
Async systems scale your system… and your problems.
Many developers only realize it after consistency breaks.

The failure no one expects
An IoT system publishes two events from the same device into a queue:
“door open”
“lock door”
They land on a shared topic and get picked up by different consumers running in parallel.
Each event is valid. Each handler executes successfully. Each service does exactly what it was designed to do.
But because processing is async, they’re handled out of order:
Lock door → Door open
And so, the final state is wrong.
The door ends up open, even though a lock command was issued.
Nothing failed.
No alerts fired.
The system behaved exactly as designed.
Each component is locally correct, but no one owns the sequence over time. The result violates the expected invariant: “lock means locked.”
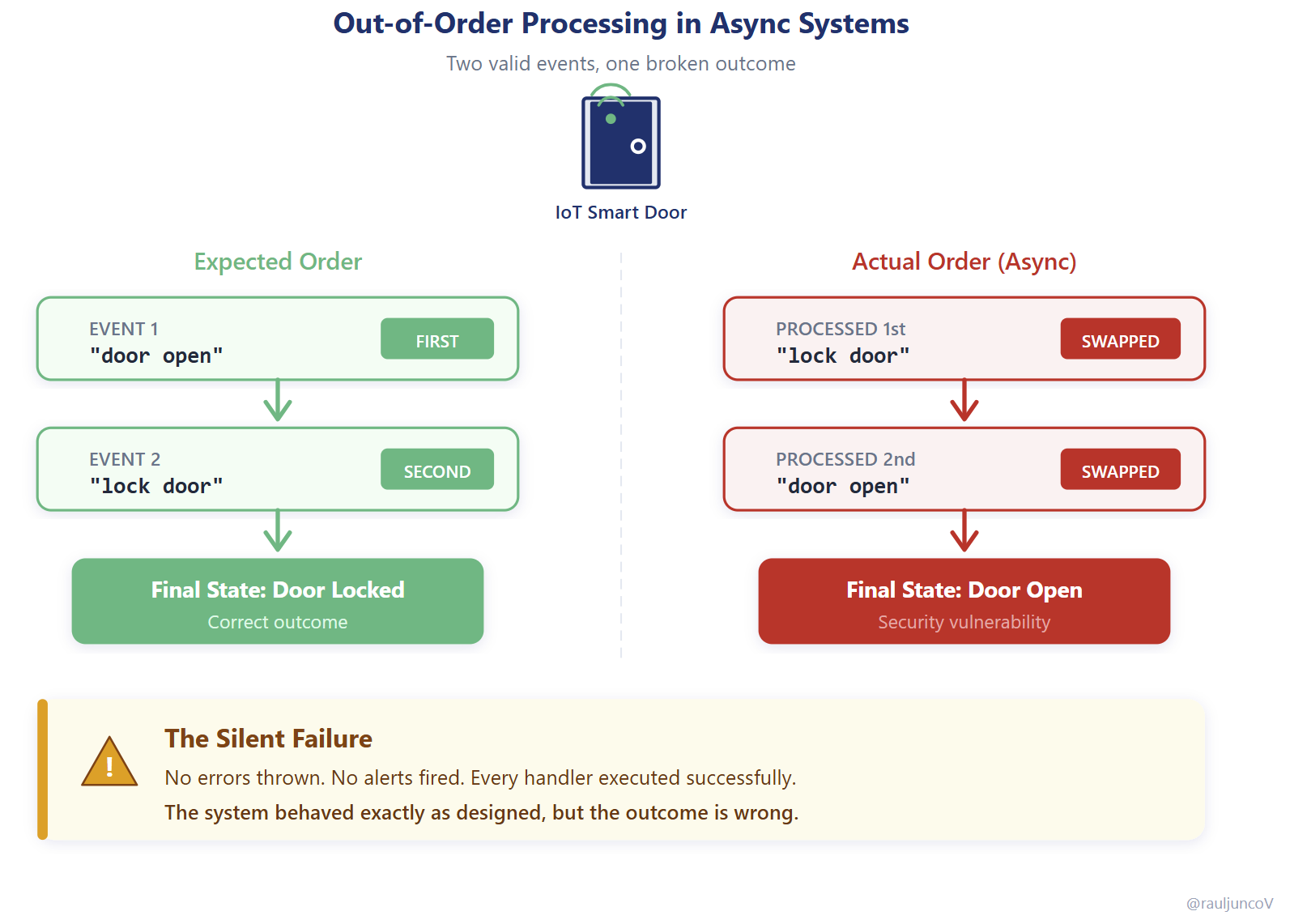
From the user’s perspective, the system is broken.
This is the real danger with async systems: failures that don’t look like failures. To understand why, you need to look at what async really changes.
AI coding gets practical when Agent B knows it must wait for Agent A.
Cline Kanban brings that workflow into one UI: you can run multiple agents, monitor progress at a glance, and define dependencies so work unlocks in the right order. It’s a cleaner way to manage parallel agent execution without losing track of what’s happening.

What async actually changes
Async systems unlock scale by removing blocking operations and allowing work to be processed in parallel. Services decouple, throughput increases, and systems can handle spikes without cascading failures.
That’s why queues, streams, and event-driven architectures are everywhere.
But there’s a fundamental trade-off:
You lose control over execution order.
You’re trading simpler consistency for availability and throughput. Order is no longer implicit; it must instead be designed.
Once ordering is not guaranteed, consistency becomes timing-dependent. State updates can arrive in different sequences, retries can reorder operations, and parallel consumers can apply conflicting changes.
The system still “works,” but the result depends on when things happen, not just what happens.
This isn’t a tooling issue. It’s a direct consequence of async processing. And it starts with how messages flow through your system.
Why this happens
At a high level, async pipelines look simple: producers send messages to a queue, and consumers process them.
In reality, several factors break ordering.
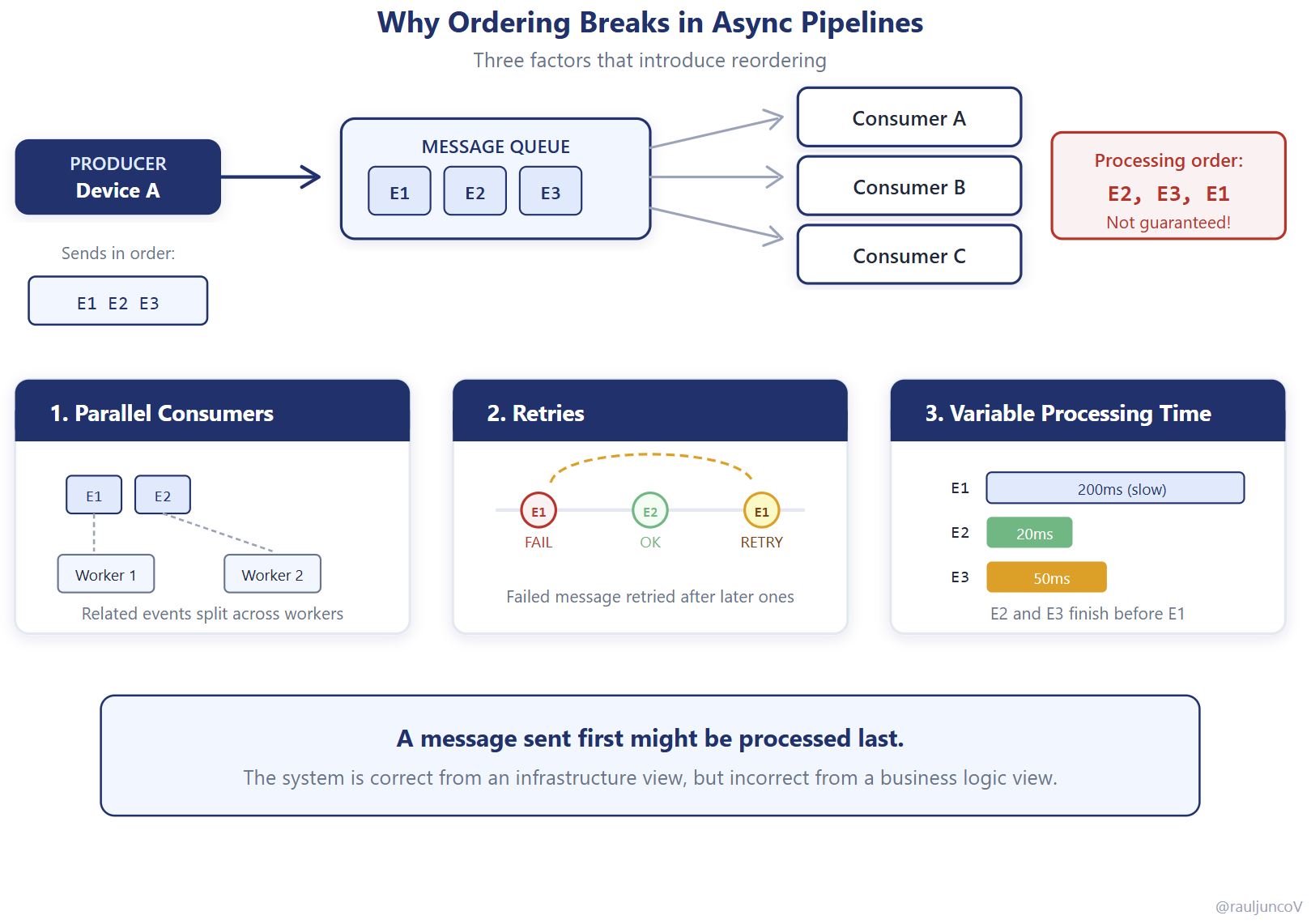
Consumers run in parallel, so related messages may be processed at the same time. Retries can push older messages ahead of newer ones. Network delays vary, so delivery order isn’t guaranteed. Batch processing changes execution timing.
All of these introduce reordering.
A message sent first might be processed last. Two related events might be handled by different consumers simultaneously.
The system is behaving correctly from an infrastructure perspective, but incorrectly from a business perspective, because no component owns the invariant over time.
It’s like multiple operators controlling the same device without coordination.
So the question becomes: where do you reintroduce order?
The simplest fix most teams miss
You don’t need ordering across the entire system. That would destroy scalability.
You need ordering where state matters.
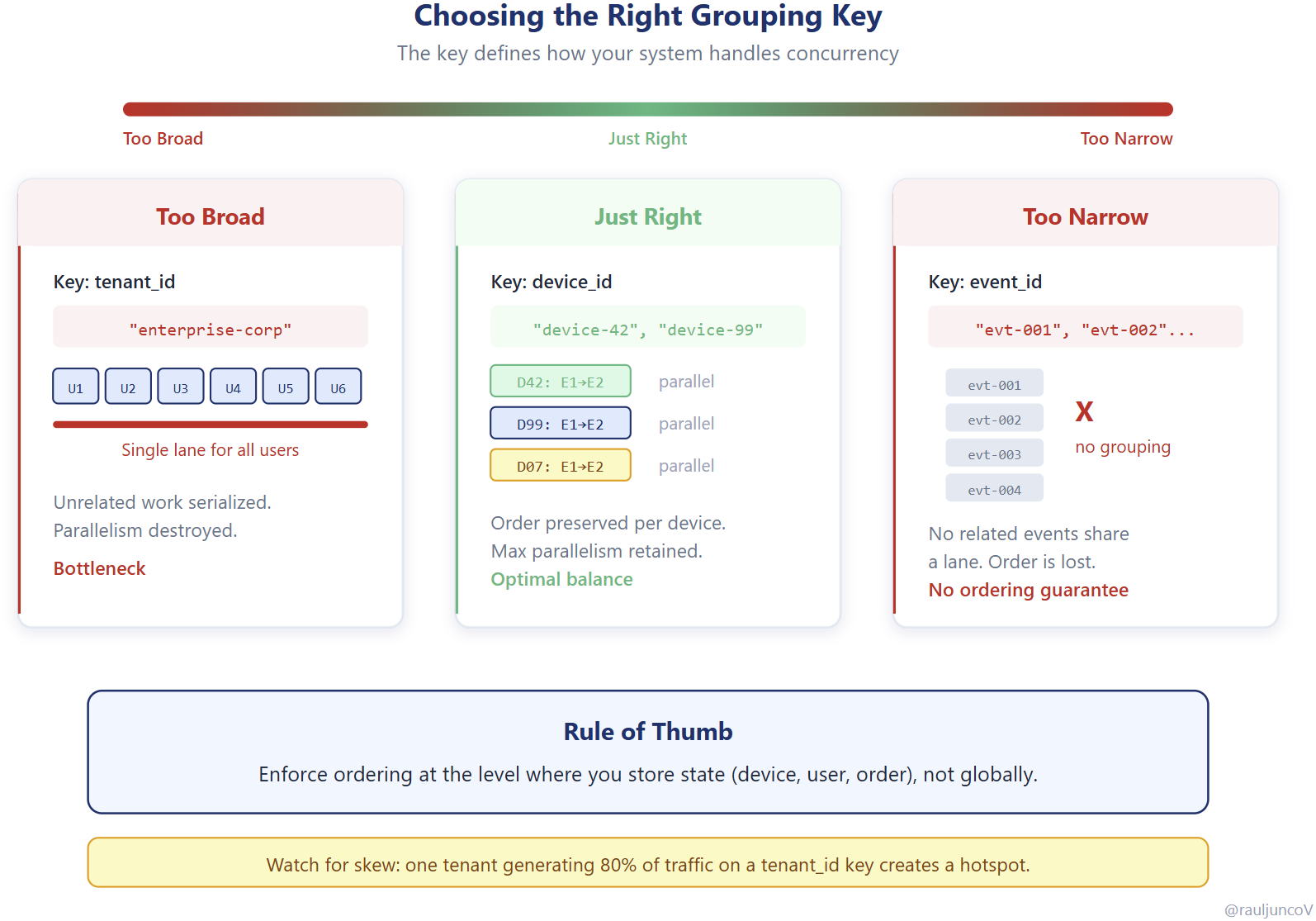
Rule of thumb: enforce ordering at the level where you store state (device, user, order), not globally.
This is where grouping comes in.
By grouping related messages and processing them sequentially within that group, you preserve the correct order for a specific entity while still allowing parallelism across unrelated entities.
In practice, this means assigning all events for a device, user, or order to the same processing lane. For Kafka, this is the partition key; for SQS FIFO, this is the message group ID; for Service Bus, this is the session ID.
Within that lane, events are handled in sequence. Across lanes, the system remains fully parallel.
You’re not eliminating concurrency; you’re shaping it.
This pattern is everywhere
Modern messaging systems implement this concept in different ways, but the underlying idea is the same.
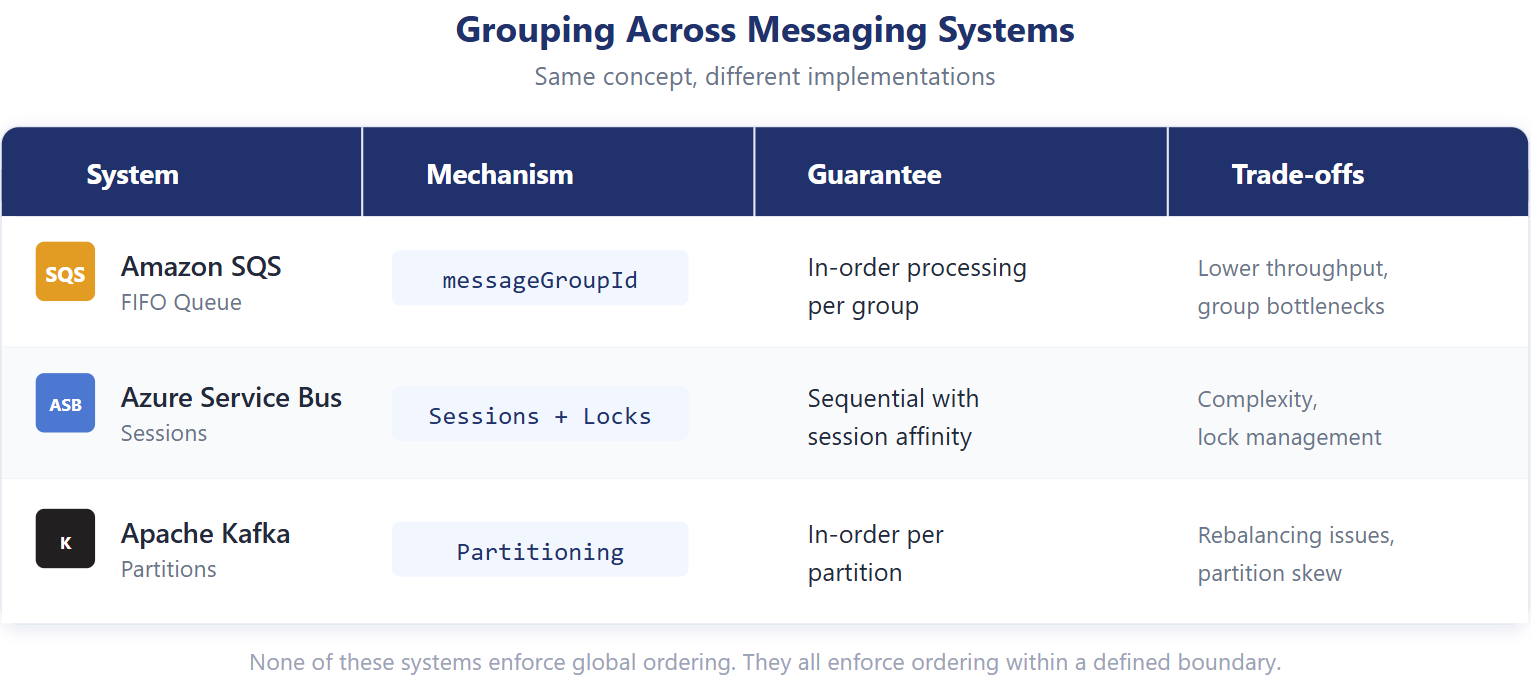
SQS FIFO uses message groups to enforce ordered processing. Azure Service Bus uses sessions to ensure sequential handling. Kafka uses partition keys to guarantee order within a partition.
None of these systems attempt to enforce global ordering. They all enforce ordering within a defined boundary.
That boundary is what makes scale possible.
Global ordering would force all messages through a single pipeline, creating a bottleneck. Local ordering allows independent groups to progress without blocking each other.
Which brings you to the most important design decision.
The real decision isn’t grouping
It’s the grouping key.
The grouping key determines how messages are partitioned and how ordering is enforced. A good key aligns with real-world entities (like a device, user, or order) so that related events are processed in sequence.
A poor key introduces problems.
If the key is too broad, unrelated work is forced into the same group, reducing parallelism. If it’s too granular or random, related events may not stay together, breaking ordering guarantees.
And if the key is skewed, you create hotspots. For example, using a “tenant id” as the key when one tenant owns millions of devices collapses parallelism into a single hot group.
You’re not just deciding how to route messages.
You’re defining how your system handles concurrency.
Where things break again
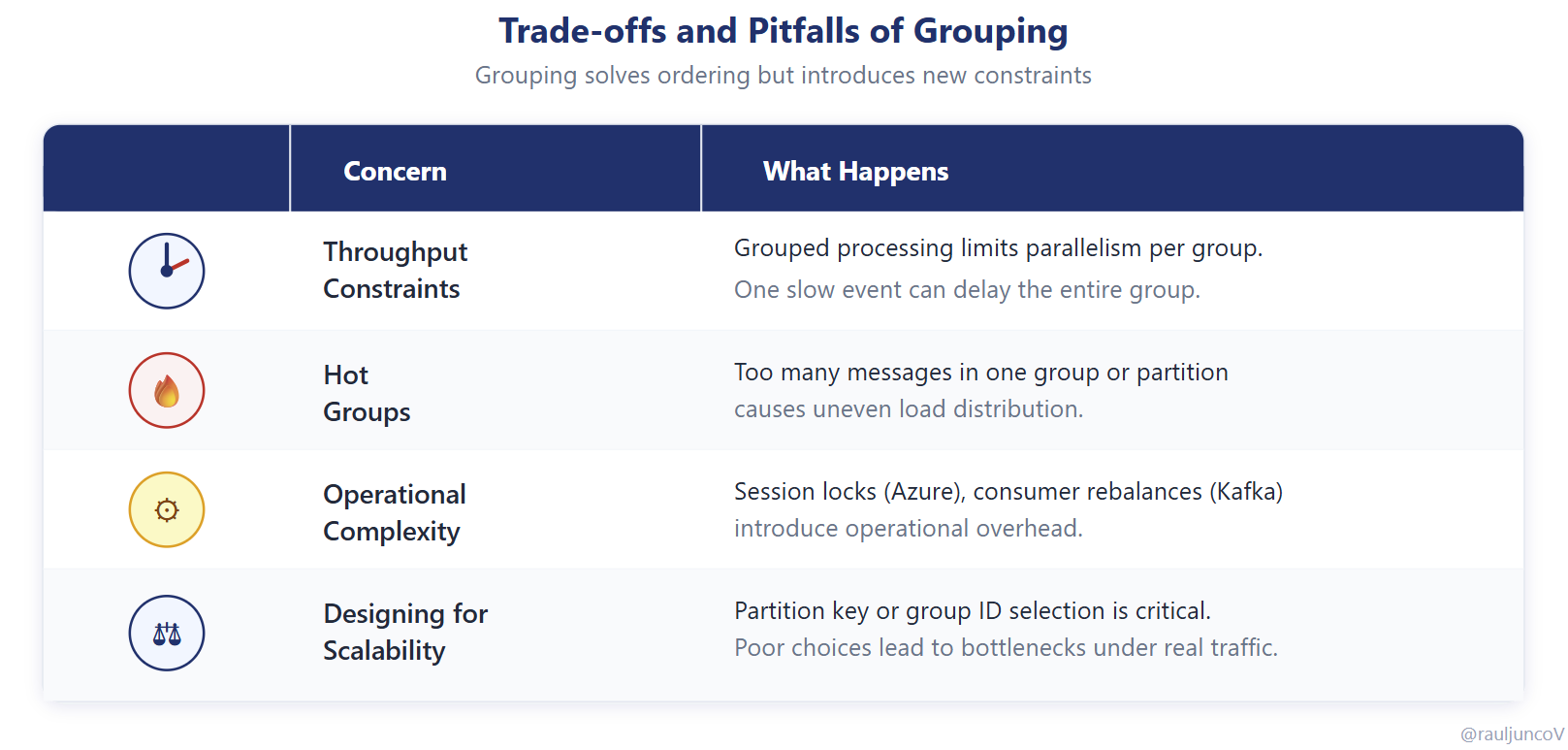
Grouping solves ordering, but it introduces new constraints.
Within a group, processing is sequential. A single slow message can delay everything behind it.
Under uneven traffic, some groups receive far more events than others. A single high-traffic entity can dominate a partition, turning it into a bottleneck while others remain underutilized.
This is the hot partition problem.
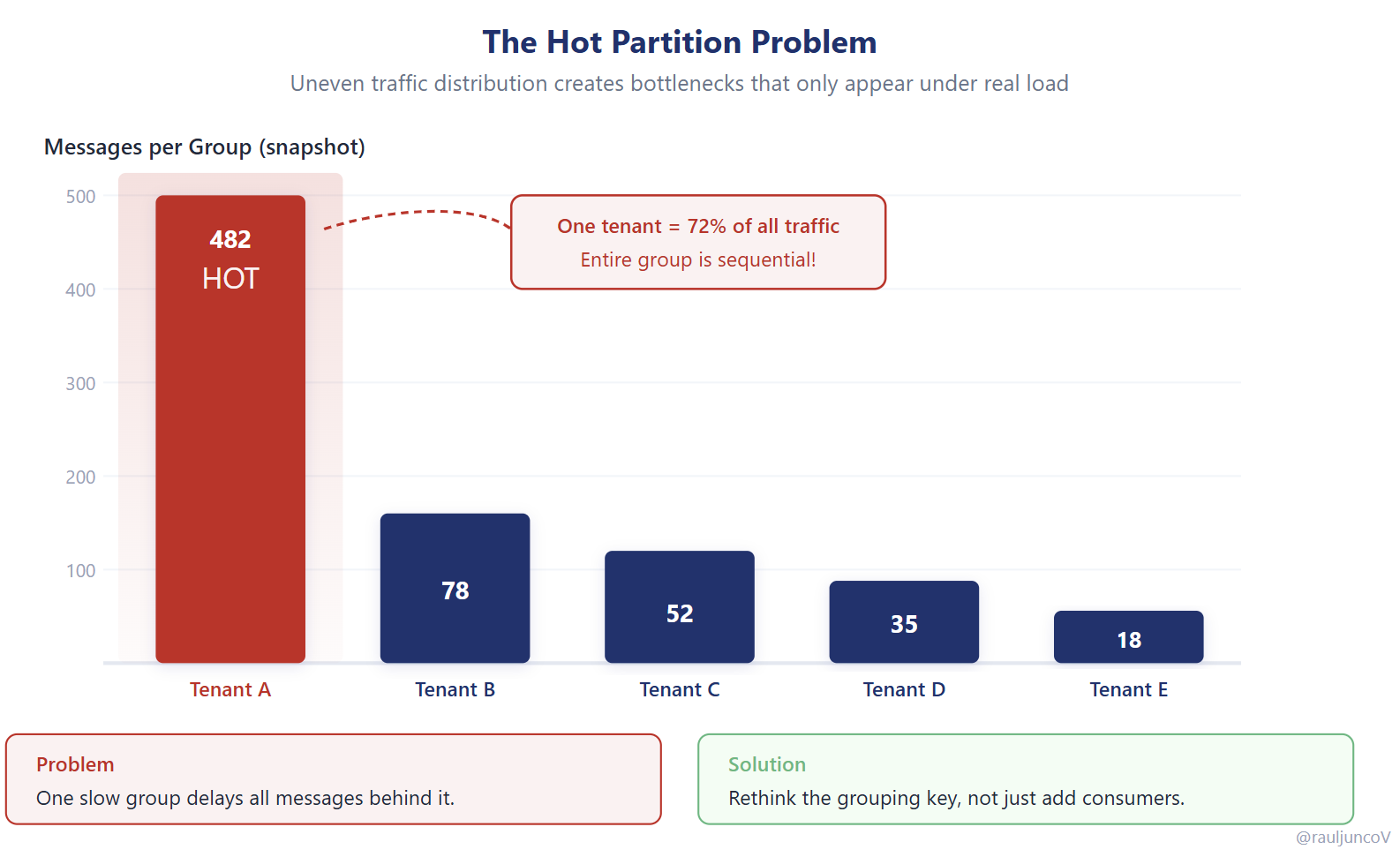
It rarely shows up in development environments. It appears under real traffic, when distribution is uneven and unpredictable.
At that point, scaling requires rethinking your grouping strategy, not just adding more consumers.
What grouping actually buys you
Grouping doesn’t eliminate concurrency issues. It scopes them.
Instead of system-wide inconsistency, you limit coordination to smaller, well-defined boundaries. This makes behavior more predictable and easier to reason about.
You still have concurrency, but it’s controlled. You still have trade-offs, but they’re explicit.
That’s what makes async systems workable in practice.
My take
Most teams adopt async for scale and treat ordering as an afterthought. They assume inconsistencies will be rare or manageable.
In reality, those inconsistencies surface under load, when they’re hardest to debug and fix.
A better approach is to design for ordering from the start. Define how your system handles sequence and state transitions before introducing parallelism.
If you don’t design for order, async will decide it for you.
Until next time,
— Raul
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a paid subscriber.
The actor model always gets discovered.