
A good System Design is not about getting more instances running.
The Cloud changed how we use infrastructure, making it more accessible and available. But, it is also easier to spin instances to solve performance problems.
Thank you to our sponsors who keep this newsletter free:
Multiplayer auto-documents your system, from the high-level logical architecture down to the individual components, APIs, dependencies, and environments. Perfect for teams looking to streamline system design and documentation management without the manual overhead.
Great developers know that a good system design is also about how you distribute and balance your load.
Let's examine an online registration system during a major event, which often faces extreme traffic spikes.
We'll break down the solution into three main components:
An API
A Database
And a Notification Service

Initial Scaling Strategy
The first instinct might be to scale the API; we can do this easily on the cloud.
And, sure, that will work for some time, but it has two problems:
Scaling does not happen magically; it requires time.
Once you have 10 instances, those will transfer the stress to the other two services, especially the Database.
Database Scaling Challenges
Well, you might think, I can scale the DB, too. But trust me, vertical scaling is expensive.
And, if you choose horizontal scaling, you will introduce complexities like sharding and eventual consistency. This brings up the CAP theorem, which states that a distributed data store can only provide two out of the following three guarantees:
Consistency
Availability
Partition Tolerance
Managing these trade-offs can be complicated and might not always be the best immediate solution.

What else can we do? Load Distribution with Queues
One solution is adding something in the middle, designed to handle all that load and process it at the right moment in the right order.
A Queue is the perfect candidate.
When a user makes a registration request, it's sent to a Queue.
The queue makes sure to process the request without overloading the system.
There are four main benefits:
Producers (senders) and consumers (receivers) don't have to send and receive messages at the same time.
You will have a Dead Letter queue where Azure saves the failed messages.
Duplicate detection
The queue acts as a critical buffer, smoothing out demand spikes and allowing the system to process requests.
You also need a Processor Deploy an Azure Function to poll the queue and process booking requests.
Azure Functions can scale based on demand, making it efficient for handling variable loads without manual intervention.
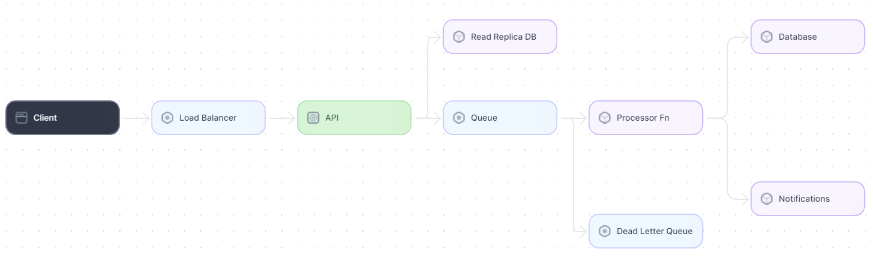
One more thing: Let’s also help the database
The database stores all the registration information, and it must handle many write operations efficiently, as well as thousands of people trying to access the event information.
Separate reading and writing might be a good improvement. To speed things up, we could introduce read replicas to handle read operations separately.
Now, you can have those 10, 20, or 30 instances of your API writing messages to the queue without worrying about overwhelming your DB or Notification service.
A good System Design requires distributing and buffering the load in a smart way.
System Design Classroom is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Articles I enjoyed this week
Should You Use Sticky Sessions? by Saurabh Dashora
How SoundCloud scaled its Architecture using BFF and Value-Added Services? by Petar Ivanov
System Design: What is Availability? by Ashish Pratap Singh
How a Single Line of Code Brought Down a Billion Dollar Rocket by Dr Milan Milanović
Thank you for reading System Design Classroom. If you like this post, Share it with your friends!
The so-called design of a high-concurrency system is to design a system that, while ensuring overall availability, can handle a high volume of concurrent user requests and withstand significant traffic impacts.
To design a high-concurrency system, we need to address some common system bottleneck issues, such as insufficient memory, lack of disk space, insufficient number of connections, and inadequate network bandwidth, to cope with sudden traffic peaks.
There are 15 aspects that can be optimized:
1. Divide and conquer, horizontal scaling
2. Microservices decomposition (system splitting)
3. Database sharding
4. Pooling technology
5. Master-slave separation
6. Use of caching
7. CDN to accelerate access to static resources
8. Message queues to flatten peaks
9. Elasticsearch
10. Downgrading and circuit breaking
11. Rate limiting
12. Asynchrony
13. Regular optimization
14. Stress testing to identify system bottlenecks
15. Responding to sudden traffic peaks: scaling up + traffic switching
Queues are really handy in a lot of use cases concerning the handling of more work.
Nice explanation Raul and some cool diagrams to go along.
Thanks for the mention as well! Much appreciated.