treatment.
The core transaction needs stronger guarantees. Inventory cannot oversell. Payment cannot double-charge. The order should not exist if the payment failed. That part of the system wants strict coordination around the source of truth.
But the side effects do not need to complete in lockstep with the order commit. Analytics can lag. Search indexing can lag. Recommendation signals can lag. Those are useful, but they are not allowed to hold the checkout hostage.
A simplified shape looks like this:
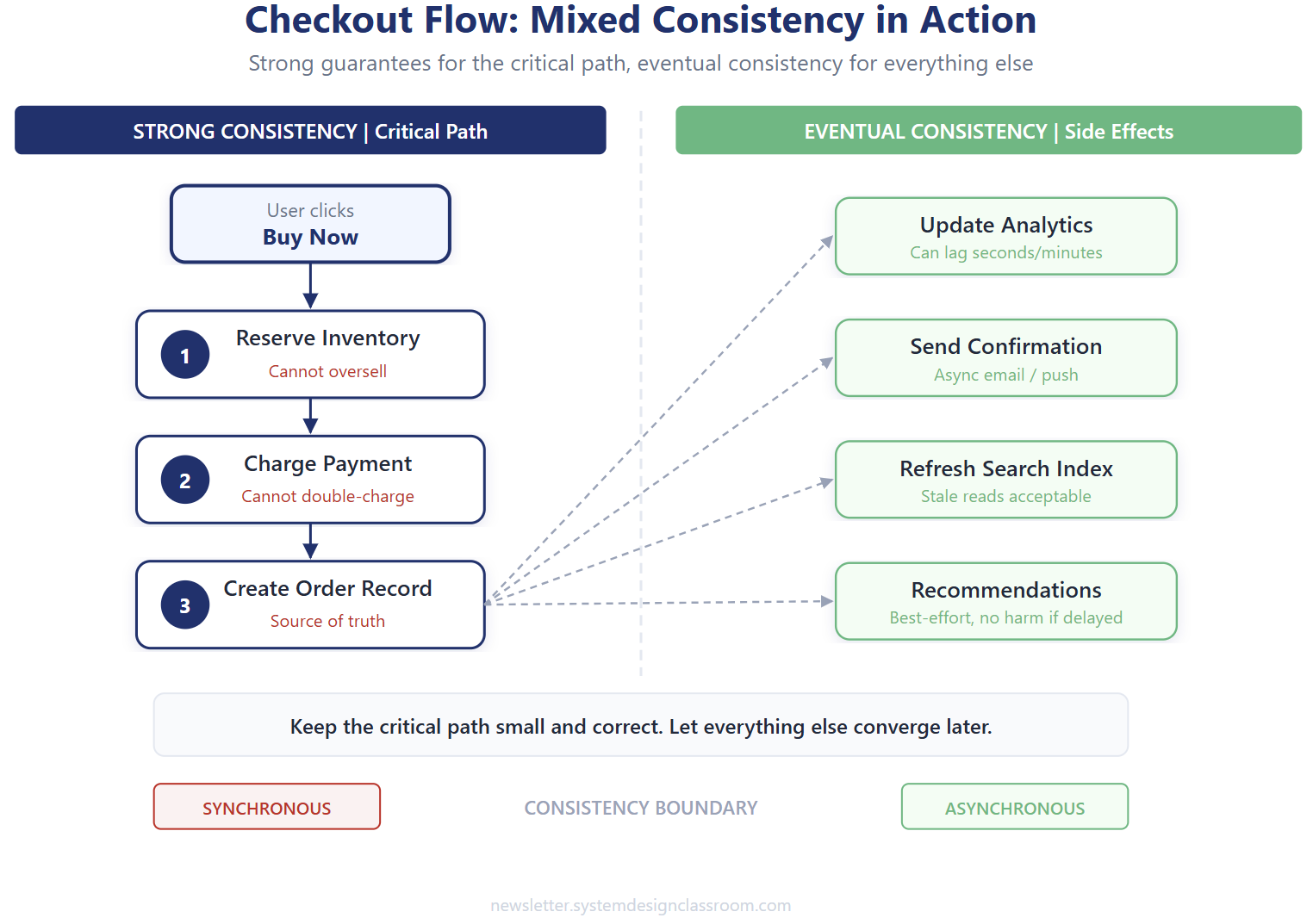
The front half needs stronger correctness. The back half can be eventually consistent. That split is one of the most useful instincts in modern system design.
This pattern keeps the business-critical state strong while allowing the rest of the platform to scale more cheaply. Once you see that split clearly, it becomes easier to spot the mistakes teams keep repeating.
Where teams get consistency wrong
The first mistake is demanding strong consistency everywhere. That sounds responsible, but it often creates unnecessary coordination, slower writes, and more fragility under failure. A system that insists on perfect agreement for low-value read paths usually ends up paying a premium for precision nobody needed.
The second mistake goes in the opposite direction. Teams choose eventual consistency because it sounds scalable, then forget to design the user experience and business rules around stale reads. That is how systems become confusing. A user updates something and then cannot see their own change. A retry creates duplicate actions. Two screens disagree and support has to explain why.
The third mistake is talking about consistency as if it were a property of the entire platform. That label is usually too vague to help. Billing may need one answer. Search may need another. Notifications may need a third. If you cannot point to the workflow, the term is probably too abstract to guide a real design choice.
The fourth mistake is ignoring local user expectations. Even when a system is eventually consistent overall, users still expect a form of “read your own write.” If they change their profile and refresh immediately, they expect to see the new version. That does not always require stronger global consistency, but it often requires a local solution such as sticky reads, session routing, or temporary client-side state.
These mistakes usually happen because teams ask the wrong question too early. Instead of asking what the workflow can tolerate, they argue about consistency models as if those were religious camps. A better design process starts with a smaller and more useful set of questions.
A practical decision framework
Start with consequence. If this read is stale, what breaks? Does the user get confused for a few seconds, or does the company lose money? That single question already eliminates a lot of noise.
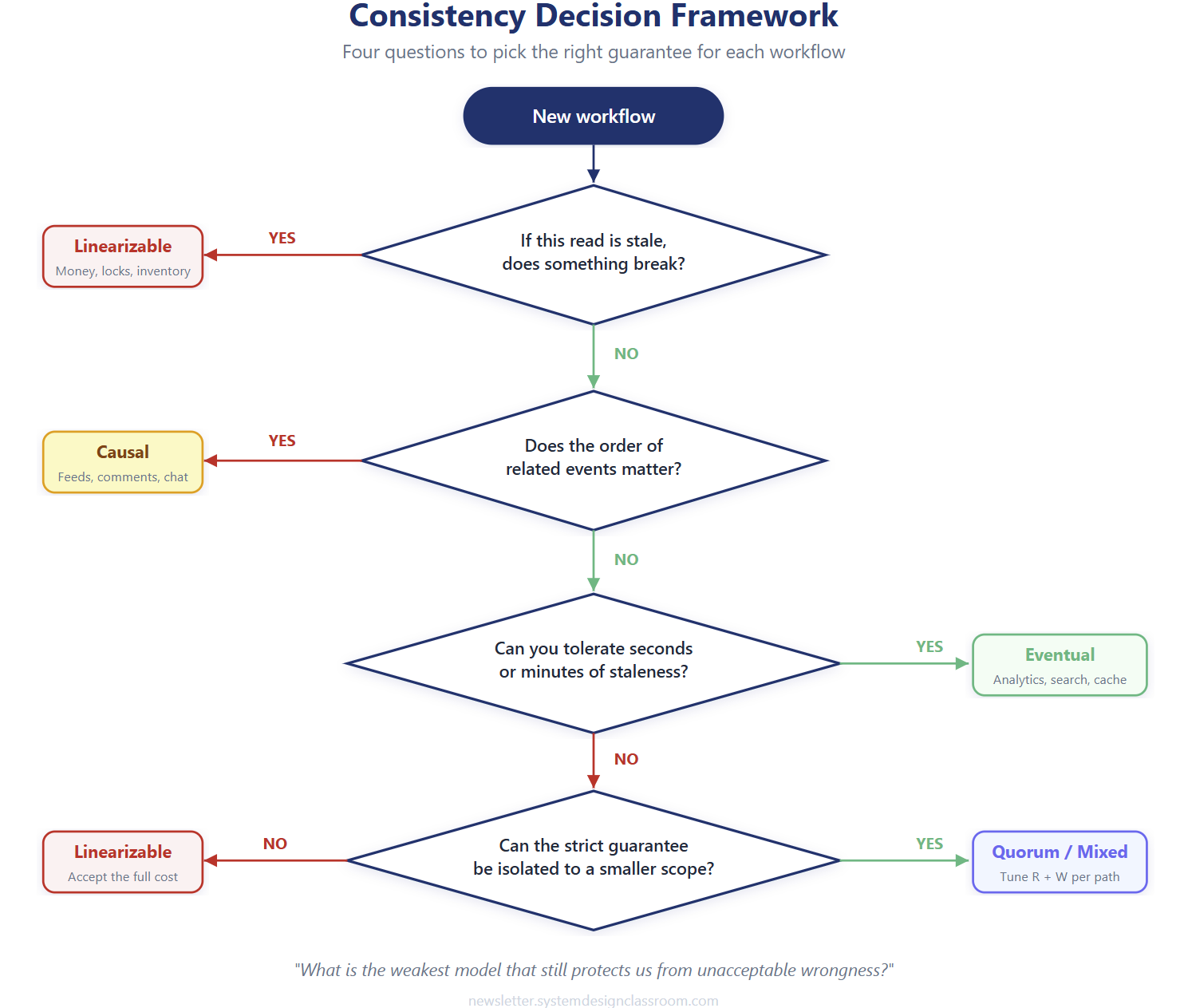
Then ask how long the inconsistency window can be. Some systems can tolerate a few hundred milliseconds. Others can tolerate minutes. A lot of design mistakes happen because teams never made that number explicit. They say “eventual is fine” without defining how eventual.
Next, ask whether ordering matters more than freshness. In some flows, the exact sequence matters even more than immediate visibility. That pushes you toward causal consistency patterns instead of either extreme.
Finally, ask whether the strict guarantee can be isolated to a smaller boundary. This is usually the highest-value move. Keep the critical path small and correct. Let projections, counters, and derived views update asynchronously. That gives you safety without dragging the whole platform into expensive coordination.
Experienced engineers rarely ask, “What is the strongest model we can afford?” They ask, “What is the weakest model that still protects us from unacceptable wrongness?” That question produces better trade-offs, and it naturally brings the article to its real conclusion.
The real lesson
Consistency is not about purity. It is about matching guarantees to consequences.
If being wrong for two seconds creates minor confusion, you should not pay the same price as a workflow where being wrong for two seconds creates irreversible damage. Distributed systems punish teams that flatten those differences.
That is why the strongest architectures usually do not chase one perfect consistency model. They split the problem. They use stricter guarantees where the source of truth changes hands, money moves, uniqueness matters, or double execution hurts. They use weaker guarantees where the data is derived, user-facing, or tolerant of lag. And when they need flexibility, they use quorum to tune the overlap between reads and writes.
Consistency is negotiable, but the cost never disappears. If you do not pay in coordination, you will pay in stale reads. If you do not pay in latency, you may pay in correctness. If you do not think through the trade-off upfront, production will think through it for you later.
That is the instinct worth sharpening: not maximum consistency, but the right consistency for the consequence of being wrong.
Takeaways
Consistency is not a default good. It is a trade you make against latency, availability, and complexity.
Linearizable consistency fits the paths where stale or conflicting state creates real damage. Causal consistency fits the paths where related events must stay in order. Eventual consistency fits the paths where temporary disagreement is acceptable. Quorum gives you a way to tune those trade-offs instead of treating them as binary.
And the most important pattern is this one: do not assign one consistency model to the whole system. Assign the right guarantee to each workflow, then let that decision shape the architecture that follows.
The moment you think that way, consistency stops being theory and starts becoming design.
Until next time,
— Raul
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a paid subscriber.