
A Good System Design Tackles Down the Hot Path First
Before you add cache, replicas, queues, or microservices, understand where the system actually feels pressure.

The first sign is usually not dramatic.
No outage. No database on fire. No angry incident channel.
Just a few small signals.
Product pages start loading slower during peak hours. Search feels a little heavier than usual. The database dashboard shows CPU climbing. A few users complain that the site feels slow. Someone from product asks if the last release caused a regression.
Then the Slack thread starts.
“We should add Redis.”
“Maybe we need read replicas.”
“This is why we need to split the catalog service.”
“Should we move search out of the database?”
All of those ideas might be valid.
But none of them should be the first question.
The first question should be:
Where is the system actually hot?
That is where many scaling mistakes begin. Teams jump to infrastructure before they understand the shape of traffic. They scale the database when only one query path hurts. They add cache before they know what data gets reused. They split services before they understand which part of the system needs independent scaling.
They treat the system like one big machine.
But production rarely works that way.
Production has hot paths.
And good system design starts by finding them.
The agent harness wasn’t supposed to be the black box

Agent loop is the most important piece of infrastructure in your workflow right now and for most developers, it’s the one piece they can’t open up. Agent builders have to jump through all the hoops themselves, crafting the infrastructure and tools, testing the harness, while fighting to maintain what they’ve built.
Meet Cline SDK: agent harness behind Cline 2.0, fully open-sourced. The same runtime that powers Cline across VS Code, JetBrains, and the CLI is now an npm install away: npm i @cline/sdk. Inspect it, fork it, extend it, ship on it.
Best-in-class harness: 74.2% on Terminal-Bench 2.0 with Claude Opus 4.7 ahead of Claude Code (69.4%) and strongest numbers published on open-weight models.
Open model & provider choice: Anthropic, OpenAI, Google, Bedrock, Mistral, or any OpenAI-compatible endpoint.
Real plugin system: Register tools, hooks, commands, providers, message builders. Prototype as a local file, harden into a package. Extend it freely for any of your agent use cases.
Scheduled + event-driven agents: Cron and event specs for PR reviews, dependency checks, coverage audits, changelogs no separate orchestration layer.
Stop building around your agent. Start building on it.
Install Cline SDK today: npm i @cline/sdk Or try the rebuilt harness directly: npm i -g @cline
The system is not equally busy everywhere
Most applications have uneven traffic.
This sounds obvious, but under pressure, teams will still talk about “the API,” “the database,” or “the service” as if every part receives the same load.
Unfortunately,they don’t.
Let’s take an e-commerce system.
Here,most users are not updating products. They are browsing. They search for products, open category pages, check product details, look at recommendations, compare prices, and refresh availability.
Those actions will happen all day.
The write side looks different. A smaller group of internal users creates products, updates descriptions, changes prices, adjusts inventory, or modifies catalog metadata.
Those writes matter. But they usually happen far less often than reads.
So the traffic shape might look like this:
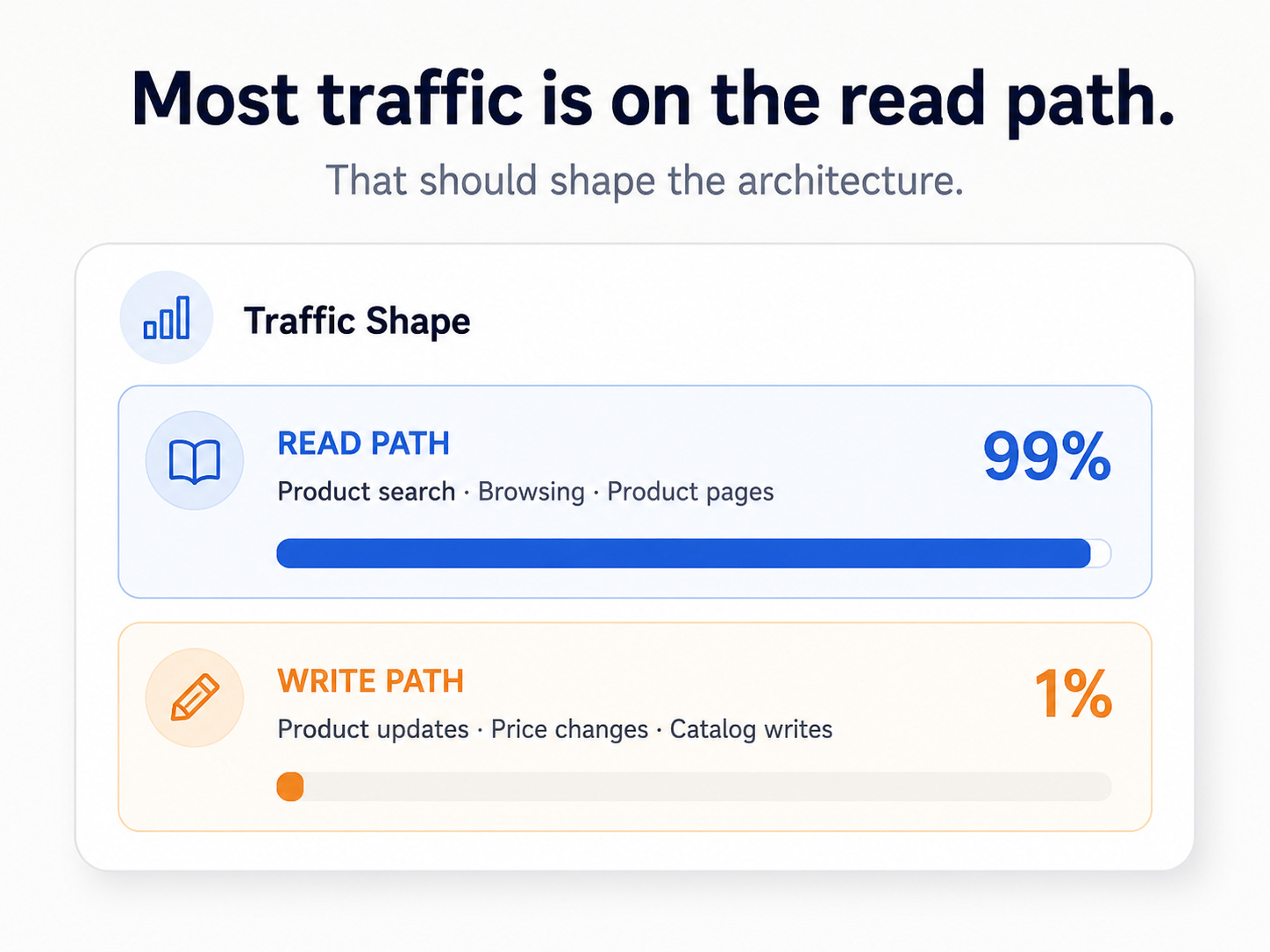
This split changes everything, because if you scale both paths the same way, you miss the point.
Reads and writes do not have the same job.
Reads need speed.
Writes want correctness.
A product page needs to load fast. A price update needs to commit safely. A search result can usually tolerate a small delay. An inventory update may not.
Once you see the difference, the architecture starts to make more sense.
The next step is identifying which part of the system deserves complexity.
The hot path tells you where to spend complexity
The hot path is the part of the system that gets used the most, carries the most business value, or causes the most damage when it slows down.
For an e-commerce app, the hot path is probably not this:
PUT /products/{id}
PATCH /products/{id}/description
POST /productsThose endpoints are important, but they are usually not where most traffic lives.
The hot path is more likely this:
GET /search/products
GET /products/{id}
GET /categories/{id}/products
GET /recommendationsThose endpoints sit directly in the customer experience.
If search slows down, users browse less.
If product pages slow down, conversion drops.
And if recommendations fail, the system may still work, but revenue takes a hit.
This is where system design becomes more than drawing boxes. You have to ask what the user touches most and what the business cannot afford to make slow.
The write path has a different risk.
A failed product update might annoy an admin. A bad product update can corrupt trust. You do not want a price half-updated. You do not want inventory racing between two systems. You do not want the product page and checkout showing different truths.
So the design tension becomes clear:
The read side must absorb volume.
The write side needs to protect truth.
A good architecture does not pretend those are the same problem.
It separates them.
A simple read/write split does not require microservices
Imagine the team looks at production data and sees the pattern clearly.
Product browsing creates most of the traffic. Product updates create a tiny percentage of requests. Search and product pages hit the database repeatedly for the same data.
At that point, the design does not need to start with microservices.
It can start inside the same application with a simple read/write split:
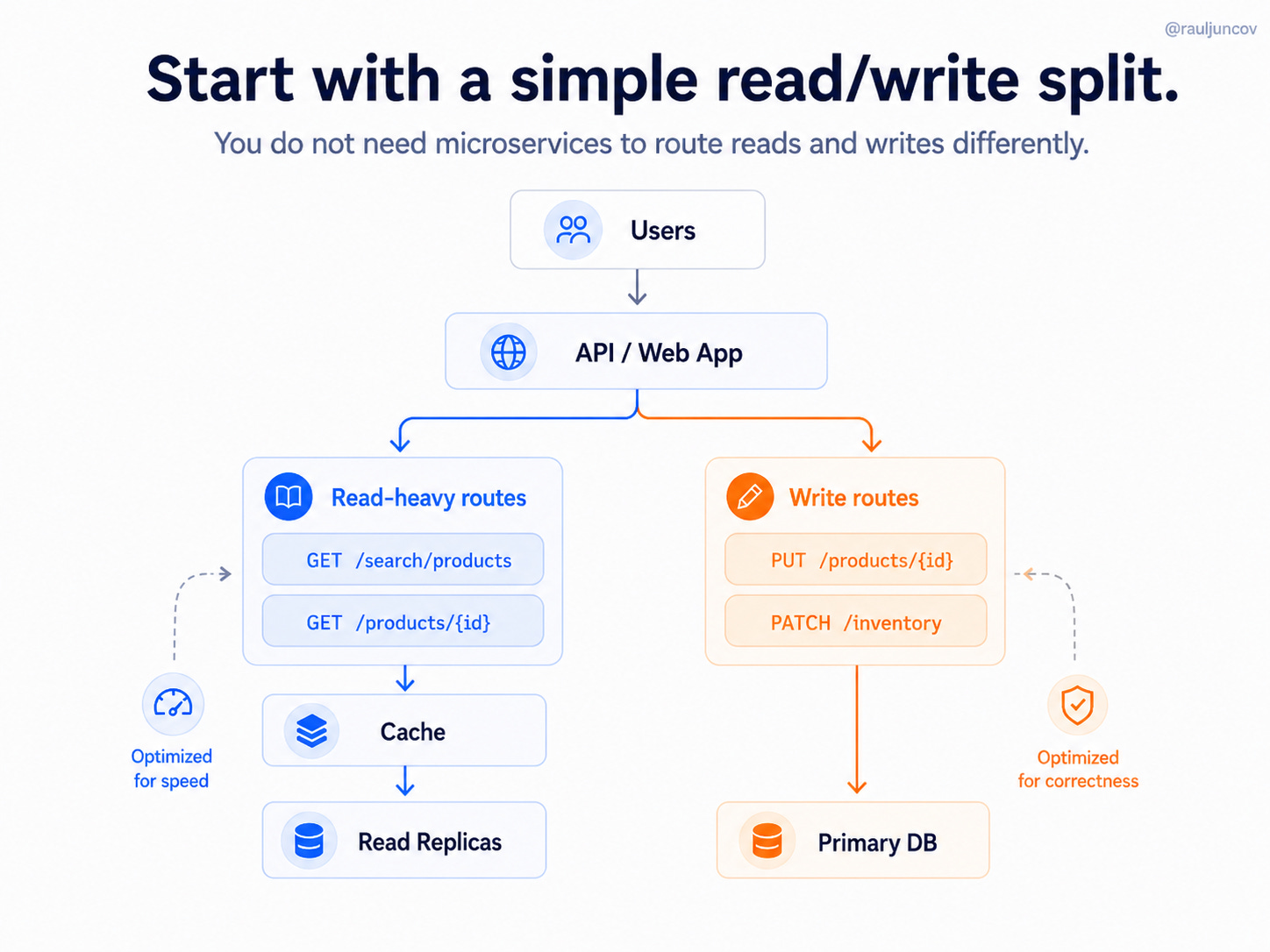
The important part is not splitting the application into multiple services.
The important part is to split the access pattern.
Same backend.
Different paths.
Different scaling strategy.
Read-heavy endpoints can go through cache and read replicas. Write endpoints can go directly to the primary database, where correctness matters most.
This is the difference between adding tools and designing a system.
A tool-first team says, “Let’s add Redis.”
A design-first team says, “This endpoint gets hammered with repeated reads, and the data can tolerate short-lived staleness, so cache makes sense here.”
Same tool.
Very different reasoning.
And if the app itself becomes a bottleneck, then you can add multiple instances behind a load balancer:
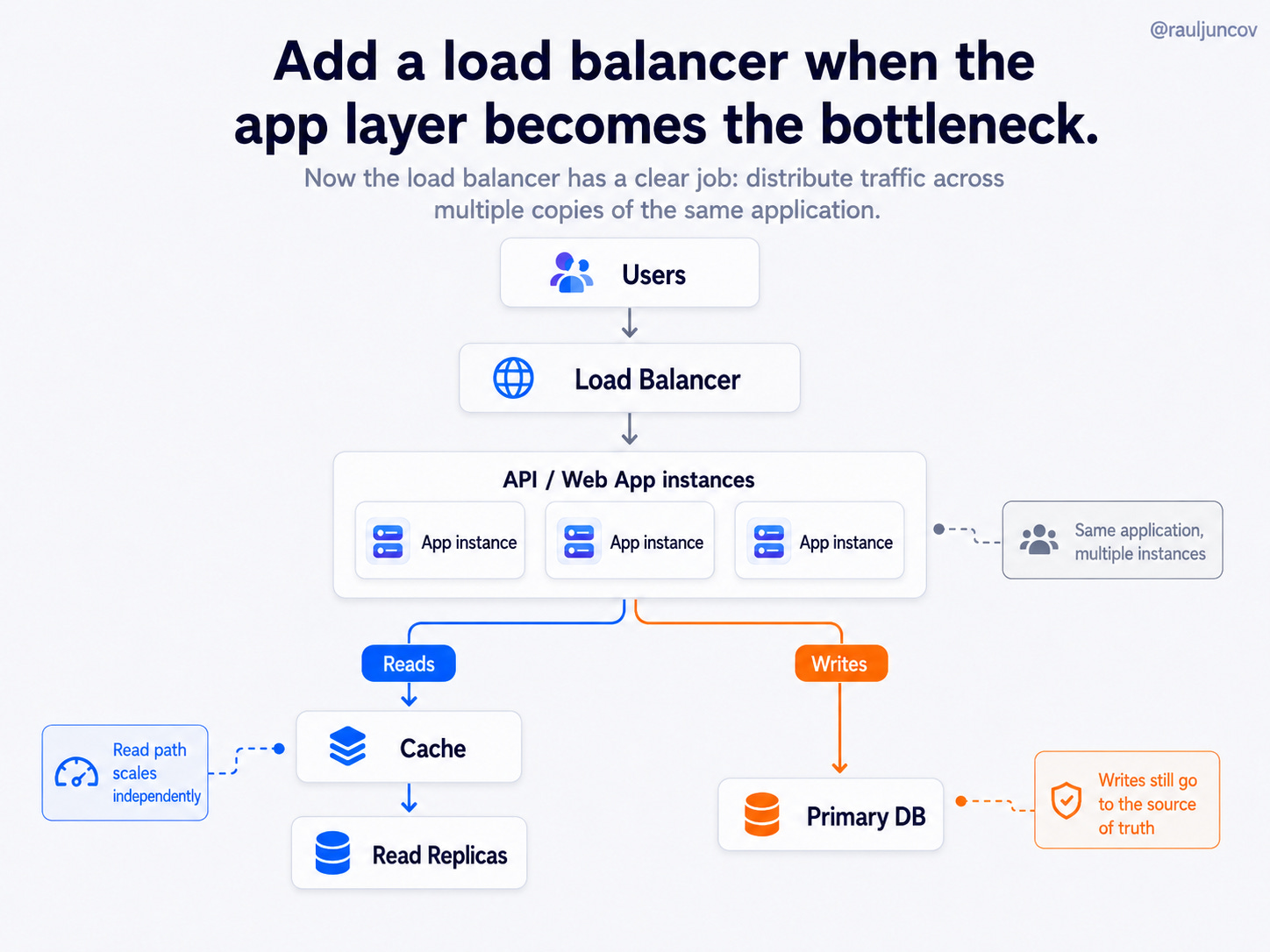
Now the load balancer has a clear job: distribute traffic across multiple copies of the same application.
It does not mean you have microservices.
It means you have more than one app instance handling requests.
That distinction matters because many teams jump from “we need to scale this path” to “we need to split the system.” Most of the time, you can improve the design without increasing deployment complexity.
But this design still introduces trade-offs, and those trade-offs matter in production.
Replicas make reads faster, but not always fresher
Read replicas help because they move read pressure away from the primary database.
That is useful when product browsing generates far more traffic than product updates. The primary database can focus on writes while replicas handle repeated reads.
But replicas come with a cost: replication lag.
A user updates a product price and the write succeeds on the primary. For a short period of time, one or more replicas may still return the old price.
That might be fine for a product description.
It might not be fine for checkout.
This is where engineers need to stop thinking only in infrastructure terms and start thinking in business rules.
Some reads can tolerate eventual consistency:
Product description
Category page
Search results
Recommendation widgets
Recently viewed productsOther reads may require stronger consistency:
Checkout price
Available inventory
Payment status
Order confirmation
Account balanceA common mistake is routing all reads to replicas because “reads scale horizontally.”
That statement is directionally true, but incomplete.
Some reads can scale horizontally.
Some reads need the latest committed state.
A better rule is:
Use replicas for reads that can tolerate staleness.
Use a stronger consistency path for reads that must be fresh.
For example, after a user updates data, you can route their next few reads to the primary to guarantee read-your-writes. For critical flows like checkout, you can hard-route price and inventory reads to the primary or to a dedicated consistency path instead of replicas.
This one decision prevents a lot of subtle bugs.
The same problem shows up again when you add cache.
Cache reduces load, but it also stores lies faster
Cache is one of the easiest tools to add and one of the easiest tools to misuse.
A cache helps when the same data gets requested repeatedly. Product pages, category results, top products, and common searches are good candidates because many users ask for the same information.
For example:
GET /products/123
GET /search/products?q=iphone
GET /categories/shoes/products
GET /products/top-sellingIf these endpoints hit the database every time, the system wastes work. A cache turns repeated reads into cheap reads.
The basic flow looks like this:
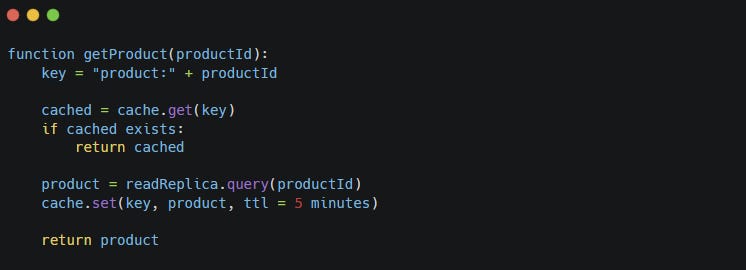
Simple. Until the product changes.
Imagine an admin updates a product price from $10 to $12.
The database commit succeeds. The primary has the correct value. But the cache still holds the old product response.
Now the product page says $10.
Checkout says $12.
The database worked. The cache worked. The system failed.
That is the part many engineers learn the hard way: cache doesn’t just make reads faster. It also makes stale data faster.
Sometimes stale data is acceptable. Sometimes it breaks user trust.
So cache needs rules.
You can use short TTLs for data that changes often. You can invalidate cache entries after writes. You can version cache keys. You can bypass cache for critical flows. You can separate display data from transactional data.
But TTL is not free.
A short TTL reduces the stale-data window, but it increases database load because more requests miss the cache.
A long TTL protects the database better, but it lets stale data live longer.
That is why TTL should be a safety net, not the main correctness mechanism.
For product updates, you usually choose between invalidating the cache on write or updating the cached value on write.
Invalidation is simpler when multiple views depend on the same product data. Updating the cache directly can reduce misses, but it increases the chance that the database and cache drift if the write path gets complicated.
The worst option is caching everything because the system feels slow.
Cache should support the access pattern. It should not hide the fact that nobody understands it.
And once cache enters the system, writes become more than database writes.
Writes need a correctness path
In a read-heavy system, engineers often spend most of their attention on reads because that is where traffic hurts.
But writes still control truth.
A product update should then follow a safer path:

This path has more responsibility than the read path.
It needs to answer questions like:
Did the write commit?
Did two users update the same product at the same time?
Should the cache be deleted or refreshed?
What happens if cache invalidation fails?
How long until replicas catch up?
What should users see during that window?
Those questions matter more than the diagram.
Here is the realistic failure:
1. User updates product price from $10 to $12.
2. Primary database commits the update.
3. Cache invalidation fails.
4. Product page still shows $10.
5. Checkout reads the primary and charges $12.
6. User sees one price and pays another.This is not a database problem.
It is a system design problem.
The write path changed truth, but the read path continued serving an old version of the truth.
A practical default is to separate display reads from decision reads.
The product page can use cache and replicas because it optimizes for speed. If the price is stale for a short window, the system can tolerate it as long as checkout corrects it.
Checkout should not trust cached price or stale inventory.
Checkout should read the latest price and inventory from the primary database, or from a consistency path designed for transactional decisions.
That gives you this rule:

Then handle cache invalidation as part of the write flow.
When a product changes, do not only update the primary database and hope the cache catches up. Write the product change and an invalidation event in the same database transaction.
That is the outbox pattern:
1. Update product in primary DB
2. Insert ProductUpdated event into outbox table in the same transaction
3. Background worker publishes the event
4. Cache consumer invalidates product:{id}
5. Read replicas eventually catch upThis does not make the system perfectly consistent everywhere.
It makes the failure mode explicit.
If publishing the event fails, the event still exists in the outbox table and can be retried. If cache invalidation is delayed, the TTL still provides a backup. If replicas lag, critical flows like checkout bypass them.
The consumer also needs to be idempotent because retries can publish the same invalidation event more than once. Cache invalidation should tolerate duplicates. Deleting product:{id} twice should produce the same final state as deleting it once.
Now the design has clear rules:
Fast reads can use cache and replicas.
Transactional decisions use the primary or a stronger consistency path.
Writes create invalidation events reliably.
Cache TTL acts as a safety net, not the main correctness mechanism.
The exact tuning depends on the business, but this pattern gives the system a sane default.
Scale reads for volume.
Design writes for correctness.
Connect them with a reliable invalidation path.
Now the full architecture becomes easier to reason about.
The full design is a set of choices, not a shopping list
Now, a better architecture for the e-commerce example might look like this:
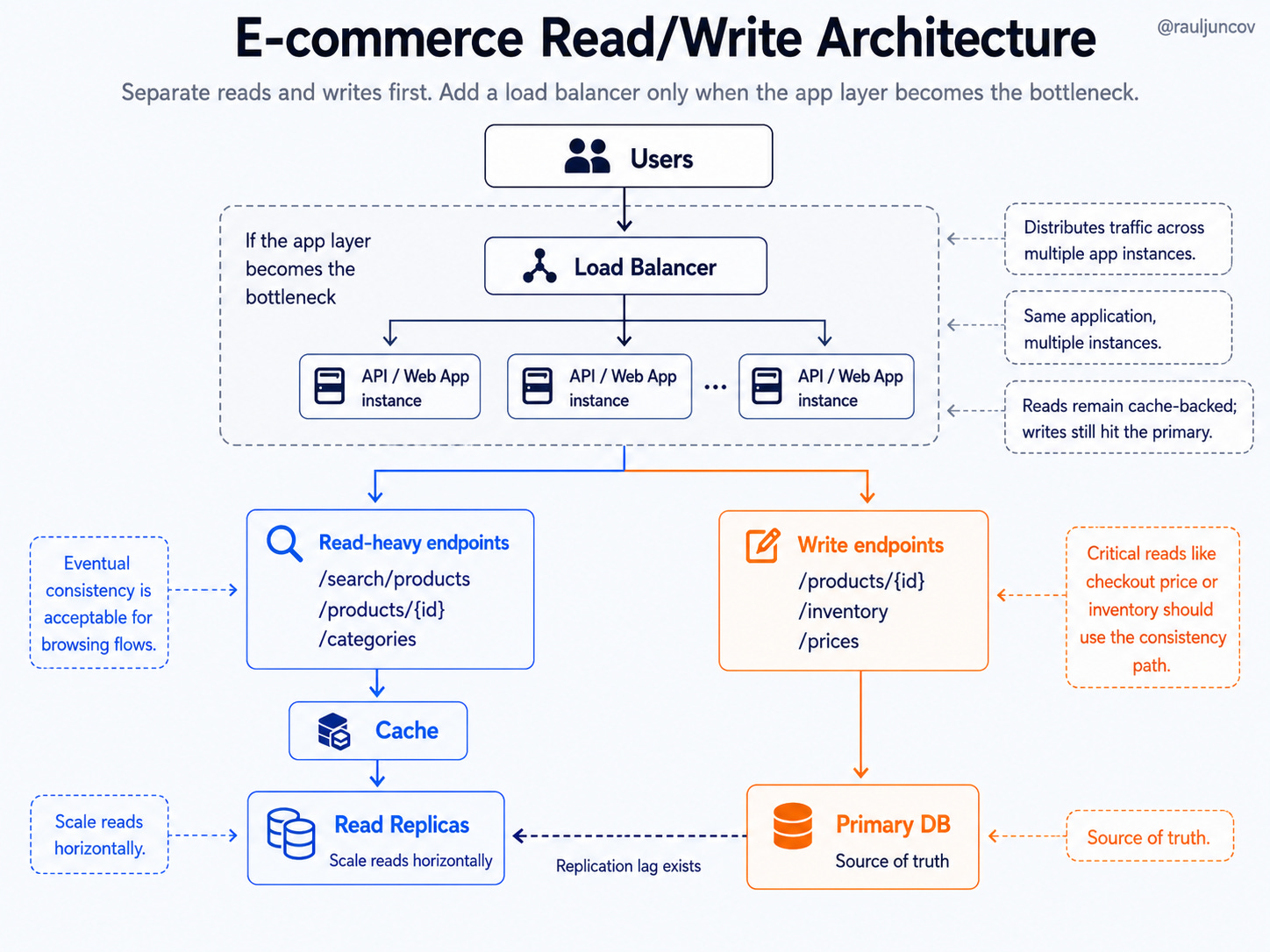
This design makes a few intentional choices.
The read path handles volume through cache and replicas. The write path protects the source of truth through the primary database. The system accepts eventual consistency for reads that can tolerate it. Critical reads, like checkout price or inventory confirmation, use a safer path.
That is the difference between architecture and tool collecting.
A tool-collecting mindset says:
“We use Redis, replicas, and a load balancer.”
An architecture thinker says:
“Product browsing can be stale for a short period, so it uses cache and replicas. Checkout cannot trust stale price or inventory, so it reads from the consistency path.”
That second sentence is system design.
It explains the trade-off.
It tells future engineers why the system works this way.
It prevents someone from “optimizing” the wrong thing six months later.
Good design is not just what components you use. Good design explains why each component exists.
And the best way to explain that is to connect every component back to the hot path.
The realistic trade-offs
This architecture helps, but it does not remove complexity.
It moves complexity into places you need to manage.
Read replicas reduce pressure on the primary database, but they introduce replication lag. Cache reduces repeated database work, but it introduces stale reads and invalidation problems. Splitting read and write paths improves scalability, but it creates more routing decisions and more edge cases.
That does not make the design bad.
It makes the design honest.
Every scaling pattern has a bill.
The question is whether you pay that bill for the part of the system that actually needs it.
Adding cache to product pages probably makes sense if the same products get viewed thousands of times per minute. Adding cache to low-traffic admin pages probably adds complexity without much benefit.
Using read replicas for search and browsing probably makes sense. Using replicas for checkout confirmation may create consistency bugs.
Separating product reads from product writes probably helps when reads dominate traffic. Splitting everything into separate services too early may just create distributed debugging for a problem one database could have handled.
That is why “best practices” are dangerous without context.
Redis is not a strategy.
Read replicas are not a strategy.
Microservices are not a strategy.
The strategy is understanding the pressure in the system and spending complexity only where it buys you something.
So before you scale, measure the hot path.
What to measure before changing the architecture
A hot path should not come from vibes.
It should come from production signals.
You want to answer practical questions:
Which endpoints receive the most traffic?
Which queries consume the most database time?
Which flows slow down during spikes?
Which reads can tolerate stale data?
Which reads require fresh data?
Which operations directly affect revenue or trust?
A simple table can turn “we feel slow” into concrete design signals.
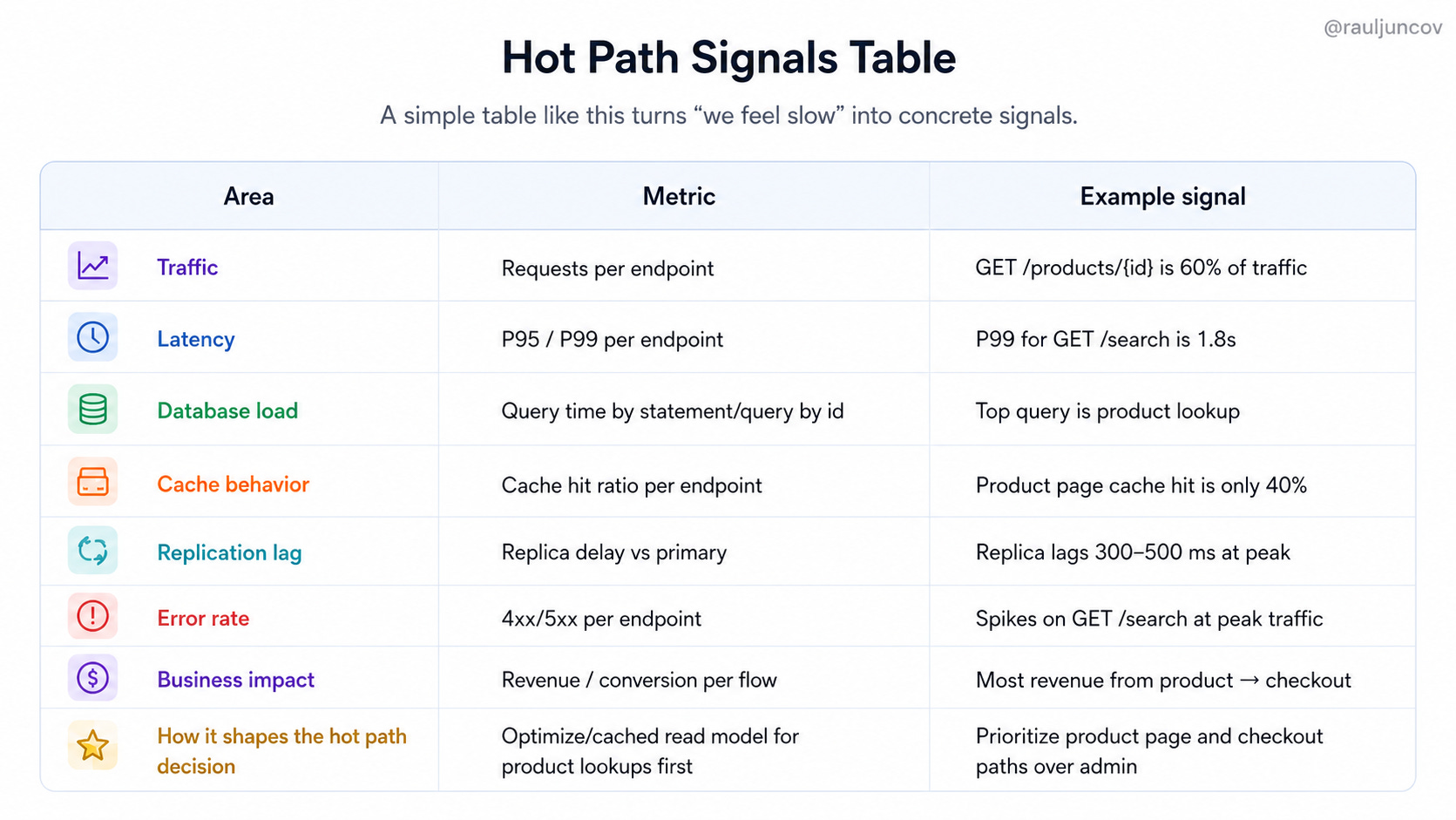
The table gives you a better conversation.
Instead of saying, “the database is slow,” you can say, “product lookups dominate query time, product pages receive most of the traffic, and the cache hit ratio is only 40%.”
That points to a specific design decision: improve the read path for product pages before touching unrelated parts of the system.
The same logic applies to consistency.
If replica lag shows up during peak traffic, checkout should not depend on replica reads. Product browsing can usually use the fast path through cache and replicas. Checkout needs the correctness path because it makes transactional decisions using price and inventory.
Once the hot path is clear, classify endpoints by traffic, freshness, and scaling strategy.
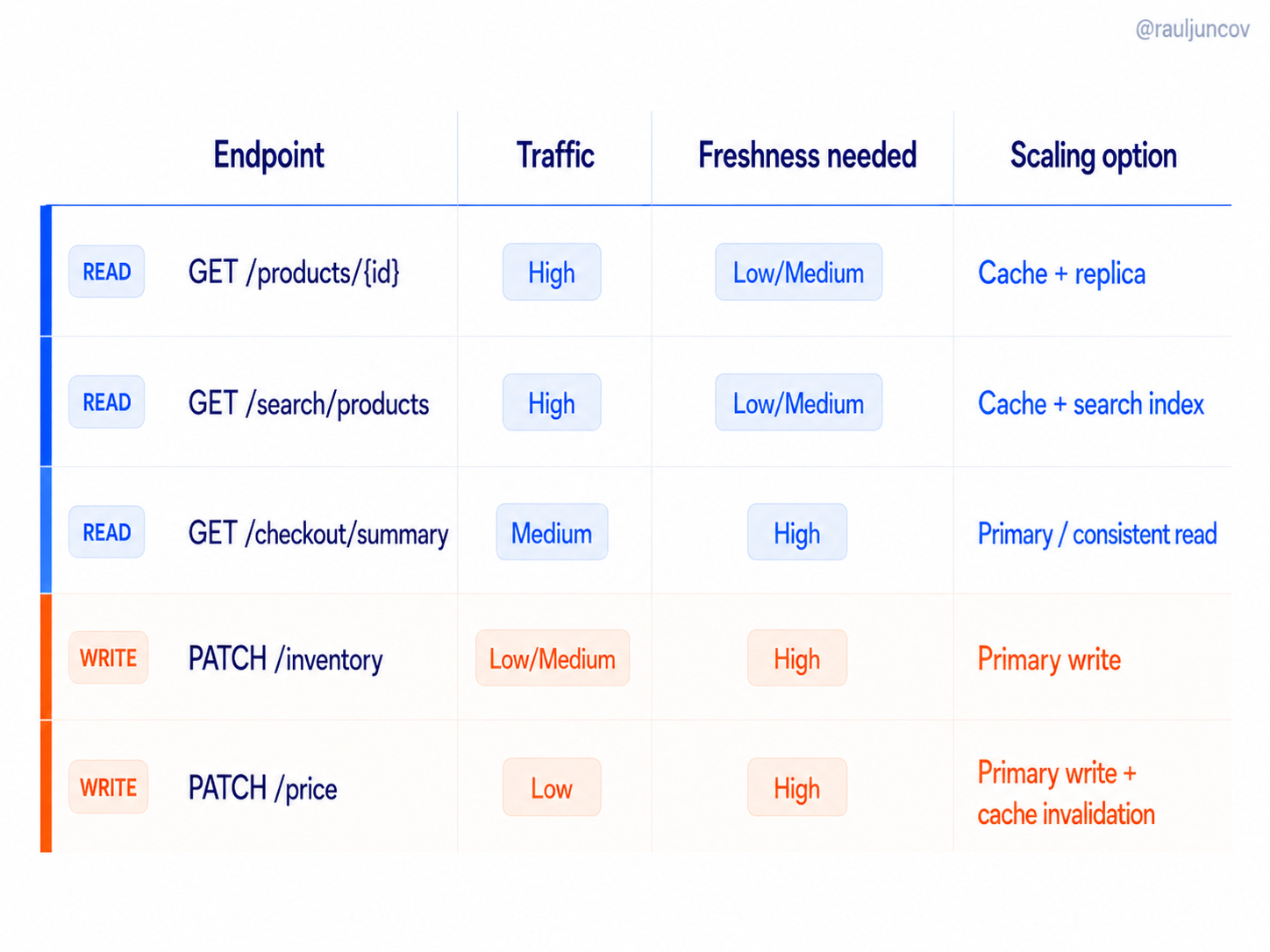
The rule is not “all reads go to replicas.”
The rule is:
Display reads can use the fast path.
Decision reads use the correctness path.
This table does more for system design than a random technology debate.
It shows where the system is hot.
It shows where correctness matters.
It shows where eventual consistency is acceptable.
It turns architecture from opinion into a set of trade-offs.
And once you can describe the trade-offs, the design becomes much easier to defend.
The main lesson
The fastest way to over-engineer a system is to scale everything before knowing what is actually hot.
The fastest way to under-engineer a system is to ignore the path users hit all day.
Good system design lives between those two mistakes.
You find the hot path.
You understand the access pattern.
You separate reads from writes when their needs differ.
You add cache where repeated reads hurt.
You use replicas where stale reads are acceptable.
You protect the write path because it owns truth.
That is the practical version of scaling.
Not “add Redis.”
Not “use microservices.”
Not “throw replicas at the database.”
The real rule is simpler:
You do not scale the whole system. You scale what is hot.
Until next time,
— Raul
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a paid subscriber.
Explained in detail thanks for sharing
I have read a lot of system design articles but this one is very clear explanation of everything , how should you approach a decision. This article is very very good.