
Bad Retries Can Break Good Systems
A practical guide to using backoff, jitter, retry budgets, idempotency, and circuit breakers in backend systems.

A user places an order for the last item in stock.
Your API works. Your database works. Your deployment is fine.
But the call to the inventory service takes three seconds too long.
The request times out.
From the Order API’s point of view, the reservation failed. From the Inventory Service’s point of view, the item may already be reserved.
That gap is where bad retries create real damage.
Retry too aggressively, and you may reserve inventory twice. Do nothing, and the user may lose an item they actually reserved. Fail unclearly, and support gets the ticket later.
That is how transient faults hurt production systems.
They rarely start as dramatic outages. They start as small, temporary failures: a timeout, a dropped connection, a short latency spike, a busy dependency, or a gateway returning 503.
The first instinct is to retry.
That instinct is not wrong.
But it is incomplete.
Retries do not remove failure. They move pressure around. When you retry without limits, you send more traffic to a dependency that may already be slow, overloaded, restarting, rate-limited, or partially unavailable.
You may improve the success rate for one request while making the overall system less stable.
That is the uncomfortable truth about transient faults: they are usually small, they are usually temporary, and bad recovery logic can make them much worse.
The goal is not to avoid transient faults. In distributed systems, that is impossible. The goal is to make sure a temporary failure does not become a user-facing incident.
And that starts by understanding why retries can break good systems.
Your team’s second brain. Now in Slack.

Your engineers talk in Slack. They code in the terminal. Somewhere between those two things, context goes to die.
A bug was debated in #incidents at 2 AM.
An architectural call was made in a DM.
Every handoff leaks context and every leak costs you. That’s the context tax - and your team pays it every day.
CodeRabbit Agent for Slack is built for agentic SDLC workflows. One agent for your entire Software Development Lifecycle, living in the channel where the work already happens. It’s built on four things:
Context - your org’s operating picture, pulled from across code, tickets, docs, monitoring and cloud.
Knowledge Base - a living memory of your team. Every run leaves a trace, so yesterday’s decisions don’t become tomorrow’s debates.
Multi-Player - works in shared threads alongside your team. Steerable, resumable and aligned as work evolves.
Governance - scoped access, cost attribution. Every run explainable and attributed.
Your team keeps shipping. Agent keeps the context.
From the team that pioneered AI code reviews. 2M code reviews every week. 6M repos. 15K customers. And now, one agent for your entire SDLC, right in Slack.
The failure usually starts small
Imagine an order service calling an inventory service.
Most of the time, the flow is boring: the user places an order, the Order API asks the Inventory Service to reserve stock, the reservation succeeds, and the order moves forward.
Then one day, the inventory service has a brief issue. Maybe one node restarts. Maybe latency spikes for a few seconds. Maybe a database connection pool gets saturated. Maybe the warehouse integration slows down. Maybe the service reserves the item, but the response never reaches the Order API before the timeout.
Nothing catastrophic has happened yet. The inventory service is not permanently down. Your application is not completely broken. The request might succeed if you try again after a short delay.
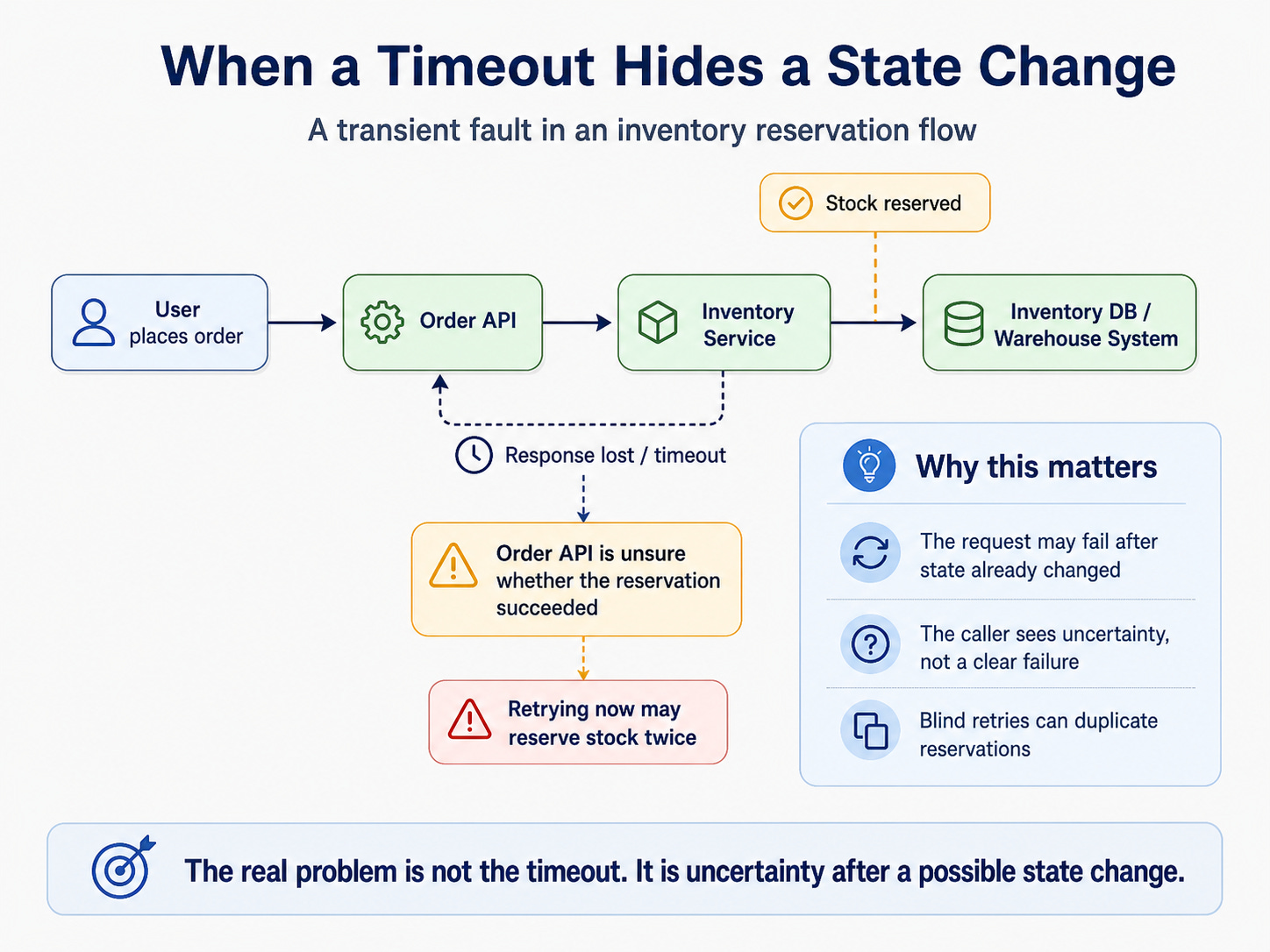
That is a transient fault: a short-lived failure that may resolve on its own.
Common examples include temporary network failures, connection timeouts, DNS hiccups, overloaded services, rate limits, or gateway errors such as 500, 502, 503, and 504.
The dangerous part is that transient faults look simple from the outside. A request failed, and the obvious answer seems to be “retry it.” But with inventory, the system may already have changed state before the caller saw the failure.
That creates uncertainty.
The real question is not only:
“Can this request succeed if we try again?”
The better question is:
“Can the system afford the retry, and is the retry safe?”
That distinction matters because every retry creates more work. It consumes CPU, memory, network bandwidth, thread pool capacity, database connections, queue throughput, and user patience.
A retry may help one request recover, but thousands of retries can push the system closer to failure.
That is where retries stop being a local fix and become a system-wide design decision.
And once retries become a system-wide decision, you need to understand how they amplify failure.
Retries can amplify failure
Imagine 10,000 clients calling your API. Your API calls a downstream dependency, and that dependency starts responding slowly.
The first few requests time out. Then more requests time out. Now clients, SDKs, workers, and services begin retrying.
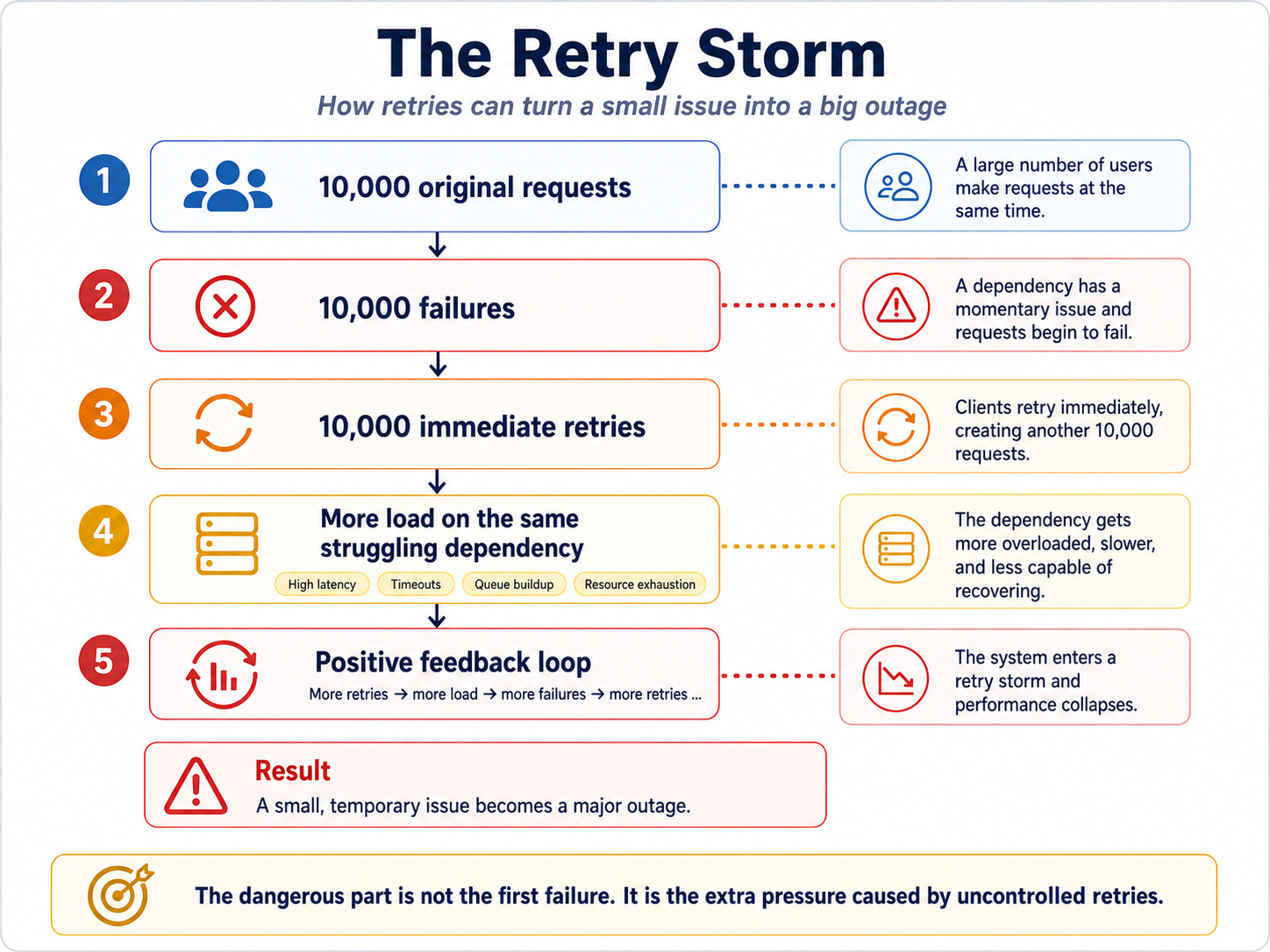
The dependency was already slow. Now it receives extra traffic from retry attempts. Some of those retries fail too, which creates even more retries. The system enters a feedback loop.
This is a retry storm.
A retry storm happens when many clients retry at the same time and increase pressure on an already unhealthy system.
This is why bad retry logic can be worse than no retry logic.
Without retries, users may see some failed requests. With uncontrolled retries, your whole system may slow down, your dependency may collapse, and unrelated features may start failing because shared resources get exhausted.
For example, a payment provider slowdown may consume your API thread pool. A database timeout may exhaust connection pools. A third-party API issue may cause queue workers to pile up. A temporary network failure may trigger retries across multiple services at once.
The failure starts in one dependency, but the blast radius expands because retry behavior spreads pressure through the system.
Retries should not behave like a tight loop that keeps asking, “Are you back yet?”
They should behave like a controlled recovery mechanism that gives the dependency time to recover.
The first control mechanism is backoff.
Use backoff because immediate retries are dangerous
Immediate retries only make sense in narrow cases.
For example, if a single connection dropped because of a tiny network hiccup, retrying immediately may work. But in many production systems, immediate retries create more pressure without giving the dependency any time to recover.
Exponential backoff solves this by increasing the wait time after each failed attempt.
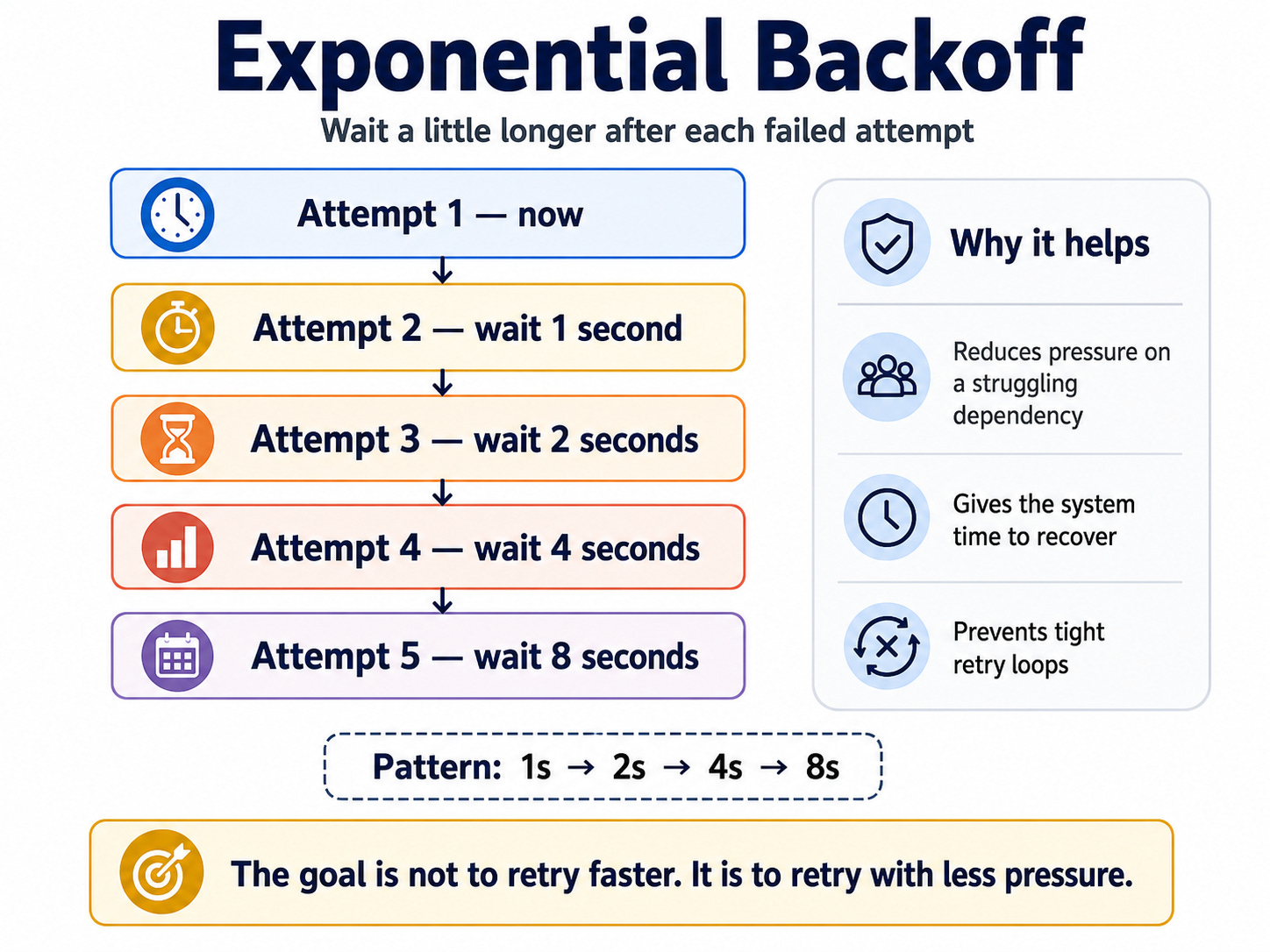
And it looks like this:
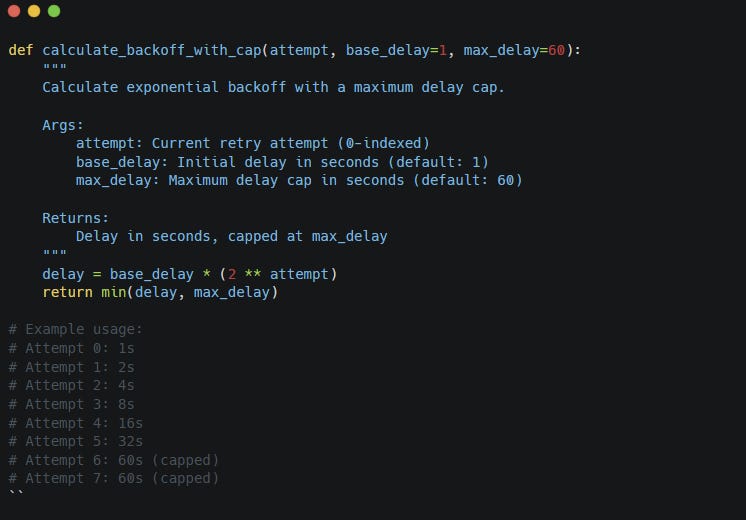
The idea is simple: the longer the failure continues, the less aggressively you retry. This protects the downstream service and reduces the chance that all clients keep hammering it while it recovers.
A basic retry loop might look like this:
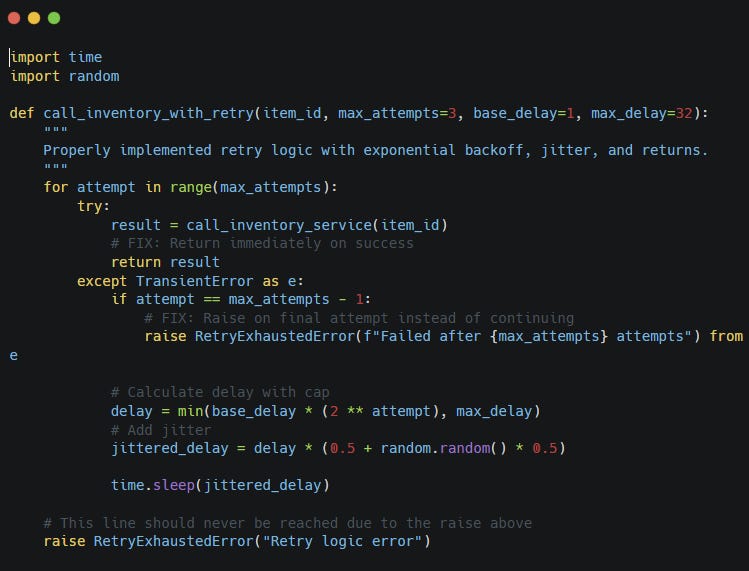
That avoids instant retry loops, but backoff alone still has a weakness.
If every client follows the same schedule, they may still retry together.
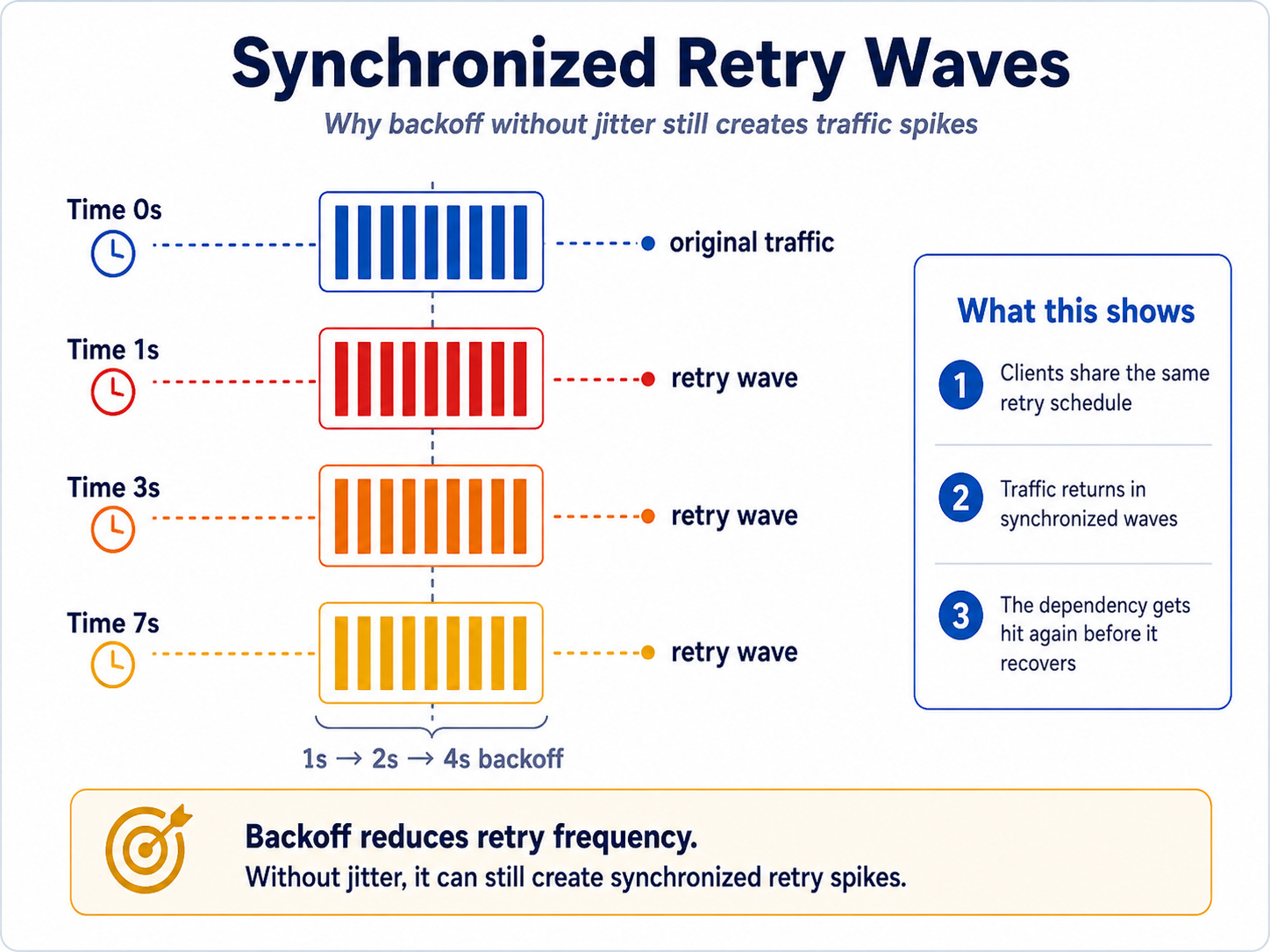
You reduced the retry frequency, but you created synchronized retry waves. When thousands of clients retry after the same delay, the dependency still receives traffic spikes at predictable intervals.
That is why you need jitter.
Jitter adds randomness to the delay so clients spread their retries over time. Here are three possible implementations.
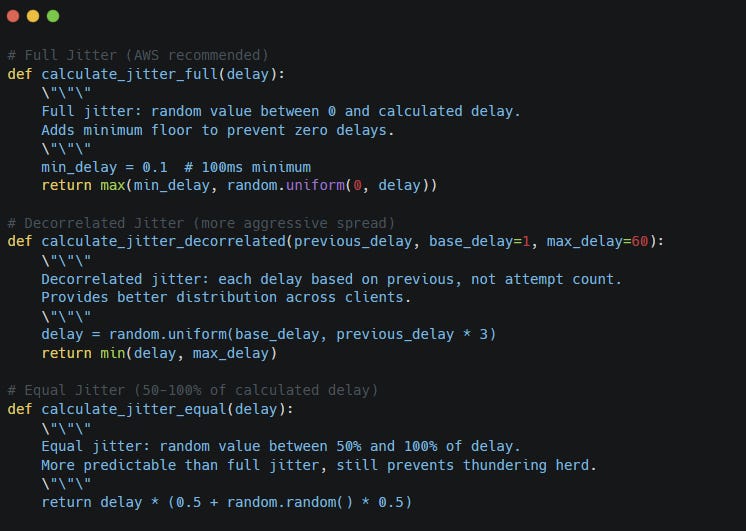
Now retries spread out instead of landing at the exact same moment.

Backoff reduces pressure. Jitter spreads pressure. Together, they make retries much safer.
But safer does not mean unlimited.
You still need to decide when retrying should stop.
That is where retry budgets come in.
Every retry needs a budget
Retries without a budget are denial with a loop.
At some point, your system needs to stop waiting and make a decision. That decision depends on the workload, the user expectation, and the business impact.
For a user-facing request, the time budget is usually small.
If a user clicks “Pay now,” they expect a response within a few seconds. Retrying for 30 seconds may technically improve the chance of success, but it creates a terrible user experience.
The user may refresh the page, click again, abandon the checkout, or contact support.
For a background job, the budget can be larger. A worker syncing invoices can retry over minutes or hours, back off between attempts, and eventually send the message to a dead-letter queue.
This is why retry policy should match the workload.
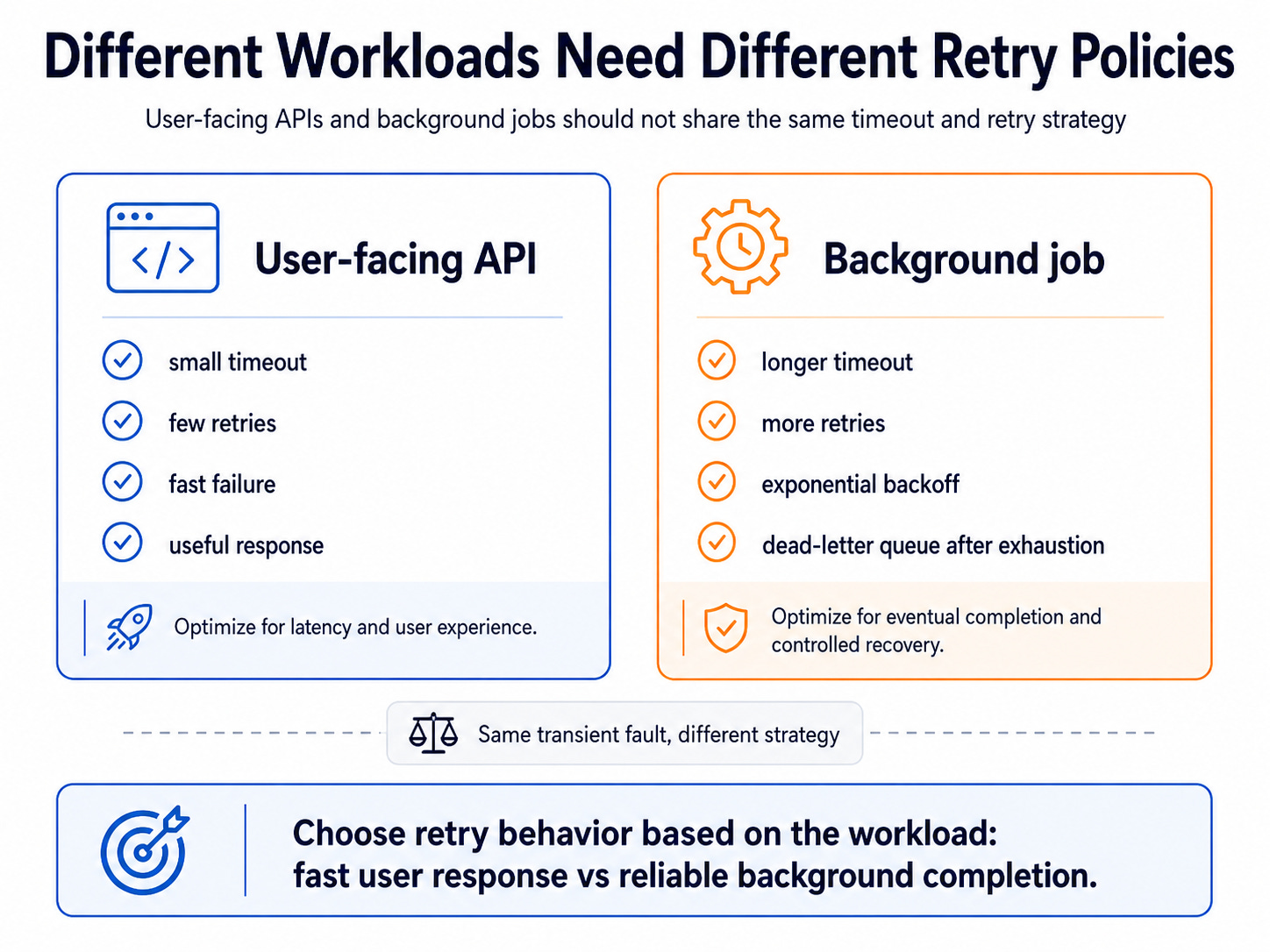
A practical retry policy usually needs three limits:
Max attempts: How many times can we retry?
Per-attempt timeout: How long can each attempt take?
Total time budget: How long can the whole operation take?
The total time budget matters because retry behavior often hides across layers.
The frontend may retry. The API may retry. The SDK may retry.
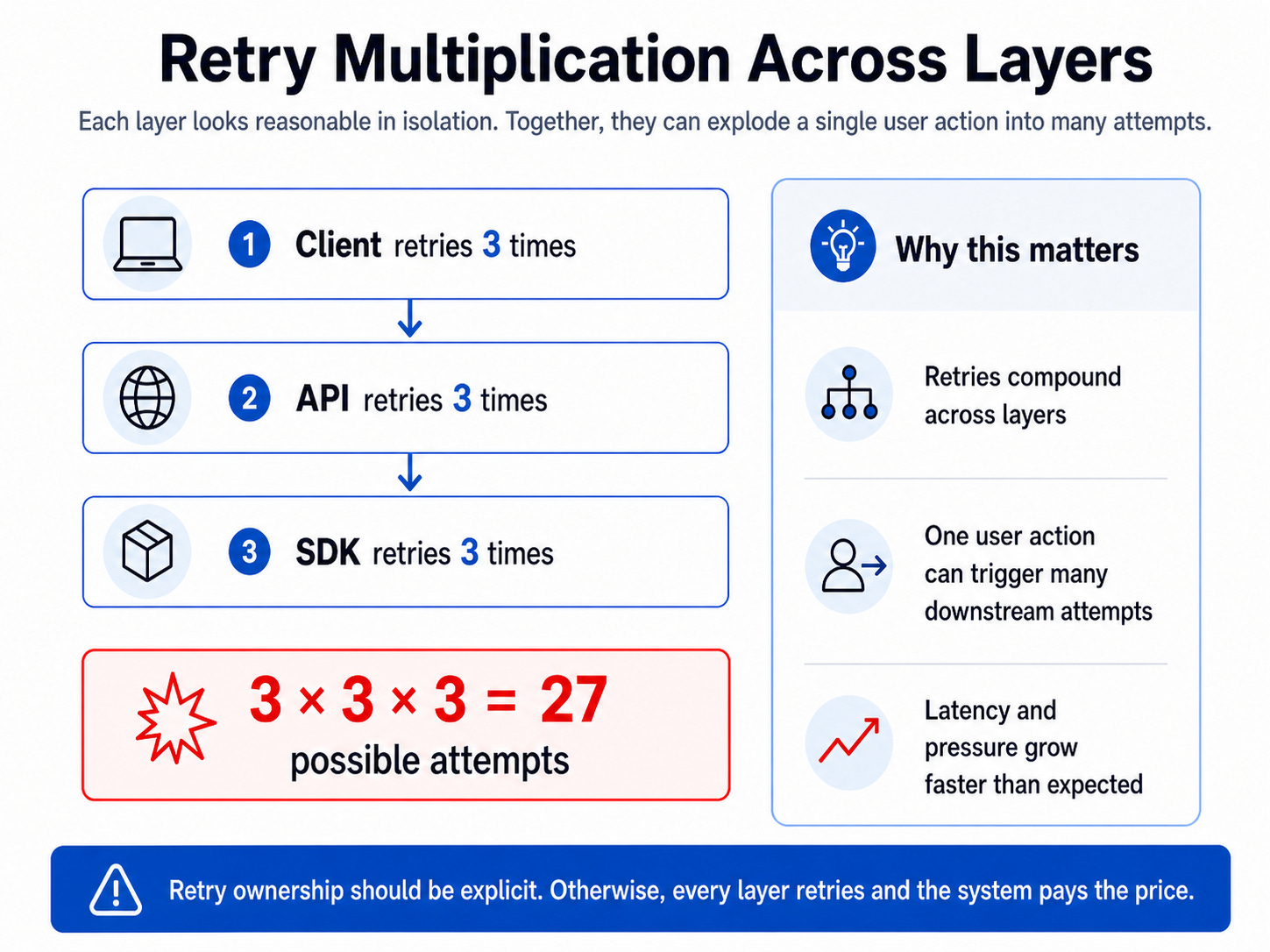
This is one of the most common retry mistakes.
A team says, “We only retry three times,” but the system quietly retries at multiple layers. The user sees latency. The dependency sees traffic multiplication. The team sees confusing metrics because the true number of attempts hides behind abstractions.
A better approach is to define ownership.
Decide which layer owns retries for a specific dependency. In many cases, you want the lowest safe layer to handle simple transient errors, while the application layer owns business-aware decisions such as idempotency, fallback, and user messaging.
Retry budgets force your system to make failure explicit. They prevent one request from consuming unlimited time and capacity.
But before you retry anything, especially writes, you need to answer the most important question:
Can this operation safely run more than once?
Retrying reads is easy. Retrying writes is dangerous.
Retries feel harmless when you fetch data.
GET /products/123/availabilityIf this request fails, you can usually retry safely. The user may wait a little longer, but the retry probably will not change business state.
State changes are different.
POST /orders
POST /inventory/reservations
POST /shipments
POST /returnsIf you retry a state change, you may repeat the action.
That can create duplicate orders, duplicate reservations, incorrect stock counts, or warehouse tasks that disagree with your order state.
These bugs hurt because they often happen after a timeout, and the timeout hides the truth. The caller does not know whether the service failed before or after completing the operation.
Consider an inventory reservation request:
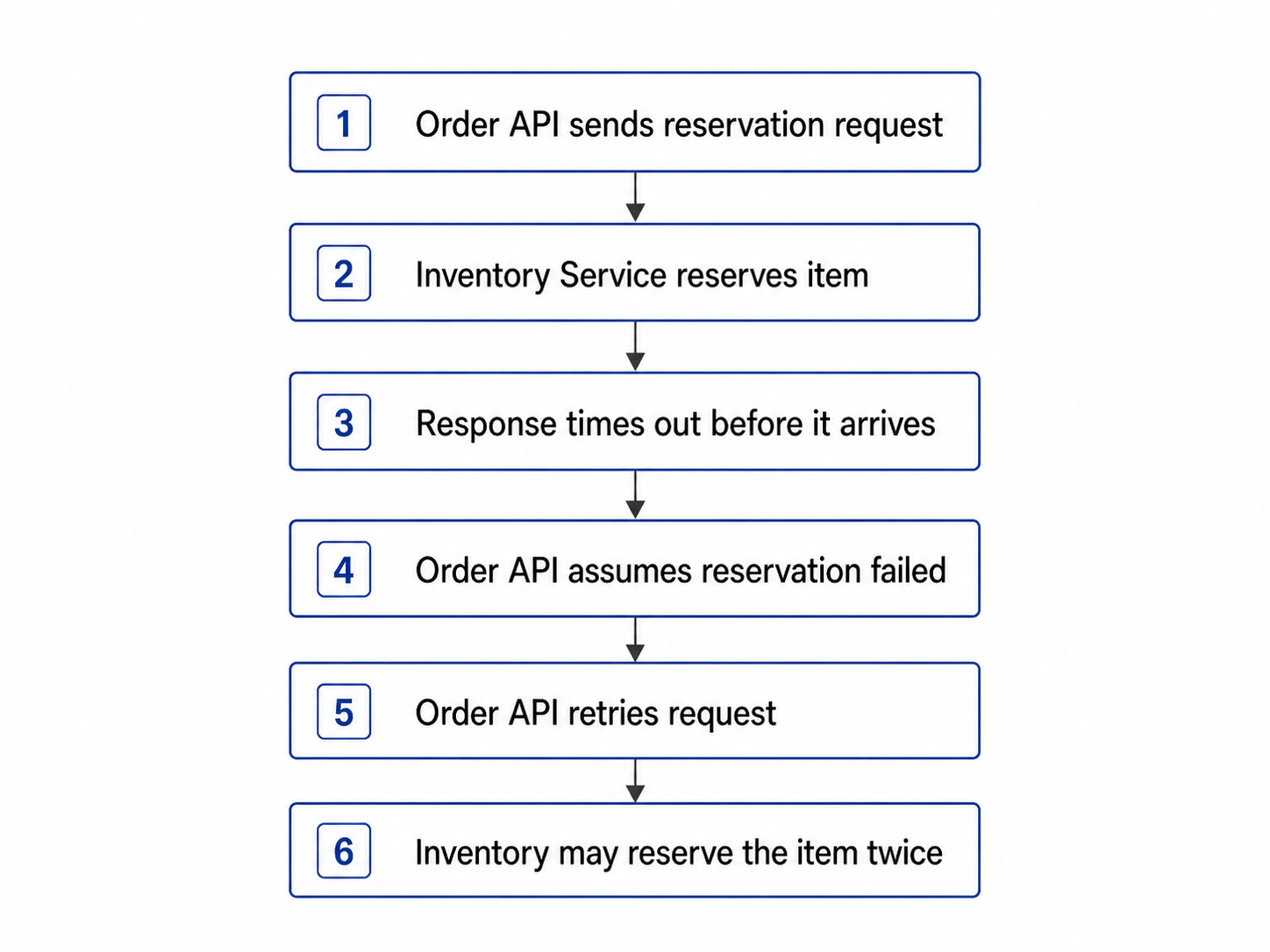
From the Order API’s point of view, the request failed. From the Inventory Service’s point of view, the reservation may have succeeded.
That uncertainty creates the real retry problem.
The solution is idempotency.
An idempotent operation can run multiple times and still produce the same final result. For inventory reservations, this usually means generating a stable reservation key for the specific order line.
POST /inventory/reservations
Idempotency-Key: order_123_line_1_reservationNow if the Order API retries with the same key, the Inventory Service does not create a second reservation for the same order line. It returns the original reservation result.
First request:
order_123_line_1_reservation -> reserve stock -> store result
Retry:
order_123_line_1_reservation -> result exists -> return same outcome
This changes the meaning of retries.
Without idempotency, a retry may duplicate state changes. With idempotency, a retry can safely recover from uncertainty.
For inventory systems, this matters because the user experience and the business state are tightly connected. The user sees “Order confirmed,” but the warehouse needs a real reservation behind that promise.
Idempotency also needs careful design. You need to decide how long to store reservation keys, what request fields belong to the idempotency record, how to handle two concurrent requests with the same key, and what to return if the same key arrives with a different payload.
A good idempotency implementation does not only store “this key exists.” It stores enough information to return the same outcome consistently.
For important state changes, this is not optional.
It is the difference between a retry strategy and a data integrity bug.
Once state changes are safe to retry, you still need to handle the case where the inventory service keeps failing for longer than expected.
That is where circuit breakers help.
Circuit breakers stop failure from spreading
Retries help with short-lived failure. Circuit breakers help with repeated failure.
The idea comes from electrical circuits. If too much current flows, the breaker opens to protect the system.
A software circuit breaker works the same way. If a dependency keeps failing, your application stops calling it for a while.
The state transition looks like this:
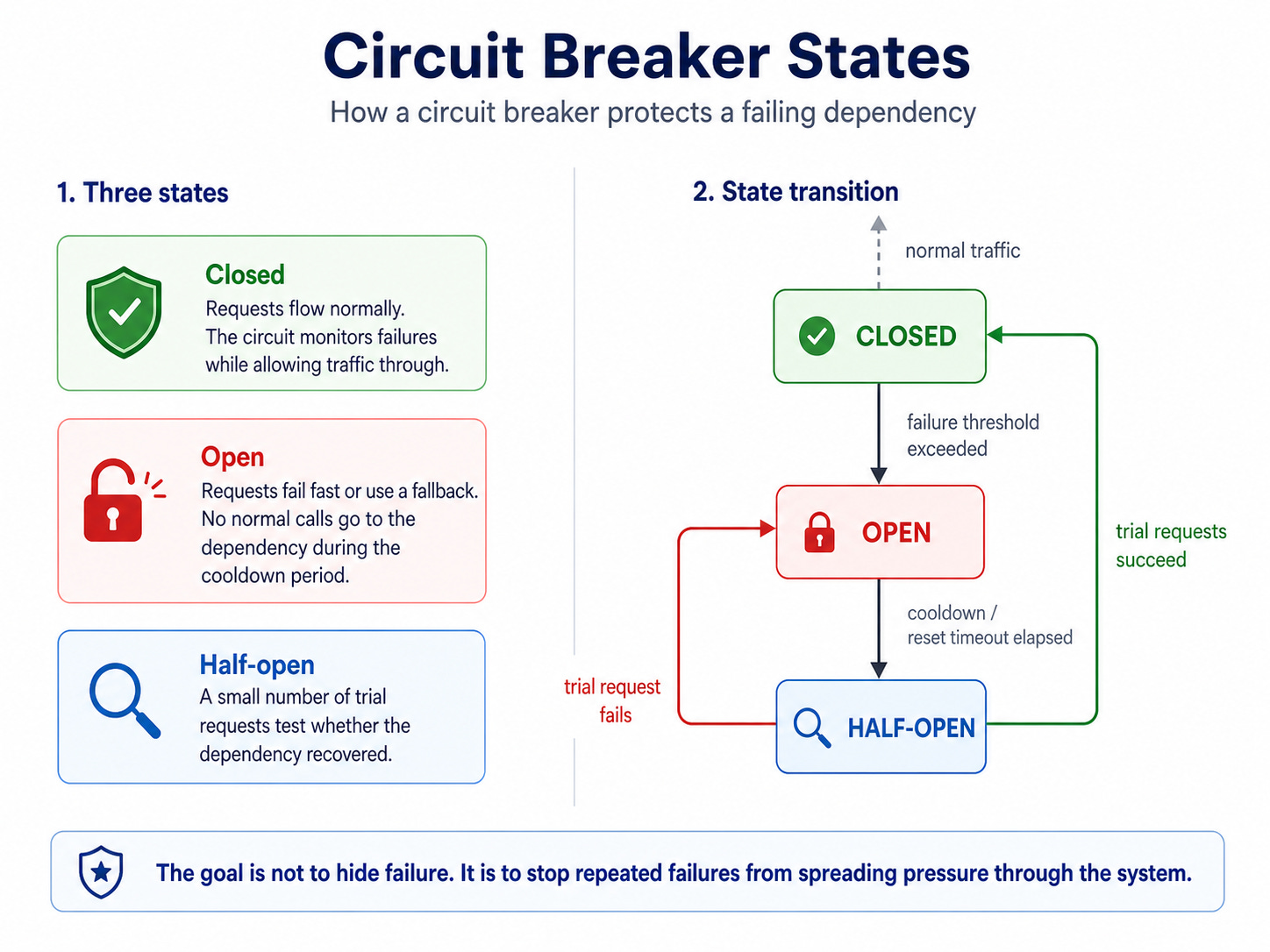
When the circuit is closed, the application calls the dependency normally. If failures cross a threshold, the circuit opens. While open, the application does not keep making calls that are likely to fail. It either fails fast or uses a fallback.
After a cooldown period, the circuit becomes half-open and allows a small number of test requests. If those succeed, the circuit closes. If they fail, it opens again.
This protects both sides.
Your application avoids wasting resources on doomed calls. The dependency gets breathing room to recover. Users get a faster response instead of waiting through repeated timeouts.
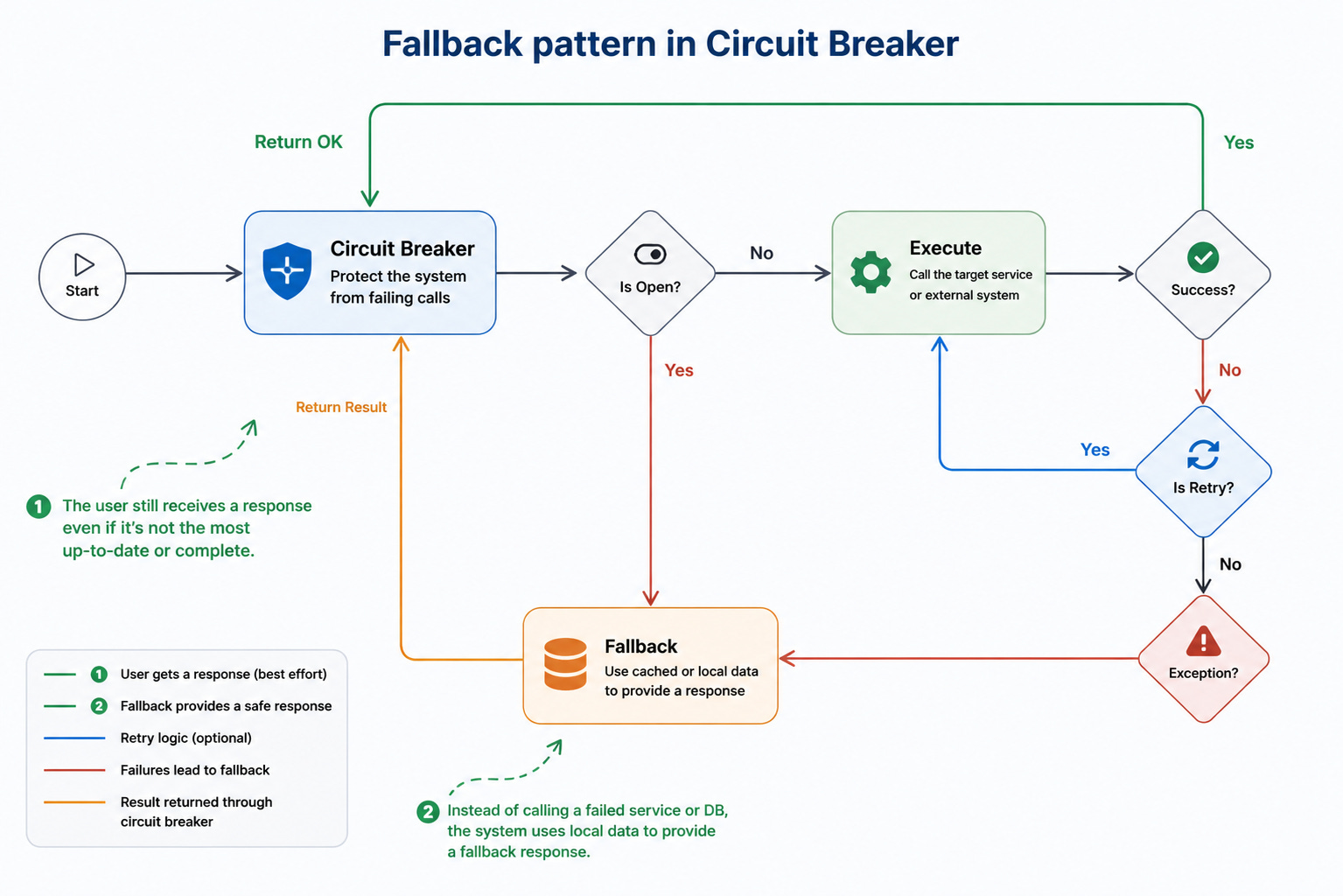
But a circuit breaker creates a new responsibility: what should happen when the circuit is open?
Sometimes the answer is a fallback.
Inventory service is slow
→ show “limited availability” instead of exact stock
Reservation fails temporarily
→ keep order in “pending inventory confirmation”
Warehouse integration is down
→ queue fulfillment task for later
Product availability read fails
→ show cached availability only if freshness rules allow it
Fallbacks can turn a hard failure into a degraded experience, but they are not automatically safe.
Showing cached product availability may be fine if the data is fresh enough. Showing “in stock” for an item that sold out can create a painful customer experience. Queueing a warehouse task may be fine. Confirming an order without a reliable reservation may create support tickets later.
Fallbacks are not about pretending everything works. They are about choosing the safest degraded behavior.
The better question is not:
“Can we fallback?”
The better question is:
“What happens if the fallback returns old, partial, delayed, or approximate data?”
That question moves reliability from infrastructure to product behavior.
Because once you introduce retries, circuit breakers, and fallbacks, the hard part stops being the pattern name and becomes the trade-off.
The hard part is choosing the right failure behavior
Reliability patterns are not free. Each one moves complexity somewhere.
Retries improve success rates but increase load and latency. Backoff protects dependencies but makes users wait longer. Circuit breakers protect systems but may reject requests that would have succeeded. Fallbacks improve user experience but may serve stale or incomplete data. Idempotency prevents duplication but adds storage, key design, expiration rules, and concurrency handling.
That means you should not copy one retry policy across every part of the system.
An inventory reservation, product availability read, warehouse fulfillment task, order confirmation, and analytics sync should not share the same retry behavior. They have different correctness needs, different latency expectations, and different business impact.
A product availability read can sometimes retry briefly or show cached data with freshness rules.
An inventory reservation needs idempotency, auditability, and clear ownership.
A warehouse fulfillment task can retry longer, back off between attempts, and use a dead-letter queue after exhaustion.
An order confirmation should fail clearly or keep the order in a pending state until inventory gets confirmed.
A useful mental model is to classify the operation by correctness risk and user urgency.
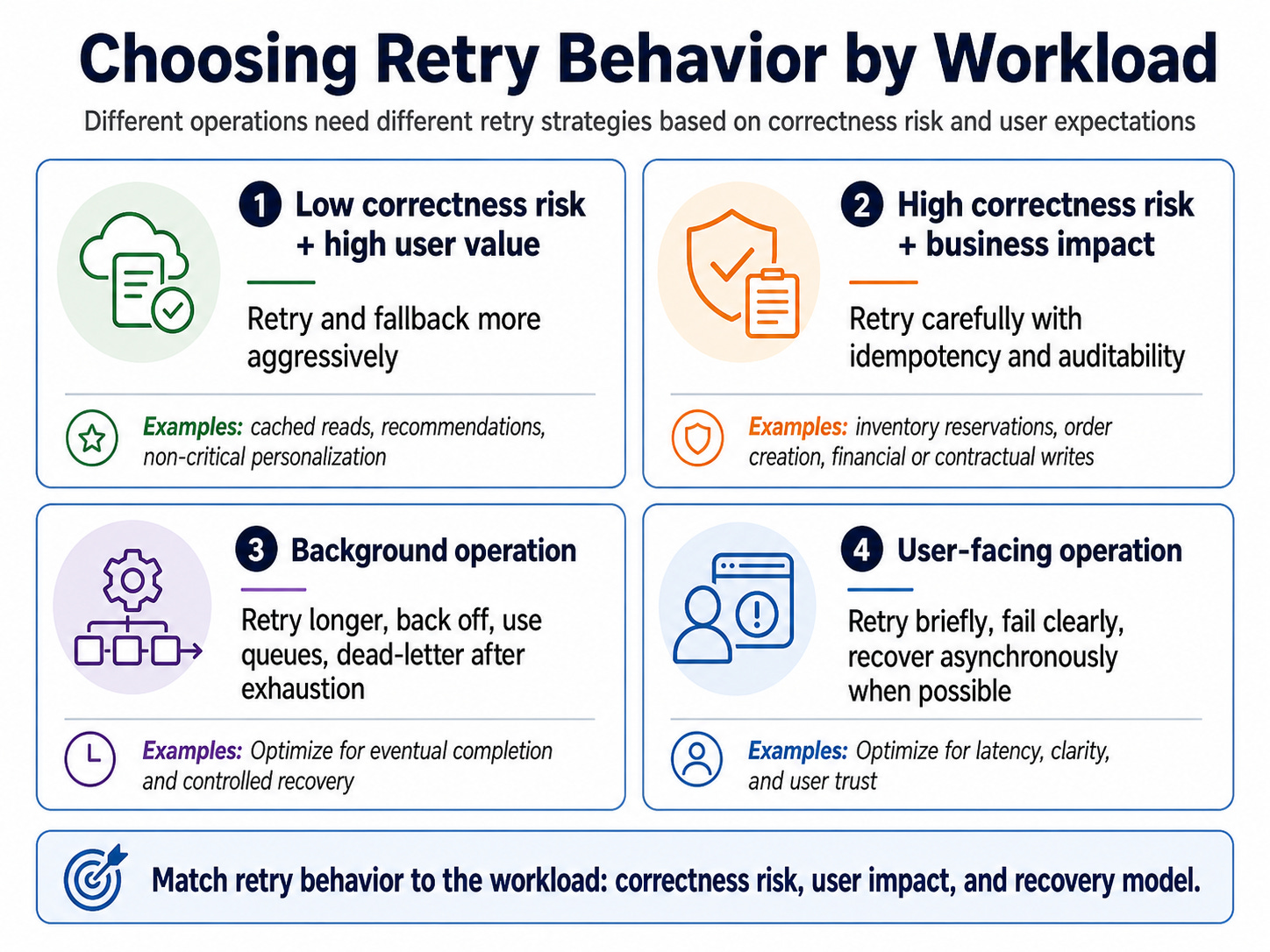
This is why transient fault handling belongs in system design.
It is not just a library configuration. It shapes latency, correctness, user trust, operational load, and blast radius.
The patterns are easy to name.
The engineering judgment comes from choosing the right behavior for the specific failure.
A simple checklist helps make those choices explicit.
A practical checklist before adding retries
Retry logic should not start with code.
It should start with a decision.
Before adding retries, slow down and answer a few questions: is the failure actually transient, is the operation safe to repeat, which layer owns the retry, what policy controls it, what happens when retries fail, and how will you observe the behavior in production?
That sounds simple, but these questions prevent many common retry mistakes.
They stop teams from retrying validation errors. They expose unsafe state changes before duplicate reservations, incorrect stock counts, or duplicate warehouse tasks happen. They prevent retry multiplication across the client, API, SDK, and worker layers. They force a time budget before latency quietly grows. They also make the failure path explicit before users discover it for you.
This is the mental model I use:
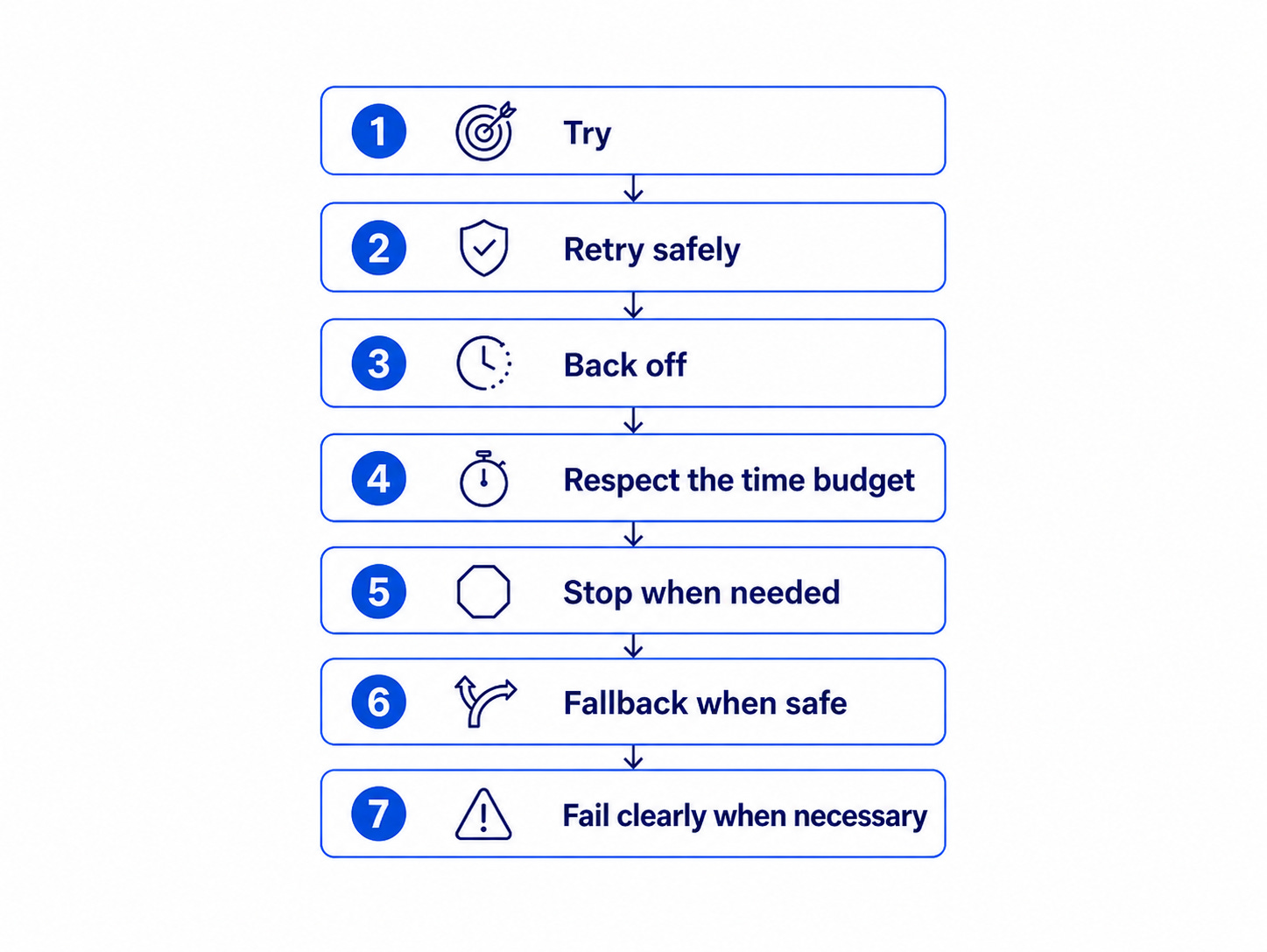
Retry Decision Checklist
1. Is the failure actually transient?
2. Is the operation safe to retry?
3. Who owns the retry?
4. What is the retry policy?
5. What happens if retries fail?
6. Can you observe it in production?
The checklist matters because retry behavior can hide inside abstractions. Your HTTP client may retry. Your SDK may retry. Your worker may retry. Your database driver may retry. Each layer may look reasonable alone, but together they can turn one failed request into many downstream attempts.
That is why retries need ownership, limits, and visibility.
A retry policy should define max attempts, per-attempt timeout, total time budget, exponential backoff, and jitter. For important state changes, it should also define the idempotency strategy before the first retry happens.
And when retries fail, the system needs a clear next step. Fail fast. Use a fallback. Open a circuit breaker. Send the message to a dead-letter queue. Show a clear user-facing error. But do not leave the system guessing.
Useful metrics include:
retry_attempts_total
retry_exhausted_total
dependency_timeout_total
circuit_breaker_open_total
fallback_used_total
idempotency_key_reused_total
dead_letter_messages_total
These metrics tell you whether retries are helping the system recover or quietly becoming the normal path. That distinction matters because a system can look healthy while retry behavior gets worse. Your success rate may stay high because requests eventually succeed, but latency, dependency pressure, and user frustration may keep increasing.
Here is the printable version of that decision process:

Use it before adding retry logic to a service, SDK wrapper, worker, or API integration.
Because the most dangerous retry policy is the one nobody designed.
And when retry behavior is designed intentionally, the system moves closer to graceful degradation.
The real goal is graceful degradation
Transient faults are part of cloud life.
You cannot prevent every timeout, network blip, overloaded dependency, rate limit, deployment restart, or temporary gateway failure.
But you can control how your system reacts.
A weak system treats every failure as a surprise. A stronger system expects temporary failures and contains them.
The goal is not to make every request succeed no matter what. That mindset creates dangerous retry storms. The goal is to give each request a controlled path.
That is real reliability: not retrying forever, not hiding every problem behind a spinner, and not assuming every dependency will recover before the user notices.
A reliable system absorbs small failures without turning them into permanent user frustration.
Before we close, let’s summarize the core lessons.
Takeaways
Transient faults are normal in distributed systems. Treat them as expected behavior, not rare exceptions.
Retries can improve success rates, but blind retries can amplify failure and overload dependencies.
Use exponential backoff, jitter, timeouts, and retry budgets to control retry pressure.
Never retry important writes unless the operation is idempotent or safe to repeat.
Circuit breakers and fallbacks help prevent one unhealthy dependency from damaging the whole user experience.
Closing thought
Here is the mental model I keep coming back to:
A retry is not a second chance. It is extra pressure on a system that may already be struggling. Use it like medicine, not like a reflex.
That is the difference between a system that recovers and a system that spirals.
Retries help. Backoff helps. Jitter helps. Circuit breakers help. Fallbacks help. Idempotency protects correctness.
But the real skill is not knowing the names of the patterns.
The real skill is knowing when each pattern should apply, how much pressure your system can tolerate, and when the safest response is to stop trying.
Because the user does not care that the failure was transient.
They care whether your system handled it with confidence.
A good backend system does not pretend failures will never happen. It decides ahead of time how failure should behave.
Bad retries can break good systems.
Good retry design protects them.
Until next time,
— Raul
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a paid subscriber.
Good Read!!
Did you try Stakpak? its open source and vendor neutral
It monitors your infrastructure 24/7, auto resolve infra issues when its safe and only escalates to you when it actually matters
http://www.stakpak.dev